源码阅读(36):Java中线程安全的QueueDeque结构——LinkedBlockingQueue
Posted 说好不能打脸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码阅读(36):Java中线程安全的QueueDeque结构——LinkedBlockingQueue相关的知识,希望对你有一定的参考价值。
(接上文《源码阅读(35):Java中线程安全的Queue、Deque结构——LinkedBlockingQueue(1)》)
3、LinkedBlockingQueue的主要方法
通过上文的讲解,我们清楚了LinkedBlockingQueue队列的内部结构、主要的入队、出队过程。本文承接上文内容,继续讲解LinkedBlockingQueue的主要方法。
3.1、put(E) 方法
put(E) 方法将会在LinkedBlockingQueue队列的尾部添加一个新的数据对象,如果LinkedBlockingQueue队列中已经达到了最大数据容量,则该方法将会被阻塞。put(E)方法的执行逻辑有三个核心点:其一,该方法和LinkedBlockingQueue队列中其它用于添加数据的方法工作原理类似,都必须首先获得putLock操作权限,才能进行实际的添加操作;其二,添加过程的主要逻辑就是调用上文中介绍的enqueue(E)方法。其三,如果添加过程中发现LinkedBlockingQueue队列中已经没有多余的容量保存数据,则通过notFull Condition让当前线程进入parking_waiting状态(就是通俗所称的阻塞状态)。以下是put(E) 方法的代码片段:
public void put(E e) throws InterruptedException
// 将要添加的数据不能为null
if (e == null)
throw new NullPointerException();
final int c;
// 这个新创建的对象,就是将要添加到队列尾部的新的Node对象
// 其中的item属性引用了将添加的新数据对象e
final Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// 计数器一定要使用遵循CAS原则的AtomicInteger
// 主要是因为putLock和takeLock是相对独立的,对此,后文还会进行详细说明
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try
// 如果当前条件成立,说明队列中的数量已经达到最大上限
// 这时不能再添加新的数据对象了,这时通过notFull condition将当前线程进入阻塞状态
while (count.get() == capacity)
notFull.await();
// 使用enqueue()方法进行入队操作,
// 该方法已在之前内容进行详细介绍,这里不再进行赘述
enqueue(node);
// 添加后,获取当前数据的容量计数器的值,然后计数器+1
// 且本次添加完成后,队列中的数据容量依然容纳更多的数据对象
// 则唤醒可能还处于阻塞状态的,有数据添加操作需求的其它线程
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
finally
// 无论本次添加操作是否成功
// 都要释放操作权限
putLock.unlock();
// 如果添加成功前队列中的数据量为0
// 那么当代码运行到这里,通常情况下,队列中都至少有一个数据对象了
// 这时唤醒之前有取数操作需求的消费者线程,解除其阻塞状态
// 这个点后续还要进行介绍,为什么叫“通常情况下”
if (c == 0)
signalNotEmpty();
这里说明以上代码片段中的关键要点:
- count.get() == capacity代码语句:
count是一个AtomicInteger对象,粗看这句代码实际上是有问题的,因为在进入put(E)方法时和在执行count.get()方法调用时,count的值可能发生了变化:这是由于诸如take()、pull()这样的取数方法,导致count对象的计数值发生了变化。但实际上这种变化并不会影响这里的判定目标,因为前者提到的这些计数器变化,都是使数值减少的变化。而可能导致count计数器增加的变化,都存在于诸如put(E)、offer(E)这样的添加方法中,而这些方法全部受到putLock操作权的控制。
