OpenCV的dnn模块调用TesorFlow训练的MoblieNet模型
Posted 冰不语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV的dnn模块调用TesorFlow训练的MoblieNet模型相关的知识,希望对你有一定的参考价值。
一、初得模型
那是一个月之前的事情了,我利用TesorFlow Object Detection API训练了现在目标检测里面应该是最快的网络MobileNet。当时的目的就只是学习整个finetuning的流程,于是我只是用了20张自己标注的人脸样本图片作为训练集去finetuning,训练完之后的模型通过修改TesorFlow Object Detection API自带的例程代码,即object_detection_tutorial.ipynb,运行结果竟然还不错,对于图片中的大小适中的人脸能够比较准确地检测,毕竟我只用了20个样本训练啊。当然,了解了流程和方法之后,以后多少样本的训练都不在话下……只要有足够数据和够好的显卡…
二、C++调用之难,难于上西天
然而,其实我训练的目标检测模型是要在C++环境下用的。TensorFlow也提供了C++ API,但是要用的话需要自己从源码编译,而且用的是Bazel。是的,我用的是Windows,所以,在尝试安装BazelN次失败之后,我尝试用OpenCV3.3.0新出的dnn模块调用训练好的模型。然而新出的dnn模块当时支持的模型太少了,它支持ssd-mobilenet的caffe模型,但是并不支持mobilenet的tensorflow模型,当时也看到了github上有人提交issue提到这个问题。
问题的issue参考这里:Unable to import mobilenet model using latest OpenCV.#9462。
有人在这里给出了一个解决方案:Layers for MobileNet from TensorFlow #9517。
解决方案里面最后一步:Modify for DNN: fuse batch normalizations and removeSqueezeop.需要用到一个工具:transform_graph。而这个工具需要用bazel编译……又回到了bazel……
三、柳暗花明
在没能力自己修复问题之前,只能等待大神解决。一个月期间,多次尝试bazel,包括windows环境和ubuntu环境,可能对这些工具不熟悉吧,总之没能成功解决。终于盼到十月份OpenCV3.3.1出来,果然对此有了更新。而且加载模型的API也有了变化,从原来的一个参数变成了两个参数。而且针对MobileNet还给出了一种解决方案。目前尚不能确定这种方案是否适用于其他模型,比如Inception等。
现在把这种方法记录如下,以备后用,以防遗忘,同时帮助同道中人。
- 首先通过TensorFlow detection_model_zoo下载他们训练好的模型,或者用
TesorFlow Object Detection API训练或者finetuning之后,由models-master\\object_detection\\export_inference_graph.py导出的模型文件frozen_inference_graph.pb。(利用object_detection_tutorial.ipynb的话,只是这一个文件就够了。) - 到https://github.com/opencv/opencv_extra/blob/master/testdata/dnn/ssd_mobilenet_v1_coco.pbtxt)下载
ssd_mobilenet_v1_coco.pbtxt。然后把这个文件的第2222行修改为attr key: "num_classes" value i: 2。其中这个2根据自己的需要改成目标数+1。比如我这里只有一类——人脸,所以我改为2。 - 参考
mobilenet_ssd_python.py,这个文件在这里https://github.com/opencv/opencv/blob/master/samples/dnn/mobilenet_ssd_python.py。 - 还有一点,要用最新的OpenCV3.3.1,OpenCV3.3.0是不行的。
这里的例子mobilenet_ssd_python.py是Python的,我结合OpenCV给出的例子ssd_mobilenet_object_detection.cpp,修改了一个C++的版本,其实都差不多。例子很多,而且代码很相似,所以木有注释。如下:
#include<opencv2\\opencv.hpp>
#include<opencv2\\dnn.hpp>
#include <iostream>
using namespace std;
using namespace cv;
const size_t inWidth = 300;
const size_t inHeight = 300;
const float WHRatio = inWidth / (float)inHeight;
const char* classNames[] = "background","face" ;
int main()
String weights = "face_frozen_inference_graph.pb";
String prototxt = "ssd_mobilenet_v1_coco.pbtxt";
dnn::Net net = cv::dnn::readNetFromTensorflow(weights, prototxt);
Mat frame = cv::imread("image4.jpg");
Size frame_size = frame.size();
Size cropSize;
if (frame_size.width / (float)frame_size.height > WHRatio)
cropSize = Size(static_cast<int>(frame_size.height * WHRatio),
frame_size.height);
else
cropSize = Size(frame_size.width,
static_cast<int>(frame_size.width / WHRatio));
Rect crop(Point((frame_size.width - cropSize.width) / 2,
(frame_size.height - cropSize.height) / 2),
cropSize);
cv::Mat blob = cv::dnn::blobFromImage(frame,1./255,Size(300,300));
//cout << "blob size: " << blob.size << endl;
net.setInput(blob);
Mat output = net.forward();
//cout << "output size: " << output.size << endl;
Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());
frame = frame(crop);
float confidenceThreshold = 0.20;
for (int i = 0; i < detectionMat.rows; i++)
float confidence = detectionMat.at<float>(i, 2);
if (confidence > confidenceThreshold)
size_t objectClass = (size_t)(detectionMat.at<float>(i, 1));
int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
ostringstream ss;
ss << confidence;
String conf(ss.str());
Rect object((int)xLeftBottom, (int)yLeftBottom,
(int)(xRightTop - xLeftBottom),
(int)(yRightTop - yLeftBottom));
rectangle(frame, object, Scalar(0, 255, 0),2);
String label = String(classNames[objectClass]) + ": " + conf;
int baseLine = 0;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
rectangle(frame, Rect(Point(xLeftBottom, yLeftBottom - labelSize.height),
Size(labelSize.width, labelSize.height + baseLine)),
Scalar(0, 255, 0), CV_FILLED);
putText(frame, label, Point(xLeftBottom, yLeftBottom),
FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
namedWindow("image", CV_WINDOW_NORMAL);
imshow("image", frame);
waitKey(0);
return 0;
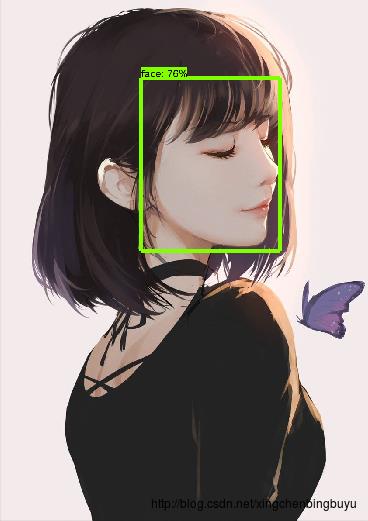
最后的测试结果如下:

四、路漫漫
对比两种方式的检测结果,我觉得还是tensorflow的方框更精确一点,而且后者的图片是裁剪过的。另外,两种结果的confidence不一样,估计是实现的方式不太一样。这一点还需要继续探究,今天先把方法记下来。同时欢迎大家指点,集思广益。
以上是关于OpenCV的dnn模块调用TesorFlow训练的MoblieNet模型的主要内容,如果未能解决你的问题,请参考以下文章