论文笔记Understanding the Idiosyncrasies of Real Persistent Memory
Posted Anyanyamy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记Understanding the Idiosyncrasies of Real Persistent Memory相关的知识,希望对你有一定的参考价值。
Abstract
DCPMM出来之后很多学者开始评估PM。早期的评估结果显示DCPMM的表现是nuanced,idiosyncratic 有细微差别、怪异的。有些设计方案所依赖的性能假设不正确。一些怪异的性能表现与存储技术3D-XPoint和内部架构相关。而其他的STT-RAM, ReRAM之类的技术未来才会商用。目前的评估没有对PM的怪异表现进行理解和分类:DCPMM和其他技术相比有什么特征。因此需要对PM技术的内部架构进行研究。
本文使用PMIdioBench来对真实DCPMM做测评,指导NUMA系统的数据存放data placement;然后考虑具体的PM特性,指导使用eADR或者ADR-enabled PM系统上lock-free数据结构的设计。
Introduction
近年来基于PM的DB和存储系统设计很火:transactional abstractions、持久化数据结构、文件/KV 数据库。大部分工作是模拟PM,很少的使用真实PM。现在DCPMM出来了,学者对其进行评估,发现一些奇怪的特性,基于模拟PM设计的一些假设其实是错误的。本文的动机:Are DCPMM characteristics and guidelines applicable to other PMEM technologies?
本文发现DCPMM有些特征是与内部架构和存储技术相关的,不能应用到其他存储技术上,为了寻找哪些技术是可以用于其他存储类型的,本文进行了研究。
本文找出特定PM特征的根源root causes和影响程度。通过分析DCPMM和DRAM/内部硬件counter,来找出root cause。然后case study指导DB存储系统设计:1. MongoDB NUMA系统中如何最大化PM容量利用 2. ADR/eADR下的ring buffer+linkedlist设计。分析出之前lock-free数据结构设计的隐患。
最重要的发现:PM的怪异现象是因为PM在系统中的组织形式,而不是因为PM技术本身。贡献有:
1. PMIdioBench:定量分析PM特征
2. 对PM的特征进行分类
3. MongoDB的PM存储引擎case study
4. ring buffer/linkedlist的case study
5. 提出一些存储系统设计建议
PM background
PM系统架构:NUMA CPU,每个CPU有local registers,store buffers和caches。LLC是所有core共享。每个CPU有自己的DRAM/PMEM,通过mesh interconnect连接。
有2种持久化模式:1. ADR:PMEM和WPQ写队列在persistence domain。掉电时所有到达ADR domain的存储会flush进PMEM,而CPU cache中的data会丢失。2. eADR:掉电时CPU cache中的data也会flush进PMEM,但CPU register和store buffer里的会丢失。
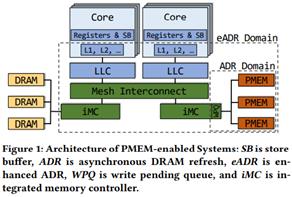
DCPMM:使用ADR,但也可也用于测试eADR的系统。CPU memory controller与DCPMM通过DDR-T协议交流,通常64B cacheline粒度,与DDR4接口相同,但支持asynchronous command and data timing. 访问3D-XPoint介质的粒度是256B XPLine,使用read-modify-write操作方式来存储数据,导致写放大。XPLine也代表ECC错误矫正码单元,访问一行XPLine通过硬件ECC来保护。与SSD一样,DCPMM使用逻辑寻址wear-leveling进行磨损均衡,使用address indirection table AIT来完成地址转换。DCPMM使用内部cache XPBuffer+XPPrefetcher来缓存读写,这个cache用作write-combining buffer合并写,到达XPBuffer的是持久化的。