- 代码片段最后的“c == 0”判定条件:
在上文的代码片段中,我们标注“c = = 0”这个判定条件的注释时,使用了“通常情况”这个修饰词,这是因为LinkedBlockingQueue队列中数据添加和数据取出是由两个独立的可重入锁进行控制操作权控制的,并且两类操作又共享了同一个AtomicInteger计数器对象。所以在执行“c = = 0”判定时,就可能出现LinkedBlockingQueue队列中实时数据量已经不等于c变量记录的值了。但是同样,这不影响该判定式所要达到的工作目的。
3.2、take() 方法
take()方法将从LinkedBlockingQueue队列头部取出数据对象,但从上文的介绍我们知道,实际上取数操作的Node对象是最接近头节点的第二个Node节点。如果LinkedBlockingQueue队列已经没有可取数的节点时,则调用该方法的线程将被阻塞,直到收到可进行取数操作的通知。
该方法的核心工作点也涉及三点:该方法工作时,必须基于takeLock获得操作权限;其次,取数操作的主要逻辑就是调用上文中介绍的dequeue()方法;最后,如果队列中以无数可取,则当前调用该方法的线程将被阻塞。以下是take()方法的代码片段:
public E take() throws InterruptedException
final E x;
final int c;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
// 基于takeLock成功获取到操作权后,开始执行以下代码
try
// 如果条件成立,说明当前LinkedBlockingQueue队列中没有数据对象可以取出
// 那么当前取数线程进入阻塞状态
while (count.get() == 0)
notEmpty.await();
// 通过dequeue()方法获取LinkedBlockingQueue队列的Node对象
// dequeue()方法上文已经进行了详细介绍,这里不再进行赘述
// 这个x就是将被返回的数据
x = dequeue();
// 获取当前计数器的值,并且 -1
c = count.getAndDecrement();
// 如果取得的计数器值大于1,
// 则通知可能处于阻塞状态的,那些有取数需求的线程,解除阻塞状态
if (c > 1)
notEmpty.signal();
finally
// 无论本次添加操作是否成功
// 都要释放操作权限
takeLock.unlock();
// 如果在取数操作时,获取到的队列数据量计数器的值c,已经达到队列容量的上限
// 这通常说明,在本次取数操作成功后,LinkedBlockingQueue队列至少空闲出来一个位置可以存放新的数据了
// 于是基于putLock,发送通知给可能处于阻塞状态的,有添加数据操作需求的线程,以便解除其阻塞状态。
if (c == capacity)
signalNotFull();
// 最后向调用者返回本次的取数结果
return x;
take()方法和put(E)方法,虽然功能相斥,但是却有类似的工作思路。如下:
-
取数操作和添加操作,都需要获取相应的操作权限,才能进行。它们分别是takeLock对象和putLock对象。
-
取数操作和添加操作,都有核心的操作原理都分别有一个私有方法进行控制,它们分别是dequeue()方法和enqueue(Node)方法。
-
取数操作和添加操作,在操作完成后,都会进行相互通知。例如取数操作完成后,都要通知可能被阻塞的生产者,可以继续进行生产;添加操作完成后,都要通知可能被阻塞的消费者,可以继续进行取数消费。
3.3、iterator迭代器
相对于已介绍过的ArrayBlockingQueue队列,LinkedBlockingQueue队列的迭代器实现要简单许多,但有一个核心要点是相同的,就是要保证在多线程场景下,迭代器能够稳定工作,正常、正确进行遍历。LinkedBlockingQueue队列的迭代器设计充分考虑了LinkedBlockingQueue的多个关键的构造特点(后文将进行总结说明)。
并且基于这些考虑,LinkedBlockingQueue队列的迭代器和ArrayBlockingQueue队列的迭代器类似,都需要在遍历每个数据前,修正迭代器的各定位属性。
3.3.1、LinkedBlockingQueue队列中iterator迭代器的构造函数
首先我们来看一下迭代器Itr的构造函数和主要属性——代码片段很简单,参加如下:
// ......
