并发编程整理
Posted xanlv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程整理相关的知识,希望对你有一定的参考价值。
一、 同步
1 synchronized 关键字
synchronized 锁什么?锁对象, 为了操作的原子性。
可能锁对象包括: this, 临界资源对象(多线程能访问到的对象),Class 类对象。
synchronized(this) 和 锁方法都是锁当前对象
synchronized(XXX.class) 和 Synchronized 静态方法 都是锁当前类型的类对象
同步方法只影响调用同一把锁的同步方法
锁重入:同一线程多次调用其他同步方法(注:他们同一把锁),可重入,解决自己锁自己,比如有A,B两个被锁方法,同步方法A内部可以调用同步方法B。子类同步方法覆盖父类同步方法,子类同步方法可以调用父类同步方法。
同步方法中发生异常自动释放锁资源,不影响其他线程执行。
同步粒度问题:尽量避免同步方法,使用同步方法块
锁对象变更问题:
常量问题:不要使用常量作为锁对象(小于127,大于-128都在常量池(代码区))
2锁的底层实现-重量级锁
基于进入和退出线程管理对象monitor,由方法调用指令读取运行时常量池中方法的ACC_SYNCHRONIZED标志来隐式实现的。monito是由objectmonitor实现
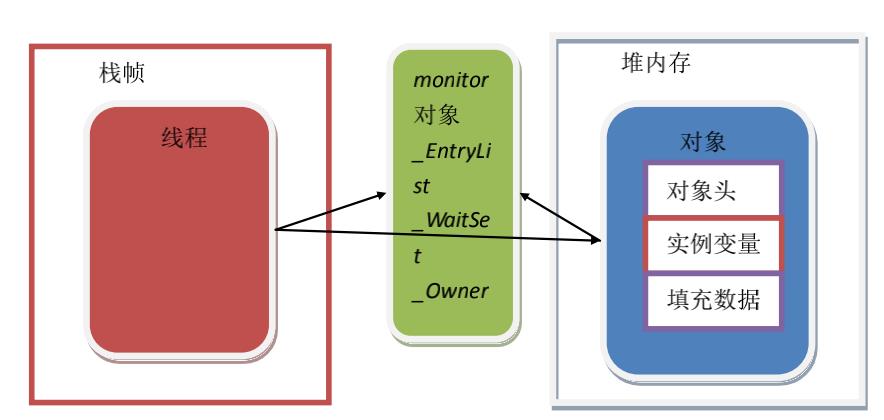
对象头:存储对象的hashcode,锁信息,分代年龄,GC标志,类型指针指向对象的类元数据,jvm通过这个指针确定该对象是哪个类的实例信息等。
实例变量:类的属性数据信息,包括父类的属性信息。
填充数据:jvm要求对象起始地址必须是8字节整数倍,非必须存在,只是为了字节对齐。
objectmonitor有两个队列,_waitset(等待队列)和_entrylist(锁池阻塞队列),以及_owner(标记当前执行线程)
阻塞状态-可执行状态:
1.sleep(),thread.join()->sleep结束或thread.interrupt()打断阻塞抛出异常,thread线程结束
2.等待队列:o.wait()->o.notify(),notifyAll()唤醒,无法打断阻塞
3.锁池-获取锁。
执行状态-可执行状态:时间片结束或thread.yield()
多线程访问同一同步代码,先进入_entrylist获取锁,当线程获取锁后,_owner记录当前线程,并在monitor中的计数器增一,代表锁定,其他线程在_entrylist中继续阻塞。若线程调用wait,则monitor计数器减一,并将_owner标记赋值null,代表放弃锁,线程进入waitset中,若执行线程调用notify()或notityAll(),则线程被唤醒进入_entrylist中阻塞,等待获取锁标记。
3锁的种类
1.偏向锁:是一种编译解释锁,当不可能出现多线程并发争抢同一把锁时,编译代码解释执行的时候,会自动放弃同步信息,消除synchronized的同步代码结果。使用锁标记形式记录锁状态。在monitor中有变量ACC_SYNCHRONIZED,当变量值使用使用代表偏向锁锁定,可以避免锁的争抢和锁池状态维护,提高效率
2.轻量级锁:有多线程并发访问锁定同一对象时,先提升为轻量级锁,使用ACC_SYNCHRONIZED标记记录。ACC_SYNCHRONIZED标记记录未获取到锁信息的线程,即只有两个线程争抢锁标记的时候优先使用轻量级锁
3.自旋锁:偏向锁和自旋锁的过渡。当获取锁而未获取到,为了提高效率,jvm自动执行若干次空循环再次申请锁,而不是进入阻塞状态,自旋锁提高效率就是避免线程状态的变更。
4.重量级锁
锁只能升级,不能降级
4 volatile关键字
volatile的可见性:cpu计算过程中,检查内存中数据的有效性,保证最新内存数据被使用,如父子卡。非原子性。
5.AtomicXxx类型组
