win10下用yolov3训练WiderFace数据集来实现人脸检测(TensorFlow版本,darkface作为测试集)
Posted 告白少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了win10下用yolov3训练WiderFace数据集来实现人脸检测(TensorFlow版本,darkface作为测试集)相关的知识,希望对你有一定的参考价值。
数据集准备工作
- 训练集 Wider Face格式转换
下载人脸数据集wider face,解压到同一个文件夹下

在同一个目录下,新建convert.py文件(把下面程序放入)运行程序得到图像和其对应的xml文件。
# -*- coding: utf-8 -*-
import shutil
import random
import os
import string
from skimage import io
headstr = """\\
<annotation>
<folder>VOC2012</folder>
<filename>%06d.jpg</filename>
<source>
<database>My Database</database>
<annotation>PASCAL VOC2012</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>company</name>
</owner>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """\\
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
"""
tailstr = '''\\
</annotation>
'''
def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % ('face', bbx[0], bbx[1], bbx[0] + bbx[2], bbx[1] + bbx[3]))
f.write(tail)
f.close()
def clear_dir():
if shutil.os.path.exists(('Annotations')):
shutil.rmtree(('Annotations'))
if shutil.os.path.exists(('ImageSets')):
shutil.rmtree(('ImageSets'))
if shutil.os.path.exists(('JPEGImages')):
shutil.rmtree(('JPEGImages'))
shutil.os.mkdir(('Annotations'))
shutil.os.makedirs(('ImageSets/Main'))
shutil.os.mkdir(('JPEGImages'))
def excute_datasets(idx, datatype):
f = open(('ImageSets/Main/' + datatype + '.txt'), 'a')
f_bbx = open(('wider_face_split/wider_face_' + datatype + '_bbx_gt.txt'), 'r')
while True:
filename = f_bbx.readline().strip('\\n')
if not filename:
break
im = io.imread(('WIDER_' + datatype + '/images/' + filename))
head = headstr % (idx, im.shape[1], im.shape[0], im.shape[2])
nums = f_bbx.readline().strip('\\n')
bbxes = []
if nums=='0':
bbx_info= f_bbx.readline()
continue
for ind in range(int(nums)):
bbx_info = f_bbx.readline().strip(' \\n').split(' ')
bbx = [int(bbx_info[i]) for i in range(len(bbx_info))]
# x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
if bbx[7] == 0:
bbxes.append(bbx)
writexml(idx, head, bbxes, tailstr)
shutil.copyfile(('WIDER_' + datatype + '/images/' + filename), ('JPEGImages/%06d.jpg' % (idx)))
f.write('%06d\\n' % (idx))
idx += 1
f.close()
f_bbx.close()
return idx
if __name__ == '__main__':
clear_dir()
idx = 1
idx = excute_datasets(idx, 'train')
idx = excute_datasets(idx, 'val')
print('Complete...')
运行后得到以下的文件(训练会重新打乱,所以只需要管Annotations,JPEGImages两个文件夹):

Annotations:存放图像对应的xml
ImageSets:包含train.txt ,val.txt(分别包含对应的图像名字)
JPEGImages:存放图像
- 测试集Dark Face格式转换
(若只用WilderFace作为训练集,测试集,忽略这一步)
下载夜间人脸数据集Dark Face,我使用的是它的训练集6000张图像作为测试。
运行下面的程序得到图像和对应的xml文件。
# -*- coding: utf-8 -*-
import os,shutil
import cv2
from lxml.etree import Element, SubElement, tostring
def txt_xml(img_path,img_name,txt_path,img_txt,xml_path,img_xml):
clas = []
img=cv2.imread(os.path.join(img_path,img_name))
imh, imw = img.shape[0:2]
txt_img=os.path.join(txt_path,img_txt)
with open(txt_img,"r") as f:
next(f)
for line in f.readlines():
line = line.strip('\\n')
list = line.split(" ")
print(list)
clas.append(list)
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = '1'
node_filename = SubElement(node_root, 'filename')
#图像名称
node_filename.text = img_name
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = str(imw)
node_height = SubElement(node_size, 'height')
node_height.text = str(imh)
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
for i in range(len(clas)):
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = "face"
node_pose=SubElement(node_object, 'pose')
node_pose.text="Unspecified"
node_truncated=SubElement(node_object, 'truncated')
node_truncated.text="truncated"
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '0'
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = str(clas[i][0])
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = str(clas[i][1])
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = str(clas[i][2])
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = str(clas[i][3])
xml = tostring(node_root, pretty_print=True) # 格式化显示,该换行的换行