private class Itr implements Iterator<E>
// 该属性引用下一次执行next()方法时,被遍历的Node节点
// Node holding nextItem
private Node<E> next;
// 该属性引用了下一次执行next()方法时,调用者将获取到的数据对象信息
private E nextItem;
// 该属性引用了之前最后一次(上一次)执行next()方法是,被遍历的Node节点
private Node<E> lastRet;
// 该属性主要使用在迭代器的remove方法中
// 帮助业务逻辑断开lastRet所引用Node的依赖。
private Node<E> ancestor;
// 这是LinkedBlockingQueue的迭代器Itr的构造方法
Itr()
fullyLock();
try
// 代码片段很简单,将LinkedBlockingQueue队列的head.next属性的引用
// 赋值给迭代器的next属性,作为第一次运行next()方法时,next属性的引用Node
// 如果next属性在赋值操作后,不为null,则还需要设置nextItem属性
if ((next = head.next) != null)
nextItem = next.item;
finally
fullyUnlock();
/**
* 通过putLock和takeLock,同时获取到LinkedBlockingQueue的添加和取数的操作权
* Locks to prevent both puts and takes.
*/
void fullyLock()
putLock.lock();
takeLock.lock();
// ......
以上代码片段没有太多需要单独介绍的内容,其主要的工作目标就是为了迭代器实例化后,为第一次调用hasNext()方法或者next()方法,准备正确的数据状态,其操作结果可以用示意图做如下表达:
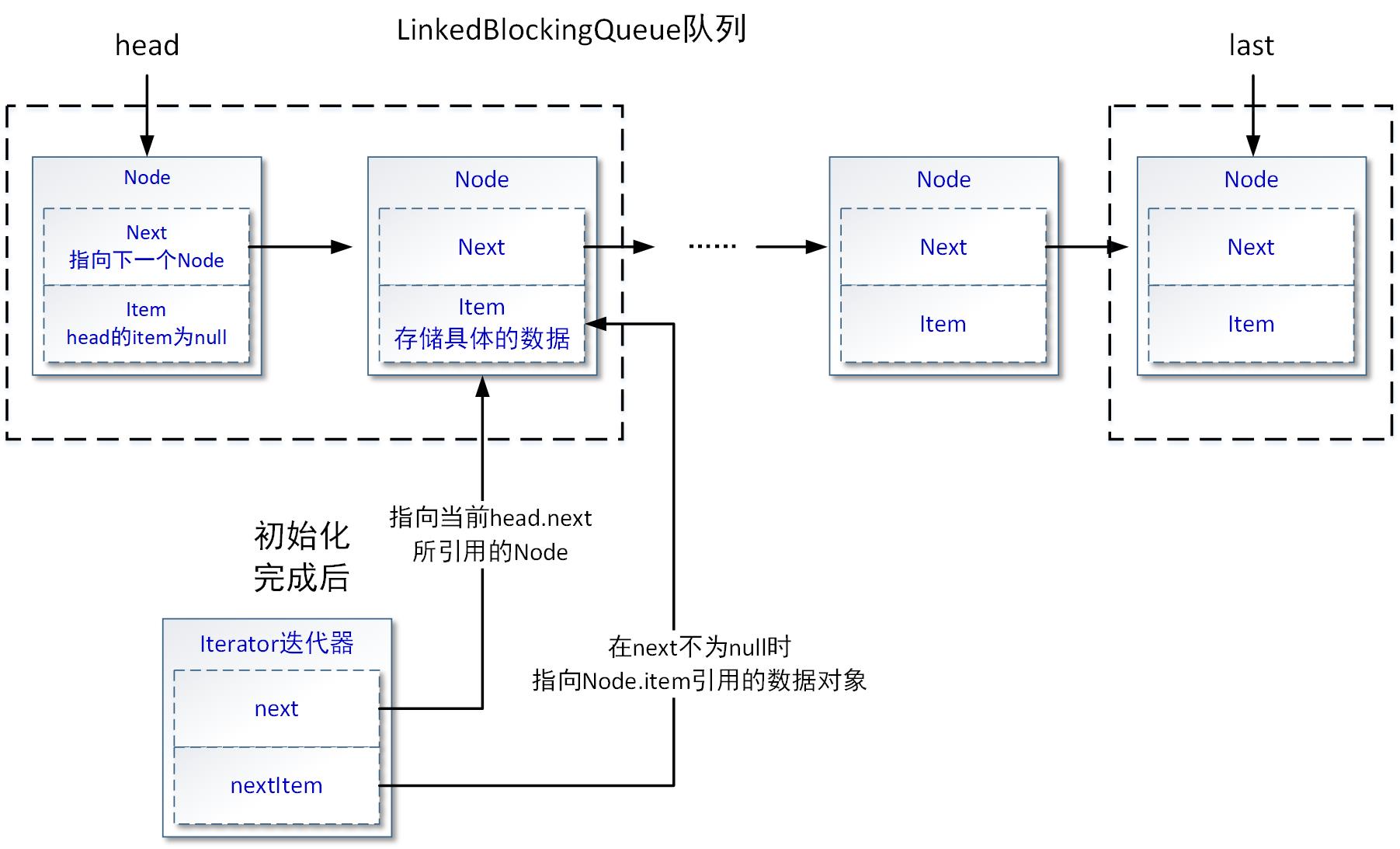
注意,以上示意图只是表达了当LinkedBlockingQueue队列中至少有一个数据对象时(至少head Node节点之后有一个Node节点)的初始化场景。而当LinkedBlockingQueue队列中没有任何数据对象时,Iterator迭代器的next属性和nextItem属性都为null。
3.3.2、iterator迭代器的hasNext()方法和next()方法
