Python爬虫之Scrapy框架系列——XXTop250电影所有信息同时存储到MySql数据库
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之Scrapy框架系列——XXTop250电影所有信息同时存储到MySql数据库相关的知识,希望对你有一定的参考价值。
现在又不满足于只保存在本地txt文本了,所以来试试存储到数据库mysql里怎么搞呢?(首先,要准备好mysql数据库以及navicat数据库可视化管理工具)
目录:
分析:如何同时存储到本地txt文本以及mysql数据库里?
- 这就需要再新建一个管道,并开启这个管道( settings里管道类名添加 ),最后,使用pymysql连接数据库。
示例代码:

1.1 新建管道完整代码:
import pymysql
class DoubanSqlPipeline(object):
# 1.连接数据库
def open_spider(self,spider):
data_config=spider.settings["DATABASE_CONFIG"]
if data_config["type"]=="mysql":
self.conn=pymysql.connect(**data_config["config"])
self.cursor=self.conn.cursor()
def process_item(self,item,spider):
dict(item)
sql='insert into dbfilm (filmname,starname,score,description) values(%s,%s,%s,%s)'
self.cursor.execute(sql,
(
item["film_name"],
item["star_name"],
item["score"],
item["description"],
)
)
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
1.2 settings.py文件中连接mysql数据库的配置:
DATABASE_CONFIG=
"type":"mysql",
"config":
"host":"localhost",
"port":3306,