PROPOSED MODUS OPERANDI 提出的工作方法
表1中列出DCPMM的一些特征,如果root cause在其他类型的PMEM中不存在则该特征不可用于其他PMEM。表2列出考虑的PMEM类型。为了找出root cause:
1. 在DRAM中也做实验,如果也有这种特征,说明root cause是由于硬件导致的。而在图2中每个部分和微架构micro-architectural numbers可以进行验证。
2. 查看DCPMM硬件counter,找到哪个内部组件导致了这种特性
本文只关注与常识相反的或者对性能影响最大的特性,不关心CPU架构。


Metrics:
1. EWR effective write ratio:当access granularity不匹配时,写入iMC的bytes数/写入3D XPoint介质的bytes数,写放大的倒数
2. EBR effective bandwidth ratio:平均可达PMEM带宽/峰值带宽。与写放大没有直接关系,只与achieved bandwidth有关
3. RWR read-write ratio:读bytes/写bytes。
EWR和EBR用于识别sub-optimal access size, pattern, concurrency。RWR用于确定workload type as read or update heavy
Terminology:
nt-store:优化的非暂时store操作,绕过cache。
p-store:常规存储 + cacheline flush + mfence,nt-store + store fence,持久化存储
persistence barrier:cacheline flush + store fence
本文使用cache-line instructions使cacheline失效,而不是写回指令(intel没完全实现)
3.1 PMIdioBench
在不同场景、线程数、access size下衡量PM访问的latency/bandwidth,可以禁止cache prefetching。两个工具:1. 检查硬件counter/展示EWR,EBR,RWR指标 2. 产生benchmark trace提取出flame graph。可用于将来PMEM的评估
限制:这个工具用于观察指定的一些指标,需要访问hardware counter in granularity of cache-lines
4. IDIOSYNCRASY CATEGORIZATION
4.1 Asymmetric load/p-store latency 非对称load/p-store延迟
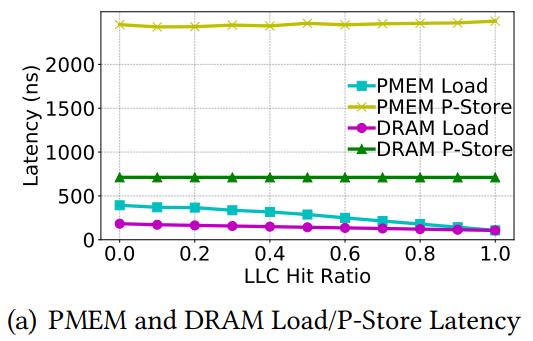
考虑PM延迟时需要考虑cache的影响,之前的工作只考虑了直接访问PMEM的延迟,而没反映应用真正的延迟。
在PM上分配一块与LLC大小相同的区域,使用CPU load预热一部分LLC,控制LLC hit ratio。以下发现:
1. p-store延迟:PMEM 3.4x worse than DRAM load延迟:PMEM 2.2x worse than DRAM
原因:PMEM的写带宽很低
2. Load指令:
当所有访问directly go to memory:PMEM和DRAM load差异大。然而随着LLC hit ratio变大,这个差距缩小
原因:由于越来越多的load由cache提供,latency降低,趋近于cache延迟
3. Store指令:
由cache flush latency决定,与cache hit rate无关。当hit rate=1,DRAM的load/p-store相差6.7x,PMEM的load/p-store相差23.3x。这个趋势是generalizable