img_newxml = os.path.join(xml_path, img_xml)
file_object = open(img_newxml, 'wb')
file_object.write(xml)
file_object.close()
if __name__ == "__main__":
#图像文件夹所在位置
img_path = r"E:\\BaiduNetdiskDownload\\DarkFace_Train_new\\images"
#标注文件夹所在位置
txt_path=r"E:\\BaiduNetdiskDownload\\DarkFace_Train_new\\label"
#txt转化成xml格式后存放的文件夹
xml_path=r"E:\\BaiduNetdiskDownload\\DarkFace_Train_new\\xml"
for img_name in os.listdir(img_path):
print(img_name)
img_xml=img_name.split(".")[0]+".xml"
img_txt=img_name.split(".")[0]+".txt"
txt_xml(img_path, img_name, txt_path, img_txt,xml_path, img_xml)
yolov3训练
- 下载训练代码和预训练模型,并搭建好环境
项目代码:tensorflow-serving-yolov3
基于vgg的coco预训练模型百度云地址,密码:vw9x - 把预训练模型解压到项目的checkpoint文件夹下,然后运行convert_weight.py,得到yolov3_coco_demo.ckpt模型
- 修改vis.names里的内容,只添加face这一个类别
- 把tensorflow-serving-yolov3/VOC2007/文件夹下的Annotations,JPEGImages两个文件夹换成第一步生成的wilderface的文件夹,接着修改split.py的60行内容
fi = open('./data/classes/voc.names', 'r')
修改为
fi = open('./data/classes/vis.names', 'r')
运行split.py,根目录下得到以下三个文件:
- 修改core/config.py的以下内容:
__C.TRAIN.BATCH_SIZE = 2#根据自己电脑情况自行修改
__C.YOLO.CLASSES = "./data/classes/vis.names"
__C.YOLO.ORIGINAL_WEIGHT = "./checkpoint/yolov3_coco_demo.ckpt"
__C.YOLO.DEMO_WEIGHT = "./checkpoint/yolov3_coco_demo.ckpt"
__C.TRAIN.FISRT_STAGE_EPOCHS = 20#根据自己需要自行修改
__C.TRAIN.SECOND_STAGE_EPOCHS = 30
__C.TRAIN.INITIAL_WEIGHT = "./checkpoint/yolov3_coco_demo.ckpt"
- 运行train.py进行训练
- 运行convert_weight.py保存模型
评估阶段
- 我用的是darkface的训练集全部作为测试,复制voc2007文件夹并重命名为DARK_face,并把Annotations,JPEGImages两个文件夹替换成darkface的xml和图像(这一步就是为生成YOLOv3所需要格式做准备)
- 修改split.py的内容
# -*- coding:utf-8 -*-
# split.py
from __future__ import division
import xml.etree.ElementTree as ET
import random
import os
def base_txt():
saveBasePath = r"./DARK_face/ImageSets" # txt文件保存目录
total_xml = os.listdir(r'./DARK_face/Annotations') # 获取标注文件(file_name.xml)
# 划分数据集为(训练,验证,测试集 = 49%,20%,30%)
val_percent =0 # 可以自己修改
test_percent = 1
trainval_percent = 0
# print(trainval_percent)
tv = int(len(total_xml) * trainval_percent)
#tr = int(len(total_xml) * train_percent)
ta = int(tv * val_percent)
tr = int(tv -ta)
tt = int(len(total_xml) * test_percent)
# 打乱训练文件(洗牌)
trainval = random.sample(range(len(total_xml)), tv)
train = random.sample(trainval, tr)
print("训练集图片数量:", tr)
print("验证集图片数量:", ta)
print("测试集图片数量:", tt)
# with open('/tmp/VOC2007/split.txt', 'w', encoding='utf-8') as f:
# f.write(str(val_percent))
ftrainval = open(os.path.join(saveBasePath, 'Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'Main/val.txt'), 'w')
for i in range(len(total_xml)): # 遍历所有 file_name.xml 文件
name = total_xml[i][:-4] + '\\n' # 获取 file_name
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
base_txt()
fi = open('./data/classes/vis.names', 'r') # 按文件夹里面的文件修改好
txt = fi.readlines()
voc_class = []
for w in txt:
w = w.replace('\\n', '')
voc_class.append(w)
print('数据集里面的类别:', voc_class)
classes = voc_class
def convert_annotation(year, image_id, list_file):
in_file = open('./DARK_%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = '.'
# sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[ ('face', 'test')]
# wd = getcwd()
for year, image_set in sets:
image_ids = open('./DARK_%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/DARK_%s/JPEGImages/%s.png'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\\n')
list_file.close()
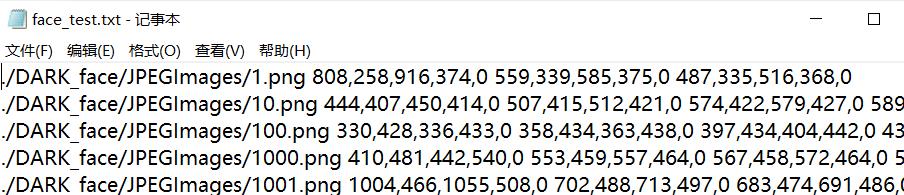
运行split.py,得到face_test.txt文件(内容如下)
格式: image_path x_min, y_min, x_max, y_max, class_id x_min, y_min ,…, class_id
- 评估数据集,修改config.py
__C.TEST.ANNOT_PATH = "./face_test.txt"
你之前训练保存的模型
__C.TEST.WEIGHT_FILE = "./checkpoint/yolov3_train_loss=14.6886.ckpt-50"
- 运行evaluate.py,在data/detection/下查看评估的结果
- 计算mAP,在终端运行
cd mAP
python main.py -na
ps:训练自己的数据集
1.先把vis.names文件内容修改为自己所需要的类别。
2.把自己数据集转换成图像+xml形式,替换掉项目中的voc2007文件夹对应的部分。
3.根据自己需要修改split.py里面的内容,划分数据集。
4.修改config.py内容,运行train.py训练。
5.运行evaluate.py评估结果。
6.运行mAP文件夹下的 main.py计算mAP。
以上是关于win10下用yolov3训练WiderFace数据集来实现人脸检测(TensorFlow版本,darkface作为测试集)的主要内容,如果未能解决你的问题,请参考以下文章