hasNext()方法和next()方法两者基本上是进行配合工作的,所以本文在这里同样将两个方法一并进行介绍。以下是相关的代码片段介绍:
// ......
// 该方法判定Node节点是否是一个自引用的节点
// 如果是,则修正p变量的引用到队列的head.next位置
// 实际上就是修正p的引用位置
Node<E> succ(Node<E> p)
if (p == (p = p.next))
p = head.next;
return p;
private class Itr implements Iterator<E>
// ......
// hashNext()判定迭代器是否还有没有遍历的数据对象的依据很简单
// 就是看迭代器的next属性是否为null
public boolean hasNext()
return next != null;
// 每一次调用next()方法,迭代器Itr都会完成LinkedBlockingQueue队列中下一个Node节点的遍历
public E next()
Node<E> p;
// 为了不会抛出该异常,所以在每一次调用next()方法前,都需要先调用一下hasNext()方法
if ((p = next) == null)
throw new NoSuchElementException();
// 局部变量p既是这次调用next()方法所处理的Node节点
// 将p Node赋值为lastRet属性,也就是将其记录成“最后一次”调用next()方法所处理的Node节点
lastRet = p;
// 局部变量x,既是本次next()方法调用将返回的
E x = nextItem;
// 接下来的处理过程必须要获取到LinkedBlockingQueue队列的添加和取数的操作权后,才能进行
fullyLock();
try
E e = null;
// 在上一次next()方法调用后,到本次next()方法调用时,LinkedBlockingQueue队列的情况已经发生了变化
// 所以这里需要根据当前LinkedBlockingQueue队列的状态,确认是否要重新定位进行遍历的位置
for (p = p.next; p != null && (e = p.item) == null; )
// 通过该方法可以重新定位head.next引用的新位置
// 以便从新的head.next开始进行数据遍历
// 后文还会进行详细介绍
p = succ(p);
// 重新确认next属性和nextItem属相的引用
// 为下一次next()方法的调用做好准备
next = p;
nextItem = e;