真实use case中,大部分PMEM访问cache hits,p-store比load慢得多。
因此,尽量减少不必要的p-store,把data保存在cache里是有利的
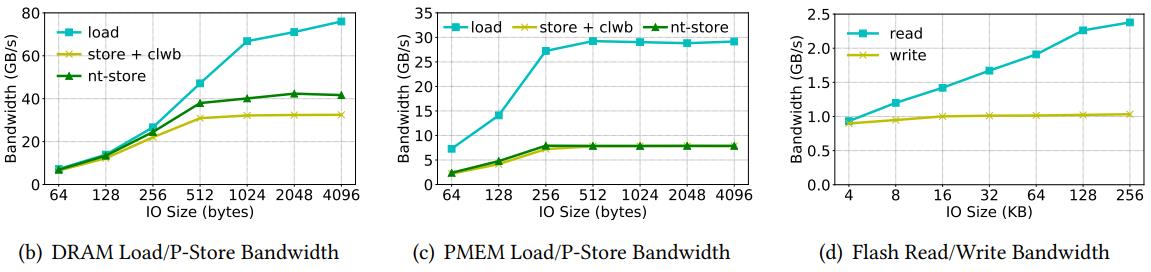
4.2 Asymmetric load/p-store bandwidth
1. Load带宽:PMEM是2.5x worse than DRAM store带宽:PMEM是5.2x worse DRAM
因为在flash memory中写延迟通常比读延迟高。
Flash的读写带宽分别是DRAM的1.7x 2.3x worse
但是PMEM的非对称性更明显:contention at the iMC
由于iMC中的处理导致这种非对称特别明显。
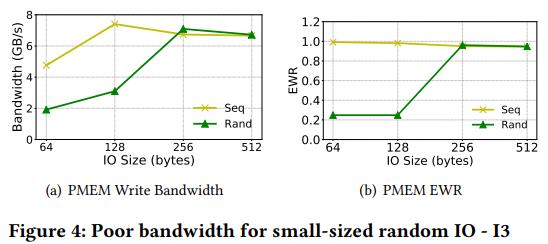
4.3 Poor bandwidth for small-sized random IO
衡量PM上small-sized 64-512B的写。
4a:连续IO带宽基本不变,随机IO在64B和128B时带宽很低。
原因:256B ECC block,小于这个尺寸的会造成写放大,降低了带宽。对顺序IO,DCPMM内部使用写合并技术,把连续的小写放入一个ECC block,带宽影响不大
4b:在64B和128B时写放大严重,大于256B后没有部分XPLine写
这个随机IO降低带宽是可应用于其他存储设备的。
4.4 Poor p-store bandwidth on remote NUMA
图5显示local和remote的带宽差距。由于remote需要经过mesh interconnect,降低了带宽。高并发和大IO也在remote上带宽更低。因为inter-socket的带宽本身就更低。顺序IO remote的带宽降低更严重,因为不同线程共享的UPI lane的访问方式是random,而PM的XPPrefetcher更适用于顺序IO。
这种remote带宽降低的特性是其他PM也存在的,对于PM使用内部cache来做预取的性能降低更严重。

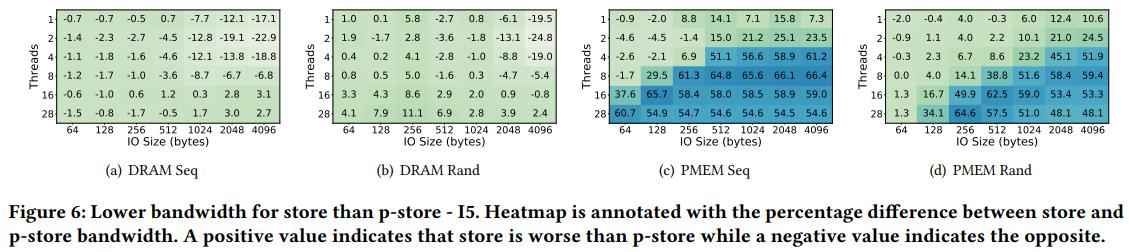
4.5 Lower bandwidth for store than p-store
衡量带cflush的store与普通store,只对PMEM差距很大,DRAM没有很大。
原因:cache架构对于普通store改变写回机制,是不确定的随机形式 cache hierarchy changing the cache write-back pattern to a non-deterministic random pattern for regular stores. Cache替换算法是异步工作的,与应用IO模式独立。因此,cache会把顺序CPU存储转成PMEM的随机写。
PMEM的随机写带宽更低,因为XPPrefetcher。而DRAM不存在这个问题。
因此认为这种不一致是由于内部使用prefetcher的cache造成。在eADR模式中,不需要flush cache因为已经在persistence domain中,不flush可以减少延迟。
not flushing the cache can in fact be detrimental to bandwidth when using PMEM with a built-in prefetcher 不刷新cache对于使用prefetcher的PMEM会降低带宽
4.6 Sequential IO faster than random IO
顺序IO/随机IO的DRAM和PMEM的带宽不一样,但flash的没影响,因为flash的带宽很快饱和,与访问模式无关。PMEM更明显,分析XPBuffer的读hit ratio,对于随机IO降低了19%,因为XPBuffer中的预取cache是顺序IO友好的。这种特征在DRAM中也有,因为CPU prefetcher。PMEM更严重,因为有CPU prefetcher + XP Prefetcher。这种特性也适用于其他PM,只是对于有内部prefetcher的,顺序与随机IO的差距更明显。