"user":"root",
"password":"123456",
"db":"doubanfilm",
"charset":"utf8"
1.3 settings.py文件中打开储存到Mysql数据库的管道:

1.4 navicat创库建表:
创库:
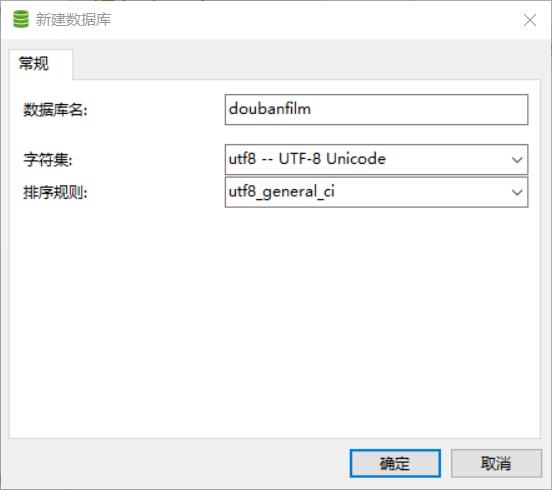
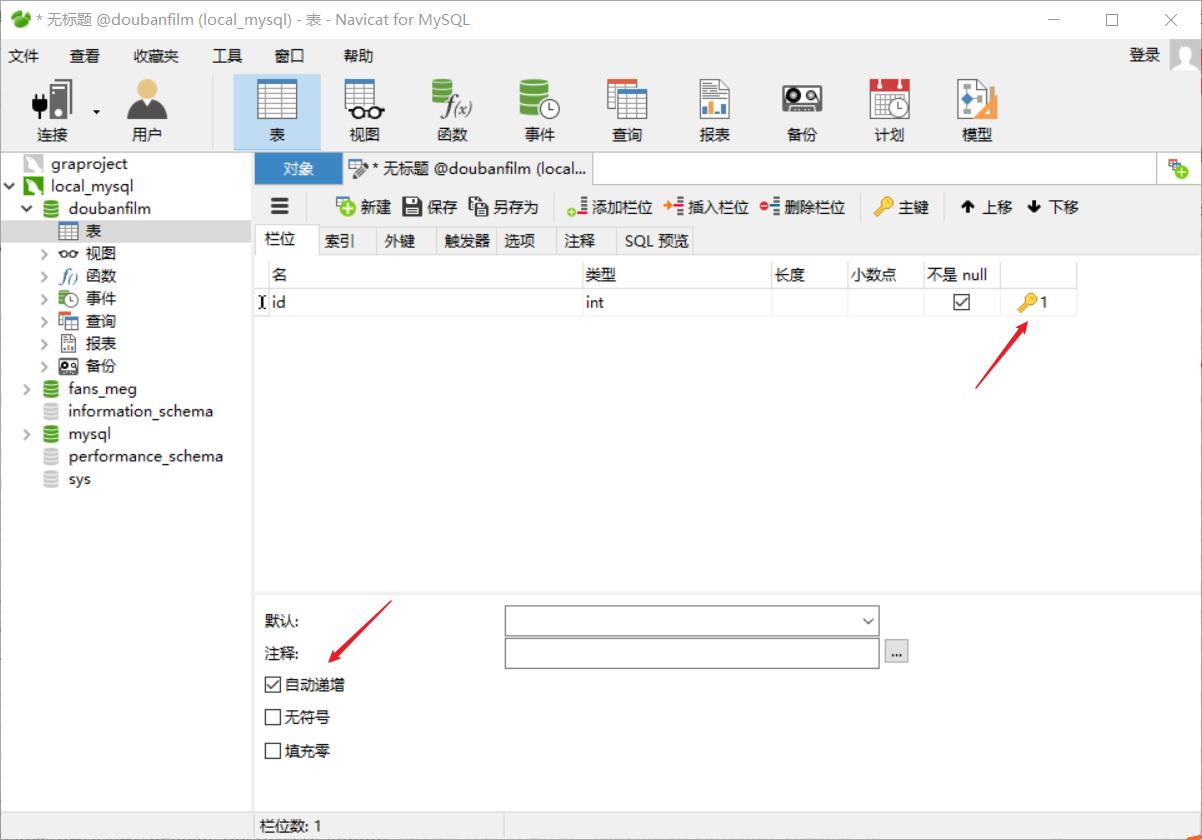
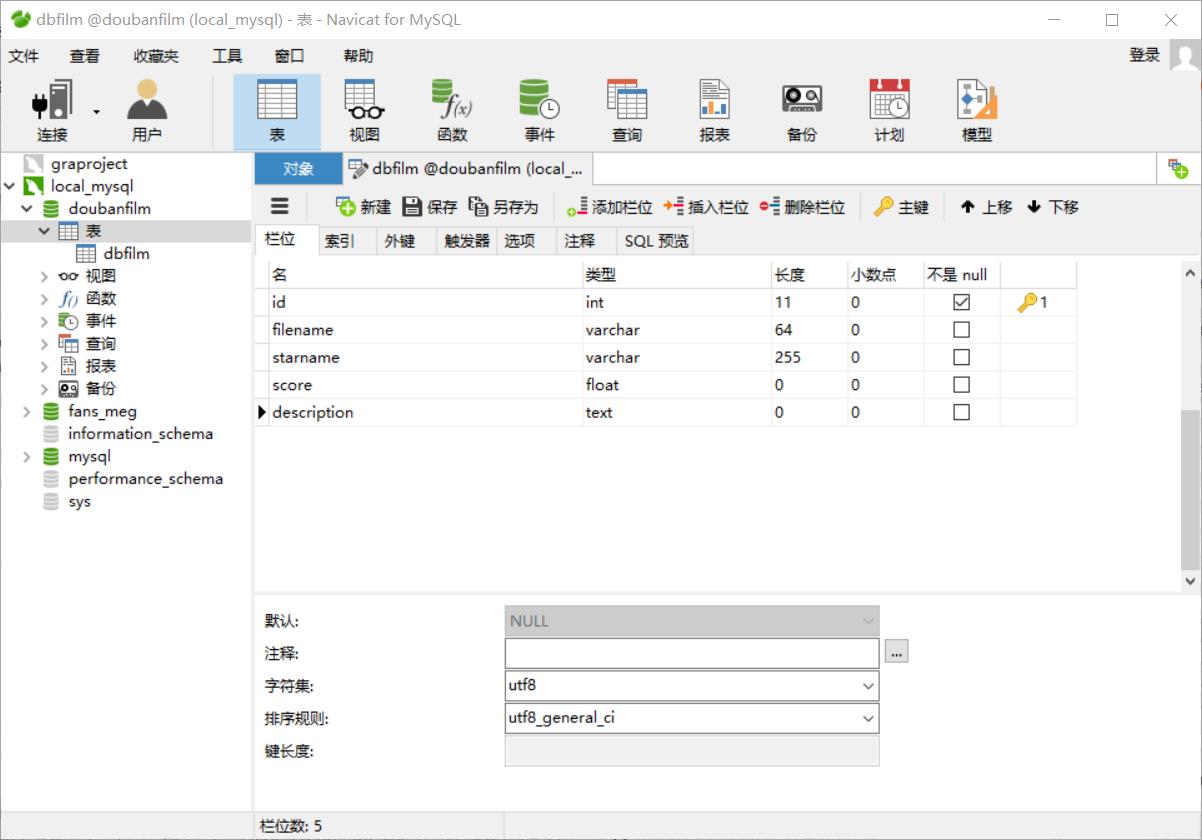
1.5 运行爬虫即可
- (注意:运行之前,一定要在Mysql里创建对应的数据库,表及字段)。运行之后navicat里效果:
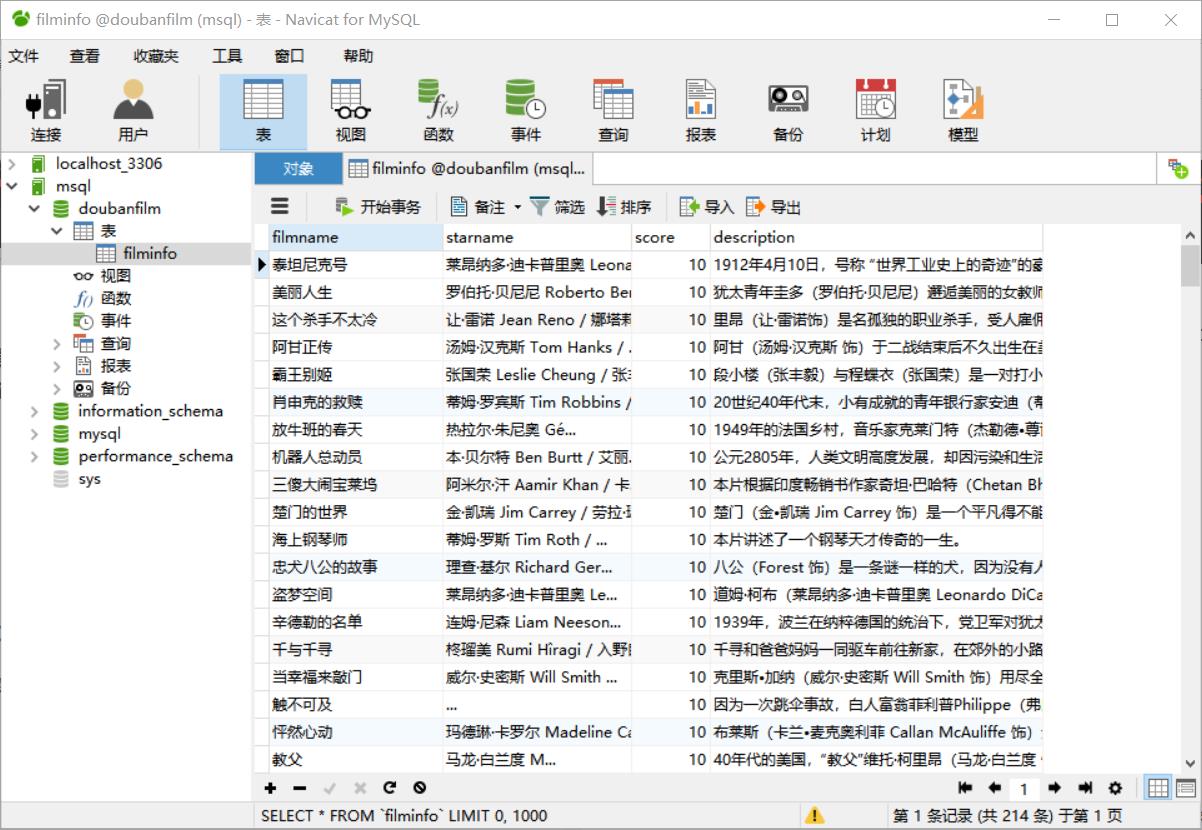
豆瓣项目已完结!项目源码:
链接:https://pan.baidu.com/s/1DOnXwXZKiBcJbzHwDJuw5A
提取码:u8xi
以上是关于Python爬虫之Scrapy框架系列——XXTop250电影所有信息同时存储到MySql数据库的主要内容,如果未能解决你的问题,请参考以下文章