ES(搜索 / 查询)
Posted xue_yun_xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES(搜索 / 查询)相关的知识,希望对你有一定的参考价值。
一、数据准备
es 官方银行客户账户 数据 ,用来演示
1、下载数据
webget https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
2、将json 提交到es 中
curl -H “Content-Type: application/json” -XPOST “192.168.12.130:9200/bank/_doc/_bulk?pretty&refresh” --data-binary “@accounts.json”
3、查看bank 结构
根据id查询
GET /bank/_doc/1
搜索
GET /bank/_search
查看 _doc 结构
GET /bank/
说明:
“account_number”: 1, #账号
“balance”: 39225, #账户余额
“firstname”: “Amber”, #名子
“lastname”: “Duke”, #姓氏
“age”: 32, #年龄
“gender”: “M”, #性别
“address”: “880 Holmes Lane”, #地址
“employer”: “Pyrami”, #雇佣者 老板 公司
“email”: “amberduke@pyrami.com”, # 邮箱
“city”: “Brogan”, #所在城市
“state”: “IL” #国家简称
二、搜索
1、term&terms查询
term terms 搜索 是按照关键字搜索,查询的属性必须是关键字 (keyword)
#term 只匹配 keyword
POST /bank/_doc/_search
"from": 0,
"size": 5,
"query":
"term":
"state.keyword":
"value": "DE"
# terms查询
# 只要查询的 属性值 符合其中一个 就查询出来
POST /bank/_doc/_search
"from": 0,
"size": 20
,
"query":
"terms":
"state.keyword": [
"DE",
"PA"
]
2、match查询【重点】
match查询属于高层查询,他会根据你查询的字段类型不一样,采用不同的查询方式。
- 查询的是日期或者是数值的话,他会将你基于的字符串查询内容转换为日期或者数值对待。
- 如果查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
- 如果查询的内容时一个可以被分词的内容(text),match会将你指定的查询内容根据一定的方式去分词,去分词库中匹配指定的内容。
match查询,实际底层就是多个term查询,将多个term查询的结果给你封装到了一起。
查询所有
# 查询所有
POST /bank/_doc/_search
"from": 0,
"size": 5,
"query":
"match_all":
# 查询所有
POST /bank/_doc/_search
"from": 0,
"size": 5
根据单词查询
# address 是 text 类型
# match 时 会将 要查询的数据进行切分,查询出来 只要任意一个文档含有其中一个 单词 ,就查出来
POST /bank/_doc/_search
"from":0,
"size":20,
"query":
"match":
"address":"Avenue Baycliff Place"
match 多条件查询
or 或者 and 匹配多个单词
#或者关系
POST /bank/_doc/_search
"from":0,
"size":20,
"query":
"match":
"address":
"query":"Avenue Newkirk",
"operator":"and"
多条件multi_match查询
match针对一个field做检索,multi_match针对多个field进行检索,多个field对应一个text。
# 两个字段含有一个符合条件就可以
# 我们查询 两个属性 只要有一个属性匹配查询单词 ,就查出来
POST /bank/_doc/_search
"from":0,
"size":20,
"query":
"multi_match":
"query": "Hondah Avenue",
"fields": ["city","address"]
3、根据id 查询
GET /bank/_doc/1
# 根据id 一次查询多个
POST /bank/_doc/_search
"query":
"ids":
"values":["1","2","3"]
4、wildcard查询 卡方查询
通配查询,和mysql中的like是一个套路,可以在查询时,在字符串中指定通配符*和占位符?
5、range查询
范围查询,只针对数值类型,对某一个Field进行大于或者小于的范围指定
gt:> 大于
gte:>= 大于等于
lt:< 小于
lte:<= 小于等于
# 使用 range 查询属性 是数值型的 范围
POST /bank/_doc/_search
"from":0,
"size":20,
"query":
"range":
"age":
"gt": 24,
"lte": 25
6、复合查询
复合查询就是将 上面学习的 term terms match multi_match 等 组合起来 通过 should(只要满足一个就可以) must(所有都必须满足) must_not( 所有的有应该 不满足)
bool查询
复合过滤器,将你的多个查询条件,以一定的逻辑组合在一起
- must: 所有的条件,用must组合在一起,表示And的意思
- must_not:将must_not中的条件,全部都不能匹配,标识Not的意思
- should:所有的条件,用should组合在一起,表示Or的意思
# 如果 should 和 must 一起使用 should 默认不起作用
POST /bank/_doc/_search
"query":
"bool":
"should": [
"term":
"city.keyword":
"value": "Mathews"
,
"term":
"city.keyword":
"value": "Shaft"
],
"must_not": [
"term":
"age":
"value": "39"
],
"must": [
"match":
"state": "DE"
,
"match":
"lastname": "Bartlett"
],
"minimum_should_match": 1
补充
# 模糊查询 将descr 当成关键字 作为整体 去模糊匹配 *名著*
POST /book2/novel/_search
"from":0,
"size":5,
"query":
"wildcard":
"descr.keyword":
"value":"*名著*"
GET /book2
没有分词器
"descr" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
为什么 book2 中的 descr 不能模糊?