4.7 P-stores are read-modify-write transactions
验证XPBuffer的特征。重复写non-temporal到相同的XPLine,衡量EWR和RWR,结果都接近1. 说明DCPMM会立刻写XPLine到介质上,即使XPBuffer不满。即使写完整的256B XPLine,写也会被拆成64B cache-line 因为DDR-T使用cacheline粒度。导致每个内部存储都需要read-modify-write事务。XPBuffer没有有效使用。
提升:
1. 对于具有高时间局部性 temporal locality的workload,在XPBuffer中保留完整的写line可以提高命中率
2. controller发现往同一XPLine的连续写后,不应该从介质读数据,防止read-modify-writes。
5 CASE STUDY – NUMA-AWARE DATA PLACEMENT WITH MONGODB
PMSE持久化内存存储引擎,只考虑数据完全存在local或remote NUMA PMEM上。目的是最小化性能影响performance impact而最大化空间利用率capacity utilization。通常来说,把所有数据结构放在local上是最优的配置,然后分布在其他NUMA节点上能最大化空间利用率和性能分离performance isolation。找到最优配置后检查low-level PMEM counters。最终设计能应用到其他存储系统的guidelines
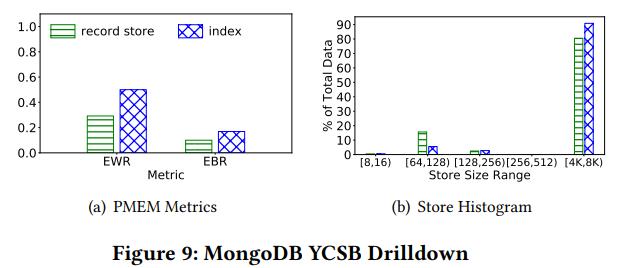
PMSE设计主要包括2种持久化结构:b+树和record store (RS),可以直接持久化并保持一致性。PMSE依赖PMDK的事务绑定来保证崩溃一致性。PMSE在node 0, client在node 1。4种配置:RS和index分布在0和1。Local的访问比remote快。RS的访问是最重要的,影响尾延迟。分析底层的PMEM counter,统计EWR和EBR,值越高说明PMEM使用越充分。

RS的两个指标值都很低,说明其访问模式次优。分析workload A的访问模式,大部分数据结构的粒度都在4-8KB。然而RS的粒度在64-128B,因为更新其memory allocator需要更小的存储?EBR和EWR可以一定程度反映是否该把data放在local。EWR不是所有PM适用,所以推荐用EBR。最终建议:把高EBR的数据结构放在remote节点上。
6. CASE STUDY – DESIGNING PERSISTENT LOCK-FREE DATA STRUCTURES
首先讨论设计持久化lock-free数据结构的挑战,再介绍两种数据结构的设计。分析在eADR和ADR上的设计不同之处,针对ADR的设计不一定能应用到eADR上,需要考虑workload IO模式和持久化mode。
6.1 design techniques
一般提供原子性和隔离保证isolation guarantees需要适用复杂的事务系统,使用锁来做访问互斥。事务抽象transactional abstractions使用redo/undo logging内部也是用到锁。
1. Libpmemobj不使用锁但是依赖每个线程的buffer来保存事务状态。
2. Dirty-bit design中数据更新后被标记为dirty,线程发现dirty置位后set flush data to PMEM,只有提交后的数据才读。
3. 使用每个线程的scratch buffer来做日志或状态追溯,因为每个线程有独立的内存区域,可以lock-free
4. 对于eADR,依赖原子化操作即可保证一致性,当然也可能需要其他信息来识别数据结构状态,以从故障中恢复。