finally
fullyUnlock();
return x;
以上hasNext()方法和next()方法的代码片段中,大部分代码都很好理解,基本上可以概括为:将实例化时或者上次next()方法调用时已预先获取到的nextItem作为本次next()方法的返回结果。
除去这些简单易懂的部分外,以上代码片段中最需要进行详细讲解的就是“for (p = p.next; p != null && (e = p.item) == null; )” 这句for循环语句了。这句代码的实际作用是帮助迭代器在两次操作间隙,LinkedBlockingQueue队列中的数据发生了变化的场景下,对迭代器的遍历位置进行校验和调整以保证迭代器工作的稳定性。在讲解这段代码的工作逻辑前,我们需要对之前已经讲到的LinkedBlockingQueue队列(单向链表)的工作特性做一个总结:
-
LinkedBlockingQueue队列一般使用在存在多线程同时进行抢占操作的场景下。也就是说队列集合的使用场景,如果没有多线程抢占的情况,则不推荐使用LinkedBlockingQueue队列(或其它有保证线程安全特点的队列)。
-
LinkedBlockingQueue队列内部是一个单向链表,后者一直都是从链表的尾部添加数据对象,从链表的“头部”取出数据对象。且单向链表中的每个Node节点都没有重复使用情况——类似ArrayBlockingQueue队列那样的环形数组。
-
上一个描述中“头部”打上双引号的原因,是因为单向链表会保证头部第一个Node节点永远不存储数据对象,真正存储数据对象的Node节点,是头部Node的next属性指向的整个单向链表的第二个Node节点。
-
LinkedBlockingQueue队列中的数据,存在单向链表的一个一个Node对象中,且只有两种主要方式将特定的Node对象从单向链表中移除:通过dequeue()方法从队列“头部”移除,或者通过remove(Object)方法,从队列的某个特定位置移除。不论通过什么方式移除,被移除的Node对象都具有连个特点:首先这个Node对象的item属性为null,其次这个Node对象的next属性将引用至自己。
-
LinkedBlockingQueue队列的取数和添加操作,采用两个独立的可重入锁进行控制(分别是takeLock和putLock),理论上来说两种操作可以独立进行工作互不影响(但实际上存在相互进行通知的情况)。而迭代器为了保证每次遍历数据的正确性,就需要同时获取两种操作的锁权限。