就是因为没有为descr 配置分词器,将descr对应的值 切分为每一个字 ,现在去模糊匹配 "*名著*"
POST /book/novel/_search
"from":0,
"size":5,
"query":
"wildcard":
"descr.keyword":
"value":"*名著*"
GET /book 有分词器,可以将 descr进行分词
"descr" :
"type" : "text",
"analyzer" : "ik_max_word"
,
因为 /book descr 有分词器,在加入数据时会自动将descr 进行切分 切分为单词,所以
/book 模糊匹配单词 "*名著*"
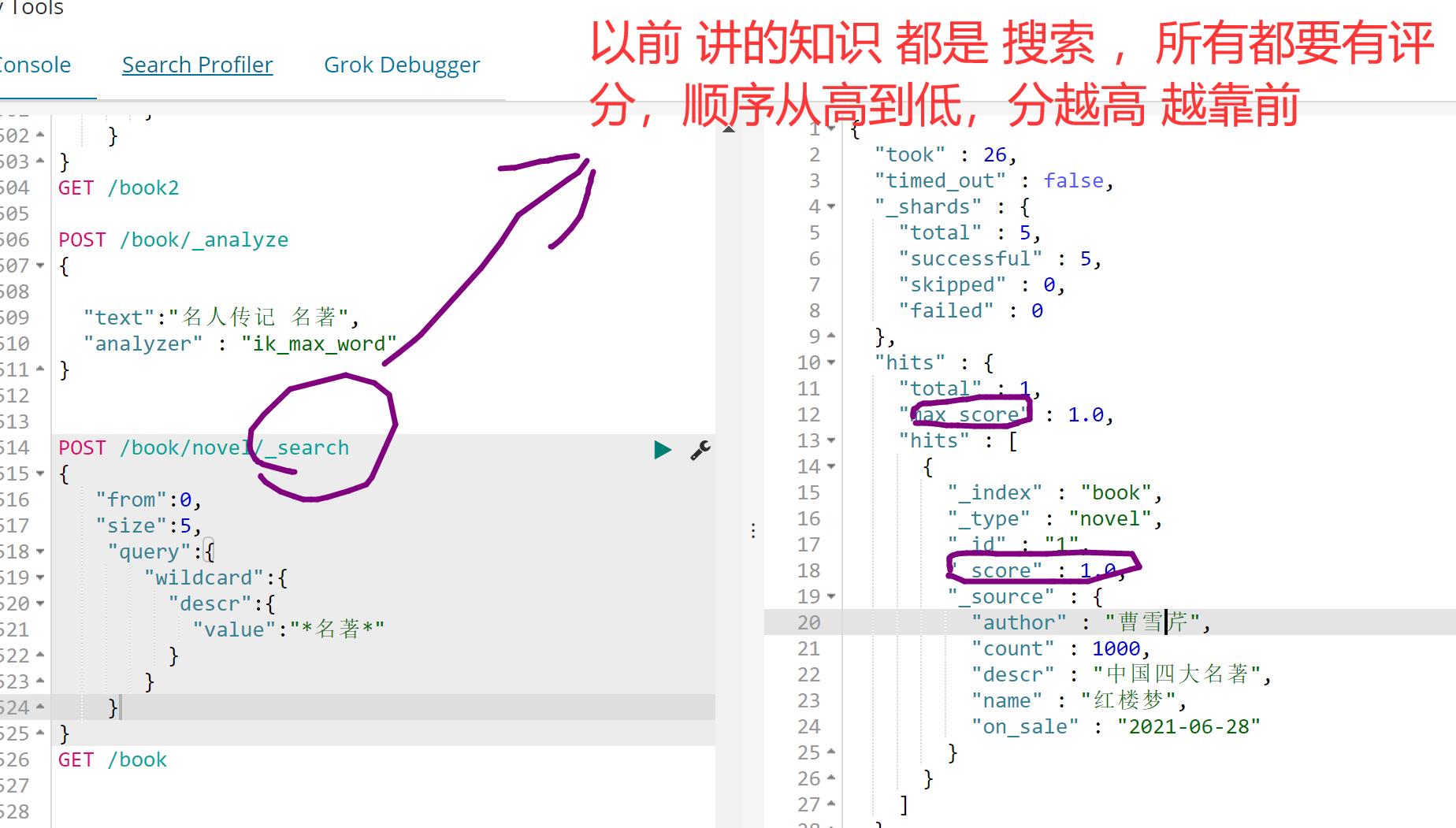
7、filter查询
query:根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的。
filter:根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。
如果在查询时仅仅是为了查询出来,不要查询结果的准确性,我们一般都使用filter ,因为没有评分,不需要排序,性能更好
# 过滤
POST /bank/_doc/_search
"query":
"bool":
"filter": [
"term":
"address": "731"
,
"range":
"age":
"lte": 40
]
8、 高亮显示
POST /bank/_doc/_search
"query":
"match":
"address": "Street"
,
"highlight":
"fields":
"address":
,
"pre_tags": "<font color='red'>", #前缀
"post_tags": "</font>", #后缀
"fragment_size": 10
9、聚合查询
就是将 结果按照一定的 属性 对应 的规则 进行分组,分组内 求平均值 最大值 最小值 ,数量
去重计数查询
去重计数,即Cardinality,第一步先将返回的文档中的一个指定的field进行去重,统计一共有多少条
field 对应的列必须是关键字,如果不是需要province.keyword
POST /bank/_doc/_search
"aggs": #聚合
"agg":
"cardinality": # 去重
"field": "state.keyword" #按照 state 去重,去重时属性必须是 keyword

范围统计
统计一定范围内出现的文档个数,比如,针对某一个Field的值在 0100,100200,200~300之间文档出现的个数分别是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range,date_range,ip_range
数值统计
POST /bank/_doc/_search
"aggs":
"agg":
"range":
"field": "age",
"ranges": [
"to": 15
,
"from": 15,
"to": 30
,
"from": 30
]
对数值型 属性进行统计
#平均年龄
POST /bank/_doc/_search
"aggs":
"agg":
"extended_stats":
"field": "age"
以上是关于ES(搜索 / 查询)的主要内容,如果未能解决你的问题,请参考以下文章