本章设计2个DB中经常使用的lock-free持久化数据结构:多生产者、消费者ring buffer和并发链表。针对ADR设计的,只需要把barrier替换成store fences即可,本章重点在于对比不同的设计策略。
6.2 lock-free linkedlist
考虑排序链表,其中的值可以是任意数据结构,设计扩展自Harris,支持插入、删除、包含操作。原版的设计使用CAS来保证lock free,逻辑删除会把node标记为removed,设置node指针。针对ADR设计的叫TLog,针对eADR设计的叫Log-free
TLog:添加持久化barrier来保证durability。新node在加入list之前会flush into PMEM,对node下一指针的修改也会flush。使用per-thread scratch buffer来做micro-logging,保证原子写。初始化list操作之前,每个thread在buffer中存储操作类型和参数,标记为in-flight。当操作完成,operation标记为completed。恢复时检查buffer,redone in-flight操作,恢复是idempotent幂等的。
Log-free:在eADR中,易失性cache在persistence domain中,增加store fence。还需要防止PMEM内存泄露以及PMEM地址空间relocation重定向。
Memory allocator:包括一定数量的由易失性lock-free bitmap索引的PMEM slab。Bitmap依赖原子性的fetch-and-and/or指令来保持lock free。内存回收算法使用epoch-based reclamation EBR来保证正确性、进行垃圾回收。
为了防止内存泄露,把bitmap放在DRAM中,当恢复时重建bitmap状态,遍历链表设置标记即可,不需要事务支持。为了保证PMEM的地址空间relocation,使用relative pointers and pointer swizzling。
TLog的设计中,node从PMEM slab分配,使用node offset而不是pointer。2个线程操作链表,线程1完成了插入操作,设置in-flight标识为false,线程2还没完成删除操作,in-flight为true。如果crash发生,线程2的操作通过log进行恢复。Lock-free设计一样,只是不需要每个线程的日志。

评估:与最新的SOFT和Link-free进行对比,在不同的更新比例、值范围上来模拟heavy load 场景。图11中比较不同值范围的total总体吞吐量,TLog更好。Link-free与TLog类似,但是没有用per-thread logging来保证原子写,而是在查找返回之前需要把node flush一下,因此搜索延迟增大。SOFT是Link-free的优化版,不flush node pointer,使用valid flag per node来表示node是否是list中的部分,在恢复时所有PMEM节点扫描然后重建list。SOFT减少了barrier使用,插入和删除很快,但是查找时还需要flush node,增加了延迟。TLog使用micro-logging保证原子性,不依赖做barrier的查找操作,所以查询快,但是插入和删除较慢。当更新操作的比例增加时,TLog的性能趋近于Link-free和SOFT。
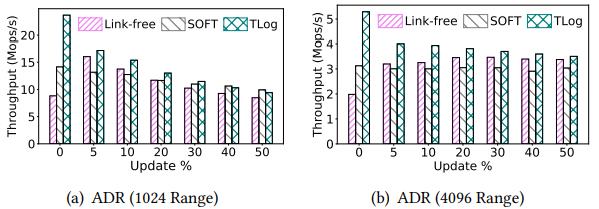
在eADR下,TLog表现更好,因为eADR不需要cflush,插入和删除没有额外的持久化成本。Log-free在两种情况下都好于TLog,Log-free避免了micro-logging,但其设计的提升很少,因为大部分时间花在查询操作而不是持久化barrier上。

使用flame graph对每个函数进行time-wise breakdown,发现list遍历所花时间最多,优化遍历比优化持久化操作更重要,而SOFT和Link-free都在专注于优化持久化。

6.3 Lock-free Ring Buffer
基于Krizhanovsky设计ring buffer。
