hadoop原理学习——hdfs读数据
Posted simon麦田
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop原理学习——hdfs读数据相关的知识,希望对你有一定的参考价值。
转自:http://blog.sina.com.cn/s/blog_4aca42510102vuxo.html

当客户端打算从 HDFS 中取数据的时候,例如一个作业的结果,同样需要首先与 Name Node 打交道,的值想取的数据被存放在哪里,Name Node 同样会给客户端一个清单,然后客户端去 Name Node 指定的某个 Data Node 中拿数据(通过TCP 50010 端口)。
客户端不会逐个 Data Node 去拿数据,而是由 Name Node 指定的那个 Data Node 分别去其他的 Data Node 那里拿数据。好像客户端在说:“Name Node,告诉我数据都在哪儿?”,Name Node 说“他们在 Data Node x、y、z,你去 Data Node x 拿数据吧”,客户端于是告诉 Data Node X,你把 y 和 z 的数据一起拿来并送到我这里来。
在这里,Name Node 同样会考虑“机架意识”,并通过机架意识来找到最近的 Data Node 并将数据传输过去。
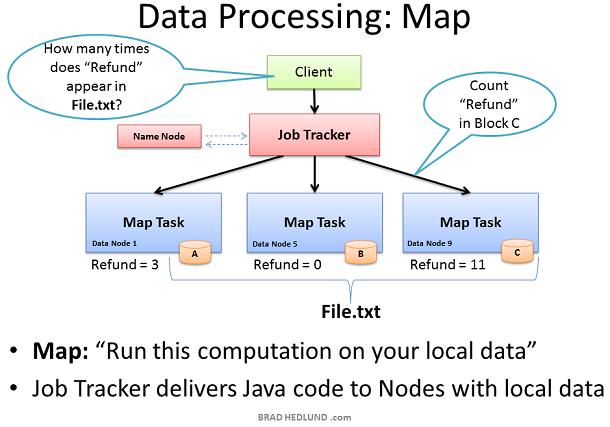
现在,我们已经知道 File.txt 被分发到不同的 Data Node上,也知道了他们是如何运转的了,现在我们就开始看看 Hadoop 是具体如何使用 Map Reduce 框架来进行快速运算的吧。
第一步是 Map 阶段,在我们的例子中,我们要求我们的 Hadoop 集群计算出邮件中“Refund”单词的数量。 在一开始,客户端会提交一个 Map Reduce 作业,例如:“在 File.txt 中有多少个 Refund?”当然,这句话是翻译自 Java 语言,通过 Java 编写好一个 Map Reduce 作业并提交作业给 Job Tracker。Job Tracker 与 Name Node 协调得到哪些 Data Node 包含 File.txt 的数据块。 然后 Job Tracker 开始在这些 Data Node 上激活 Task Tracker。 Task Tracker 开始 Map 作业并监视任务进度。Task Tracker同时也提供心跳和任务状态给 Job Tracker。
当所有的 Map 任务完成后,每个节点都会存放一个结果在其本地物理磁盘上,这被称为“中间数据”。接下来,就是将这些中间数据通过网络发送给一个执行 Reduce 任务的节点。
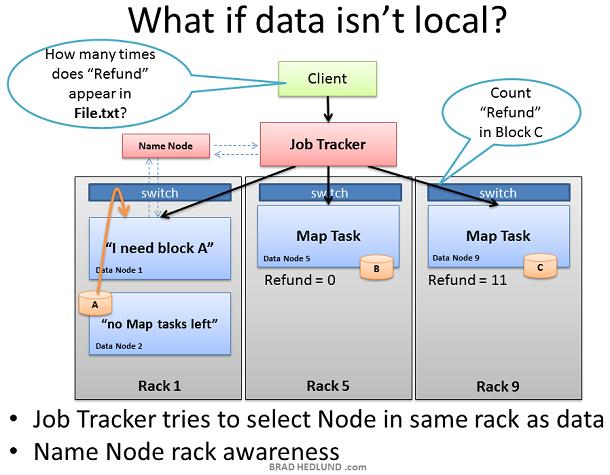

同样,Job Tracker 会根据机架意识来挑选同一机架内的其他节点来完成 Reduce 任务。
Job Tracker 可能会挑选集群中任意一个节点来作为 Reduce 任务的处理服务器,此时可能会一次性有大量的数据涌向 Reduce 任务所在的节点服务器,这种情况通常被称为“Incast”或“fan-in”。这需要牛逼点的交换机以及内部流量管理和足够的缓冲区(不要太大,也不要太小)。缓冲区的大小最终可能会造成不必要的附带损害(流量相关)。但这是另外一个话题。
现在 Reduce 已经收集到了所有从 Map 计算得到的中间数据,并可以开始最后阶段的计算,在本文的例子中,我们仅仅是简单的将各个结果相加即可得到“Refund”的数量。然后将结果写入到 Results.txt 文件。客户端可以从HDFS中读取Results.txt 文件,并将工作视为完成。
这个例子并没有造成大量的中间数据和流量占用问题,但是实际生产环境可能会造成大量的中间数据和带宽瓶颈。这就是 Map Reduce 作业中代码如何计算的一门学问,如果用最优化的代码来完成作业是需要我们来决定的。
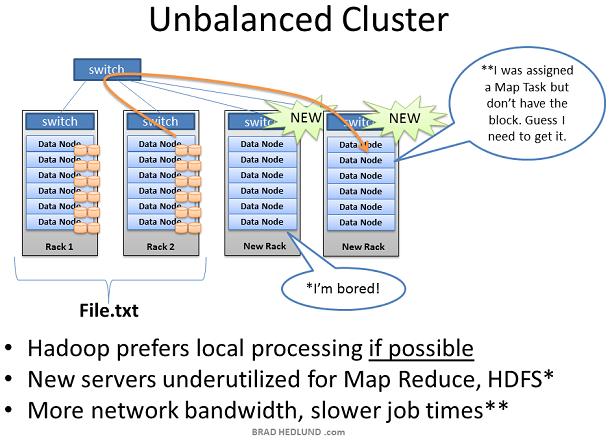

Balancer 可以很好的照顾你的集群。鉴于 Balancer 的默认带宽设置,他可能需要较长的时间来完成均衡的操作,可能几天,也可能几周。
以上是关于hadoop原理学习——hdfs读数据的主要内容,如果未能解决你的问题,请参考以下文章