我们考虑一种典型的多线程场景下同一个LinkedBlockingQueue队列被至少两个线程同时操作的情况:当LinkedBlockingQueue队列被创建,且添加了一些数据后,A线程创建了一个迭代器,紧接着,B线程通过诸如take()这样的方法从LinkedBlockingQueue队列中连续取出了一系列数据,如下图所示:
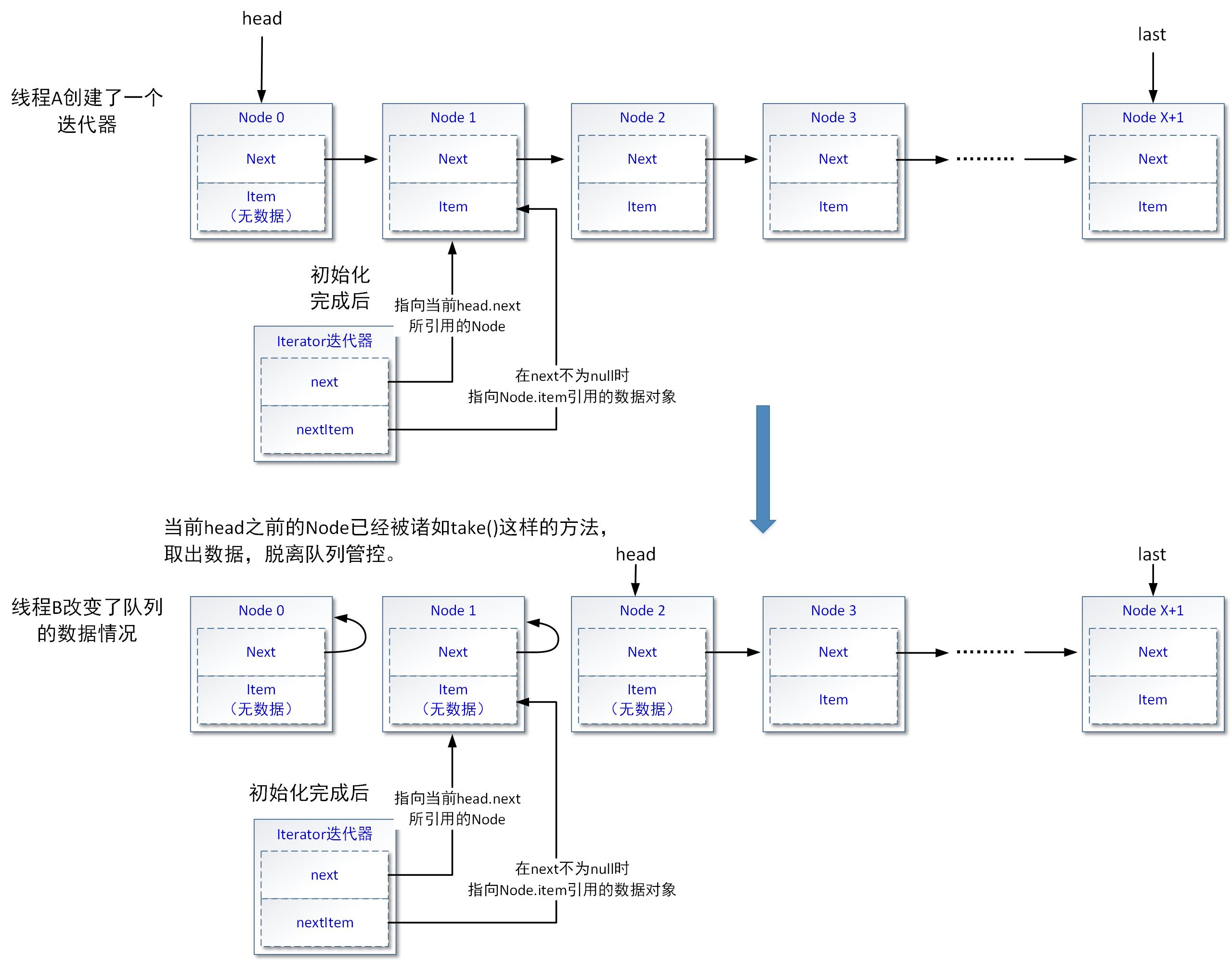
如上图所示,当B线程改变了LinkedBlockingQueue队列的数据后,Node1、Node2节已经被移除队列,它们的共同特点是Node对象中的item属性为null,且Node对象的next属性引用自己。
接着线程A中创建的迭代器开始通过hasNext()方法和next()方法的配合(或者迭代器的forEachRemaining()方法)进行LinkedBlockingQueue队列中数据的遍历。当执行hasNext()方法时,由于迭代器的next属性不为null,所以前者会返回true;现在我们来分析一下执行next()方法时,会发生的处理逻辑:
// 该方法用于在每次遍历前调用,以校验和修正Node p节点的位置
//(到正确的,正在LinkedBlockingQueue队列中的,第一个有数据对象的Node节点)
Node<E> succ(Node<E> p)
if (p == (p = p.next))
p = head.next;
return p;
// ......
private class Itr implements Iterator<E>
// ......
public E next()
// ......
// 在获取到操作权限前的操作过程并无过多讲解的必要
// 可以看前文的详细注释
fullyLock();
try
E e = null;
// 根据上文中已经介绍过的代码片段,p变量的初始值是迭代器Itr中next属性中的引用
// 从上一个记录的next位置开作为位置校验的初始位置
// 如果当前遍历校验的p位置中的item属性为null,说明这个位置已经出现了问题
// 最可能的情况是已经被移出队列,这个时候就调用succ()方法进行p节点的修正
for (p = p.next; p != null && (e = p.item) == null; )
p = succ(p);
// 重新确认next属性和nextItem属相的引用
// 为下一次next()方法的调用做好准备
next = p;
nextItem = e;
finally
fullyUnlock();
return x;
// ......
