强化学习笔记-01多臂老虎机问题
Posted tostq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记-01多臂老虎机问题相关的知识,希望对你有一定的参考价值。
本文是博主对《Reinforcement Learning- An introduction》的阅读笔记,不涉及内容的翻译,主要为个人的理解和思考。
1. 多臂老虎机问题
多臂老虎机问题是指存在K个老虎机,每个老虎机的获胜金额是一个未知的概率分布且相互独立,假设我们有N次参与机会,如何选择每次参与的老虎机才能使得累积获胜金额最大?
对于这个问题,我们首先可以知道,每次选择的老虎机应该是期望获胜金额最大的机器,即:

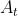 表示第t次选择的老虎机,Q(a)表示老虎机a的期望获胜金额,由于实际上我们只能根据历史数据进行估计,实际的形式为:
表示第t次选择的老虎机,Q(a)表示老虎机a的期望获胜金额,由于实际上我们只能根据历史数据进行估计,实际的形式为:

所以对于多臂老虎机问题最本质的问题在于对Q(a)的预估,这同强化学习中的价值函数V(s)及Q(s,a)是类似的。Q(a)的计算相对是简单的,其表示的期望可以由历史获胜金额的均值来表示。
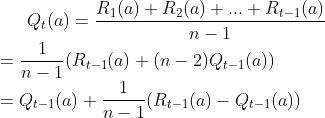
上式中的R(a)表示每次选择老虎机a时的奖励,n表示总共选择a的次数,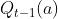 表示前一次选择老虎机a时的奖励预估。上式代表了新Q(a)是通过旧Q(a)进行更新的。
表示前一次选择老虎机a时的奖励预估。上式代表了新Q(a)是通过旧Q(a)进行更新的。
但是由于参与次数是有限的,一方面我们需对每个老虎机a进行大量的参与,才能对Q(a)进行较精确估计,另一方面为了保证整体的收益,我们需要尽可能地参与Q(a)高的老虎机。前者类似于强化学习中的explore过程,后者类似于exploit过程,如何去平衡这两者是balancing exploration and exploitation是多臂老虎机问题的重要难点,下一节我们将考虑几种方法用于解决这个问题。
关于更新权重的问题:
在很多情况下,我们会发现Q(a)的更新式子是如下形式的:
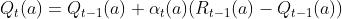
其通过α(a)代替了1/n,同时给出了如下条件下,Q(a)的更新是收敛的:

很多情况下我们会让 α(a)设为某个固定的值α,虽然当奖励分布Q是静态的时(不会随时间变化)并不能保证完全收敛,但是在实际上多数情况下奖励分布Q都是动态的,在这种情况下设为某个固定的值α往往也是可行的。
2. Balance Exploration and Exploitation的基本优化方法
A) ε-greedy
greedy(贪心算法)一般是指每次只选择当前Q最大的,即 ,而ε-greedy算法是指每次有一定较小的概率ε来平均选择其他项,即
,而ε-greedy算法是指每次有一定较小的概率ε来平均选择其他项,即

ε-greedy算法提供了最基础的形式来进行探索,通过ε值选择可以确定exploration和exploitation的平衡点。
B) UCB(Upper-Confidence-Bound)
UCB算法在原来的Q预估的基础上添加了一个上界的预估,这个上界当参与次数少的时候会大,而当参与足够多时,上界会收缩,这种方式保证了对未知的探索

上式中的t表示当前总共参与的次数,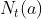 表示当前a的总共参与次数,c表示上界预估项的权重,通过c值选择可以确定exploration和exploitation的平衡点。
表示当前a的总共参与次数,c表示上界预估项的权重,通过c值选择可以确定exploration和exploitation的平衡点。
UCB这种方式包含了对Q预估的不确定性的定量估计,但当Q分布是动态变化时(即分布会随时间发生变化),会失去了探索动力,另一方面,当前动作空间特别大时,的计算也很困难。
C) 合理初始值Optimistic Initial Values
这种方式是给Q预估的初始值设置为一个较大值(一般情况下要远大于估计的均值)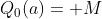 ,这种方式能保证在刚开始的情况下,各个机器都有均衡的概率被选择到,这种方式实现上比较简单好用,当各机器的奖励分布是静态时,其可以达到同ε-greedy算法类似的收益,甚至要好。但当机器的奖励分布是动态变化时(nonstationary problems),这种方式经过了长期迭代后,会失去了探索动力,UCB也有类似的问题。
,这种方式能保证在刚开始的情况下,各个机器都有均衡的概率被选择到,这种方式实现上比较简单好用,当各机器的奖励分布是静态时,其可以达到同ε-greedy算法类似的收益,甚至要好。但当机器的奖励分布是动态变化时(nonstationary problems),这种方式经过了长期迭代后,会失去了探索动力,UCB也有类似的问题。
D) 梯度方法Gradient algorithms
梯度方法根据动作的preference函数H(a)来选择参与的机器,其选择方式是通过一个概率决策函数π来确定的

所有机器在t时刻的选择概率之和为1,即
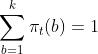
其中preference函数H(a)的计算式子为下式,其中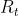 表示t时刻的收益,
表示t时刻的收益,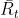 表示累积到t时刻的平均收益。
表示累积到t时刻的平均收益。
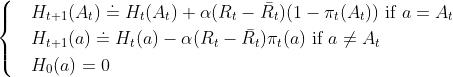
这种更新方式为什么被称之为梯度方法呢?实际上preference函数H(a)是为了最大化总体收益即E[R],因此我们考虑H(a)的更新方向是使得E[R]的最大的梯度方向,即:

这里的E[R]表示是当前收益的期望,q(b)表示机器b的期望收益。
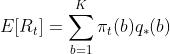
接下来,我们计算梯度:
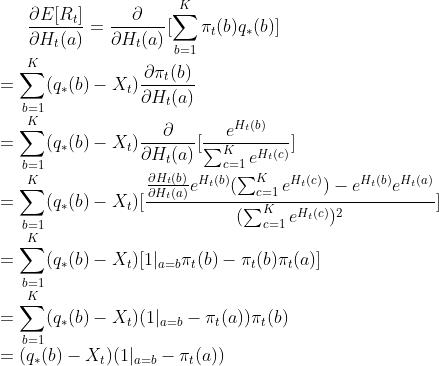
上式中的X表示一个同所选a不相关的变量,由于下式。

为什么要选择引入这个变量X?首先我们考虑机器b的期望收益q(b)实际上是很难预估的,所以我们实际用R即时收益来代替(称之为随机梯度法),如果设置X=0,仍是会收敛的,但是由于R本身带有一定的随机性,为了避免更新步伐太大,所以一般设置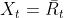 ,表示过去平均的总体收益。
,表示过去平均的总体收益。
E) 贝叶斯方法Bayesian methods
贝叶斯方法的逻辑是假设Q(a)是某种先验分布(如高斯分布,beta分布等),然后随着参与,不断更新Q(a)参数估计。在动作选择时,采用的是类似于后验采样(称之为posterior sampling or Thompson sampling)来选择动作。其原理是每一轮根据不同动作的Q(a)分布采样生成各自Q,然后再选择Q最高的a作为本轮的动作,这种方式兼顾exploration和exploitation。
以上是关于强化学习笔记-01多臂老虎机问题的主要内容,如果未能解决你的问题,请参考以下文章
强化学习专栏|多臂老虎机问题(Multi-armed Bandit Problem)
笔记︱盘点实验科学的三种实验模型(A/B实验因果推断强化学习)
笔记︱盘点实验科学的三种实验模型(A/B实验因果推断强化学习)