AtomicXxx:每个方法都是原子性操作,保证线程安全,如银行转账操作。
6 conutDownLatch门闩
可以混合使用或代替锁的功能。线程调用await()后会检查锁数量,门闩数量大于0,线程等待。线程调用countdown()递减门闩数量,当数量为0时,await阻塞线程会执行,在门闩未完全开放之前等待,完全开放后执行,避免锁效率低下问题。
7 Reentrantlock
1.重入锁/公平锁,重量级比synchronized轻,但1.7后也不差多少,必须必须在finally中释放锁。
reentrantlock.lock无法被打断,reentrantlock.lockinterruptibly可以被打断t2.interrupt()抛出异常
2.尝试锁:reentrantlock.trylock()如果有锁,获取锁,无锁返回false。Reentrantlock.try(5,TimeUnit.seconds)阻塞尝试锁,超时不等待直接返回
3.重入锁&条件
private Lock lock = new ReentrantLock();
private Condition producer = lock.newCondition();
private Condition consumer = lock.newCondition();
// 借助条件,消费者进入等待队列,释放锁标记。
consumer.await();
// 借助条件,唤醒所有的生产者
producer.signalAll();
8 公平锁
会记录等待时长
9 threadLocal
1.map<Thread.getcureentThread(),线程需要保存的变量>
2.内存问题,并发量高时可能会有内存溢出
3.资源回收:每个线程结束之前一定要将当前线程保存的变量删除,threadlocal.remove().
二、同步容器
1 map/set
1.concurrentHashMap/concurrentHashset:底层hash实现同步Map/set。使用底层技术实现线程安全,key和value都不能为null,量级比synchronized低
2.concurrentSkipListMap/concurrentSkipListMap:底层跳表skiplist实现的同步Map/set,有序,比concurrentHashmap效率低
2 List
copyOnwriteArrayList:写时复制集合,每次写入都会创建一个新的底层数组,读效率高
3 QUEUE
1).concurrentLinkedQueue:基础链表同步队.查看首数据queue.peek(),获取首数据queue.poll()
2).LinkedBlockingQueue:阻塞队列,队列容量为0时take()或队列容量满了put()自动阻塞.生产者消费者
3).ArrayBlockingQueue:底层数组实现的有界队列。自动阻塞,容量不足时有阻塞能力
容量不足时:add()抛异常,put()阻塞等待,offer()返回false不阻塞,offer(value,times,timeunit)阻塞时长内有容量空闲新增数据返回true,否则放弃新增返回false
4).DelayQueue:延时无界队列,根据比较机制实现自定义处理顺序队列,常用于定时任务,如定时关机
5).LinkedTransferQueue:转移队列,add()保存数据不做阻塞等待。利用transfer()实现数据即时处理,无消费者(take()方法调用者)就阻塞
6).SynchronusQueue同步队列,容量为0的同步队列,是一个必须要有消费线程等待才能使用的特殊的7).transferQueue:add()无阻塞,若无消费者阻塞等待数据则抛异常,put()有阻塞,若无消费者阻塞等待数据则阻塞
三、ThreadPool&Excecutor
1.Executor
线程池顶级接口,execute(runnable)用户处理任务的一个服务方法,调用者提供Runnable接口的实现。启动线程任务.