Volatile Design:使用per-thread头尾指针来保证lock freedom。使用fetch-and-add指令执行push/pop时增加global头尾指针,把旧数据保存在local头尾指针中。Local指针表示queue slot,在线程操作slot之前需要确保安全。使用global last tail/head来记录最早的还未完成的push/pop。每次操作会遍历所有local头尾指针,计算出全局头尾指针,保证不会push正在pop的slot。当操作完成后,local头尾指针设置为INT_MAX,允许其他线程操作。
Persistent Design:针对ADR设计基于事务的TX,针对eADR设计不需要事务的TX-free。Ring buffer, global head/tail pointers, thread-local pointer都存在PMEM中。而last head/tail pointer存在DRAM,因为可以基于thread-local pointer计算出来。增加thread-local pointer push/pop position来记录线程操作的slot位置,可以用于崩溃恢复。因为ring buffer大小固定,内存管理很直接,在应用启动时静态分配必要的结构和指针,防止PM内存泄露。使用索引而不是指针来进行地址空间重定位。

图中2个生产者和2个消费者,每个人有自己的buffer,包括了local head/tail, position pointer。Position记录正在操作的slot,恢复时继续操作。
TX Design:使用事务来保证push/pop的critical section的原子性。使用libpmemobj,使用redo/undo logging实现原子写。当恢复时,检查position,使用PMDK的事务底层使用thread-local buffer来存储内部状态,不破坏lock-free特性。
TX-free Design:不用事务,使用store fences。只有1个linearization point,就是设置push/pop position为INT_MAX。
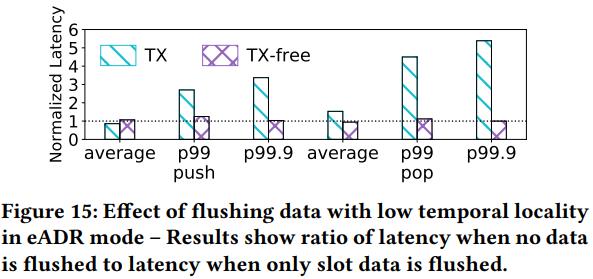
评估:第一个lock-free persistent ring buffer,所以只比较这两个方案,使用不同大小的slot size。Ring buffer里的数据具有低空间局部性,会与其他数据争夺cache空间。Overall, flushing data with low temporal locality is good for lowering latency
6.4 Key Insights
1. 事务代价高,PM尽量少用事务。可以用per-thread logging、dirty-bit设计。前者适合read-heavy,后者适合update-heavy,有时候无法避免事务。
2. 基于ADR的设计不一定适合eADR。为了获得eADR最优性能,尽量立刻持久化所有可见操作。更适合update-heavy
7. Discussion
7.1 ISA Support
持久化指令分为3类:1. Clflush 2. Clwb写回 3. Nt-store
1,2需要数据在cache中,3绕过cache。
1使得cache中所有行失效,把dirty data写到PM
2 同样功能,但是不会使所有cache行失效,性能高一点,不需要把cache行重新读回来,增加了cache命中率
3 带宽更高,但延迟也更高。适用于大量IO或者具有低时间局部性的数据。
总的来说,2应该更好,1只应该在flushed data不会再次被读时使用,因为1降低了cache命中率,影响了性能
Clwb写回指令是ISA的一部分,但是目前的行为与cflush一样,因此没法测其性能提升,当clwb可行时可以用于后续研究。
7.2 Persistence Mode