以上代码片段,可以用以下的示意图进行表达:
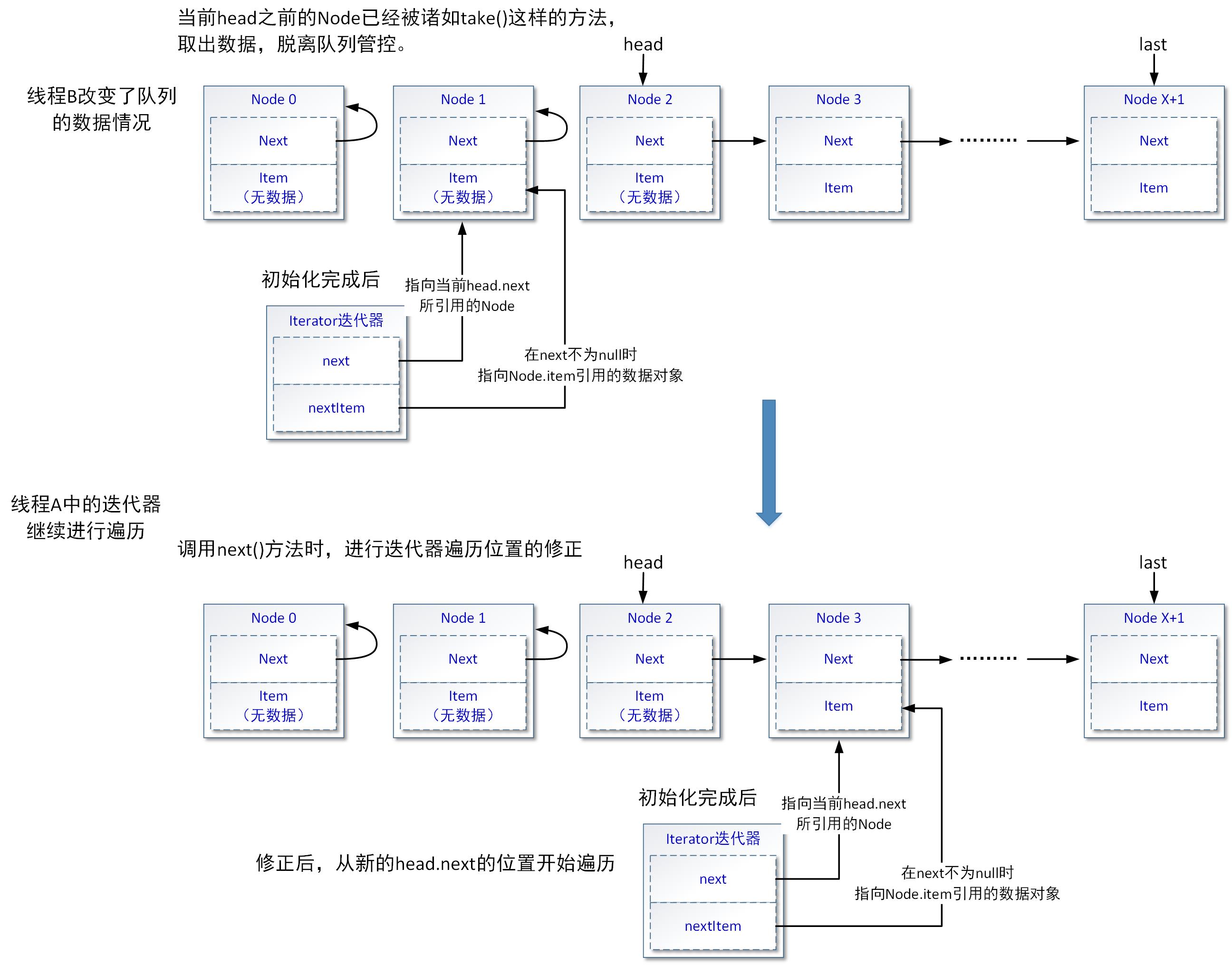
很明显,当B线程改变LinkedBlockingQueue队列的数据后,迭代器目前所指向的Node1节点已经被移出队列,将要遍历的Node2节点虽然还在队列中,但是该Node节点已经没有数据。这时,迭代器在执行next()方法时,就必须进行遍历位置的校验和修正,这样才能保证迭代器能继续遍历LinkedBlockingQueue队列中的后续数据。
以上是关于源码阅读(36):Java中线程安全的QueueDeque结构——LinkedBlockingQueue的主要内容,如果未能解决你的问题,请参考以下文章