public class Thread_executor implements Executor
public static void main(String[] args)
new Thread_executor().execute(new Runnable() ...);
public void execute(Runnable command) new Thread(command).start();
2.ExecutorService
Executor子接口,提供返回值future类型的方法submit
线程池状态:running/shuttingdown-service.isShutDown()/terminated-service.isTerminated()。优雅关闭Service.shutdown()将已接收的任务处理完毕后再关闭。
ExecutorService executorService= Executors.newFixedThreadPool(1);
executorService.execute(new Runnable() ...);//无返回值
Future<String> future = executorService.submit(new Callable<String>() ...);//有返回值
3.Future
线程结束后的结果,用get()阻塞等待线程执行结束并得到结果,get(long,timeUnit)等待线程执行固定时长结束后的结果,超时抛出异常
Future<String> future = executorService.submit(new Callable<String>() ...);
future.isDone()线程是否结束,future.get()
FutureTask<String> task = new FutureTask<>(new Callable<String>() ...);
new Thread(task).start();task.get()
4.Callable
可执行接口,类似runnable,也是可以启动一个线程的接口,方法call有返回值不能抛出异常,同run
static class ComputingTask implements Callable<List<Integer>>
public List<Integer> call() throws Exceptionreturn new ArrayList<>();
5.Executors
工具类型。Executor的工具类,可以快速提供各种容量线程池,如容量固定的,无限容的,容量为1的。类似Collection和Collections的关系.
线程池是一个进程级的重量资源,默认生命周期和jvm一致。关闭需要手动调用shutdown()或jvm关闭。
6.fixedTreadPool
所有的线程池中都有一个任务队列,当任务数量超过线程数量,未运行的任务保存到任务队列中,当有线程空闲自动从任务队列中取任务执行。使用 BlockingQueue作为任务的载体,常见的线程池容量: PC - 200。 服务器 - 1000~10000
7.cachedThreadPool
缓存的线程池,容量不限自动扩容。当线程池中线程不满足任务执行,创建新的线程,每次有任务无法即时处理就会创建新的线程。空闲线程时长达到临界值(默认60s),自动释放线程。测试硬件性能,作为fixedThreadPool容量的指导
ExecutorService service = Executors.newCachedThreadPool();
8.scheduledThreadPool
计划任务的线程池,可以根据计划自动执行任务的线程池。计划任务时选用(DelaydQueue)
ScheduledExecutorService service = Executors.newScheduledThreadPool(3);
service.scheduleAtFixedRate(new Runnable()
, 0, 300, TimeUnit.MILLISECONDS);//定时完成任务-
第一次任务执行的间隔,多次任务执行的间隔,时间单位。
9.singleThreadExecutor
容量为1的线程池,按顺序执行,如秒杀
ExecutorService service = Executors.newSingleThreadExecutor();
10.Forkjoinpool
分支合并线程池,递归处理复杂任务。初始化容量和cpu核心数有关。线程池中运行的内容必须是 ForkJoinTask 的子类型(RecursiveTask有但会结果的分支合并能力,RecursiveAction无返回结果)。(Callable/Runnable)compute 方法:就是任务的执行逻辑。 默认都是一个线程,根据任务自动(fork开启一个新的任务线程和join阻塞方法将任务的结果获取)分支新的子线程
static class AddTask extends RecursiveTask<Long> // RecursiveAction
int begin, end;
public AddTask(int begin, int end)this.begin = begin;this.end = end;
protected Long compute()
if((end - begin) < MAX_SIZE)
long sum = 0L;
for(int i = begin; i < end; i++)
sum += numbers[i];
return sum;
else
int middle = begin + (end - begin)/2;
AddTask task1 = new AddTask(begin, middle);
AddTask task2 = new AddTask(middle, end);
task1.fork();//就是用于开启新的任务-分支工作。 就是开启一个新的线程任务。
task2.fork();
// join - 合并。将任务的结果获取。 这是一个阻塞方法。一定会得到结果数据。
return task1.join() + task2.join();
final static int[] numbers = new int[1000000], int MAX_SIZE = 50000,Random r = new Random();
staticfor(int i = 0; i < numbers.length; i++)numbers[i] = r.nextInt(1000);
long result = 0L;
for(int i = 0; i < numbers.length; i++)result += numbers[i];
ForkJoinPool pool = new ForkJoinPool();
AddTask task = new AddTask(0, numbers.length);
Future<Long> future = pool.submit(task);
System.out.println(future.get());
11.WorkStealingpool
线程池中维护的是精灵线程,初始化容量和cpu核心数有关。1.8新增的工作窃取线程,当池中有空闲连接时,自动窃取为完成任务自动执行。
12.threadpoolexecutor
除了forkjoinpool,其他线程池底层都是基于threadpoolexecutor实现
// 模拟fixedThreadPool, 核心线程5个,最大容量5个,线程的生命周期无限(0为永久,非0:当线程空闲多久后,自动回收)。
ExecutorService service = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
任务队列,阻塞队列,注意泛型必须是 Runnable
以上是关于并发编程整理的主要内容,如果未能解决你的问题,请参考以下文章