在eADR中cache不需要flush到PM中,持久化的成本更低。但是实验发现DCPMM中不flush cache降低了带宽、增加了时延。特别是在具有低时间局部性的数据没有flush时,因此,即使使用eADR,有些数据也应该被flush,从而达到较好性能。这个趋势大概可以适用于很多DCPMM。
eADR使得程序减少事务的使用,对于持久化barrier占很多时间的应用,优化系统设计可以提升性能。不过对于read heavy的情况提升不大,因为barrier占的时间不多。而ring buffer是update heavy,可以提升明显。
7.3 Internal Cache
DCPMM使用内部cache来缓存PM读写,实验显示这是造成许多现象的根源。DCPMM中有2个cache,1个CPU cache,1个DCPMM内部XPBuffer使用的预取XPPrefetcher cache用于预取行。XPPrefetcher更适合顺序IO,所以对于随机IO(例如使用store而非p-store,NUMA访问)性能较差。未来的PM如果有prefetcher也会呈现类似的特性。对于时间敏感的IO可以考虑增加自定义预取逻辑,目前不支持,未来可能支持。
7.4 IO Amplification
由于DDR-T协议和3D-XPoint的访问粒度不一样,导致IO放大,降低了带宽利用率。增大访问粒度一定程度能缓解这种情况,预计将来有同样mismatch访问粒度的PM也会有类似表现。因此将来PM的设计要尽量避免这种不一致。
7.5 Recommendations
系统设计建议和不同类型PM的性能影响。
R1:p-store必须要到达PM,所以比load更贵。需要尽量减少不必要的存储。
R2:限制PM并发写的数量能最大化带宽利用率。
R3:使用小IO会降低带宽,需要把多个小IO合并成1个大IO。当小IO无法避免时,使用store+cflush比nt-store更好,其延迟更低。
R4:把具有更高EBR的数据结构放在远端remote节点可以最大化空间利用率。
R5:p-store比常规store的带宽更高,把无关的数据从cache中flush出来比较好。
R6:随机IO比顺序IO性能差,可以使用log、write buffer来把小的随机IO合并成大的顺序IO。
R7:有些方法可以用来防止事务,比如per-thread looging(PMDK中使用)、dirty-bit设计。

8 RELATED WORK
PMEM Evaluation Studies.
很多人已经对DCPMM的底层和系统层特征进行研究,然而这些研究提出的建议只针对DCPMM,本文的工作旨在探究根源,探索其对未来PM的适用性。虽然有些特性其他文献也探究过,但他们主要针对DCPMM。
本文不仅探究这些特征对性能的影响,还找出根源,探索其对于其他类型PM的适用性。即使其他文章说要避免使用NUMA,本文发现把一些数据放在remote节点也能提升内存利用率。提出了新的指标EBR来指导这种数据放置,还可以用于其他PM。
Lock-free Persistent Data Structures.
Lock-free队列:保证崩溃时队列状态一致。
Lock-free durable sets:包括链表、跳跃表、哈希表,通过减少用于一致性保证的persistence barrier来提升性能。
NVC-Hashmap:只在线性化点进行刷新。reduces persistence overhead by only flushing cache-lines at linearization point
PMwCAS:使用多字CAS原语来简化lock-free数据结构设计。
CDDS:使用多版本方法来实现持久化数据结构,避免日志。这些工作都使用模拟PM,只考虑了ADR模式,本工作使用真实PM且考虑不同的持久化模式。
9 CONCLUSION
本文提出了Bench平台用于对真实PM的特征进行分类,探究这些特征的可扩展性。深入做了两个case study,1个探索NUMA上的数据放置,2个探索lock-free数据结构设计。最后给出设计建议。
以上是关于论文笔记Understanding the Idiosyncrasies of Real Persistent Memory的主要内容,如果未能解决你的问题,请参考以下文章