实训周报2--RCNN论文解读
Posted LiemZuvon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实训周报2--RCNN论文解读相关的知识,希望对你有一定的参考价值。
RCNN论文解读
这一周,我们主要的任务是继续完善DISC的coarse net以及实现DISC的fine net,另外,我们还需要看一篇堪称经典到不能再经典的论文,那就是Ross et.的Rich feature hierarchies for accurate object detection and semantic segmentation, 这篇论文对应的模型是RCNN,一个一直在不断发展的模型(RCNN->Fast RCNN->Faster RCNN)。这里,我主要记录下对这篇论文的理解,包括模型的结构,和可视化手段。
模型的结构
RCNN模型是一个结合Region Proposal方法以及Convolution Neural Networks的模型,全称为Regions with CNNs features(这里提醒下读者注意和RNN的R区分开来= =)。
简单来说,RCNN由三部分组成,分别是Region Proposal区域选取方法,CNNs特征提取器和SVMs分类器。
Region Proposal
在这篇论文中,RCNN采取的Region Proposal方法是Selective Search(SS),相比与传统的区域选取方法,比如说Sliding Window方法,SS方法可以大量的减少提取的区域数量,SS方法其实有点像Superpixel的方法,简单来说就是把图片中相近的像素点归类到一起,然后就把图片划分成了很多小块,然后SS再把相邻的小块之间在做组合,从而产生大量的区域,一般来说,一个物体一般都是连续的(除了被遮挡等),所以SS产生的Regions大部分涵盖了一个图片存在的物体。这个方法比起Sliding Windows来,可以大量的减少Regions数量,而且产生的Region本身也具有一定的语义,并且可以大大加快测试的速度,虽然SS费时,但是在测试时,它只产生2000个Regions,比起Sliding Windows图片像素点的个数的Regions来说,是要快不少的。
对于想进一步了解SS的读者,小编这里推荐一篇师兄的文章给大家
http://blog.csdn.net/surgewong/article/details/39316931
当然,SS产生的Region也不是直接就能用的,首先要对它们进行标记,RCNN的标记的策略是如果与Ground Truth(GT)的IoU(Intersection of Union,简答来说就是交集面积/全集面积)大于等于0.5的就认为这个Region的label与GT一致。
极端的来看,如果GT完全包含了Region,那么根据IoU的定义,这个Region面积至少是GT的一半,也即包含一半以上的像素点,CNNs应该也都还是能接受的(比如Region只包含一半人脸的情况我觉得是不会出现的,因为SS会选择连续相近的像素啊!),然而有可能出现一个Region包含了两个GT的情况吗…根据IoU,要不这两个GT重叠,要不这两个GT刚好平分Region,对于后者我觉得概率几乎为零,而对于两个GT重叠的情况,就可以选择IoU大的那个。
然后对于得到的Regions,RCNN还需要做一点处理以便把图片传入给后面的CNNs,RCNN只是简单的Region放缩到与CNNs输入尺寸相同的大小(227*227*3),然而对于那些比较扁的Regions,RCNN会先分割Region之前先向外扩展p=16个像素,得到一个比较方的Region后,在放缩227*227*3。
CNNs
RCNN的第二部分是CNNs,也能说是核心部分(这个部分是不可替换的,不想Region Proposal和分类器有各种方法)。但也是最简单粗暴的。这部分使用的是AlexNet的finetunig版本,因此输入也要与AlexNet的要求一致
对于不清楚AlexNet的读者,可以看看我之前的博客,这里就不多赘述啦
http://blog.csdn.net/u012767526/article/details/51804900
然而这篇论文提供了一个很有趣的观点,这里我觉得很有必要拿出来聊下,下面先pose一个图:
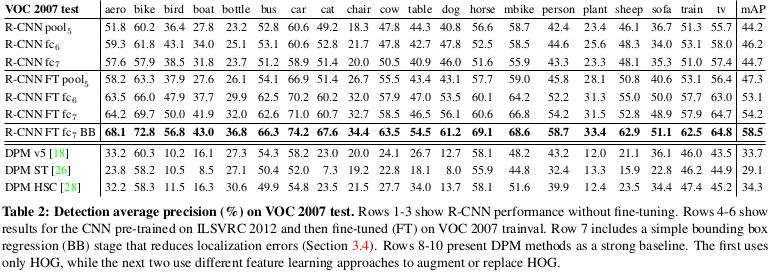
上图的前面6列可以分成两类,分别是without/with finetuning下,保留模型到pool5、fc6、fc7的mAP。在没有finetuning的情况下,得到的结果完全依赖与之前的结果,这时发现,保留至fc6,甚至是保留至pooling5之后的效果都把比保留至fc7的效果好很多。
然而在finetuning之后,会发现保留至fc7在finetuning之后效果突增,保留至fc6的效果也增长了不少,然而保留至pooling5的效果并没有很大的变化。这里论文得到的结论是,保留至pooling5的网络的功能是一个比较通用的特征提取功能。
打个比方说吧,这个层就相当于是干细胞(保留pooling5模型),博而不精(通用的特征提取功能),然后呢,我们可以通过给这个干细胞一些形状(就是加层),然后辅以一定的功能指向(就是数据),使这个干细胞能够变成一个有特定功能的细胞(finetuning之后的模型),此时这个有特定功能的细胞就只能实现这个特定功能(FC7 with finetuning),效果会比干细胞好很多,但是如果要它做其他的事情(FC7 without finetuning),效果还不如干细胞。
SVMs分类器
SVM分类器是一个在超平面寻找最大margin,并分类的方法,这个方法是可以用与多类别分类问题的,但是论文不是对21个类(别漏了background类哦)使用一个SVM,而是使用了One-Versu-All的方法,对每个类别都使用个SVM(这里只需要20个SVM,想想为什么?)。方法很简单,对于每个类别来说,一个Region如果不是该类别,那就是背景。这同样要求CNNs的输出是21维的特征,每个SVM只关注属于它自己的特征。在测试的时候,对于每个类,如果有多个有交集的Region被预测正样本,那么使用贪心策略,只取Score最高的那个Region。这样,通过上面的几个步骤,就能做到:定位+分类。
可视化手段
这篇论文还提出了一个很有趣的可视化方法,有助于我们一定程度上地理解CNN内部的工作情况。
论文从pooling5的结果入手,指出其实对于pooling5结果中的每一个值,都对应原图的一篇区域(也称感受野),感受野的大小为195*195。当某类物体出现在pooling5的某个unit的感受野时,pooling5就会输出一个比较大的值(激活)。留意到pooling5的某个unit只对某些类别具有响应,比如下图

的第一行是对应了pooling5的某一个unit激活时的区域,可以发现,当这个感受野出现了人脸时,该unit被激活。第二行对应的unit当出现波点或狗脸时会被激活。
以上是关于实训周报2--RCNN论文解读的主要内容,如果未能解决你的问题,请参考以下文章