树问题总结之哈夫曼树
Posted 痕迹天涯119
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了树问题总结之哈夫曼树相关的知识,希望对你有一定的参考价值。
一、哈夫曼树的概念和定义
什么是哈夫曼树?
让我们先举一个例子。
判定树:
在很多问题的处理过程中,需要进行大量的条件判断,这些判断结构的设计直接影响着程序的执行效率。例如,编制一个程序,将百分制转换成五个等级输出。大家可能认为这个程序很简单,并且很快就可以用下列形式编写出来: [cpp] view plain copy- if(score<60)
- cout<<"Bad"<<endl;
- else if(score<70)
- cout<<"Pass"<<endl
- else if(score<80)
- cout<<"General"<<endl;
- else if(score<90)
- cout<<"Good"<<endl;
- else
- cout<<"Very good!"<<endl;
若考虑上述程序所耗费的时间,就会发现该程序的缺陷。在实际中,学生成绩在五个等级上的分布是不均匀的。当学生百分制成绩的录入量很大时,上述判定过程需要反复调用,此时程序的执行效率将成为一个严重问题。 但在实际应用中,往往各个分数段的分布并不是均匀的。下面就是在一次考试中某门课程的各分数段的分布情况:
 下面我们就利用哈夫曼树寻找一棵最佳判定树,即总的比较次数最少的判定树。
第一种构造方式:
下面我们就利用哈夫曼树寻找一棵最佳判定树,即总的比较次数最少的判定树。
第一种构造方式:
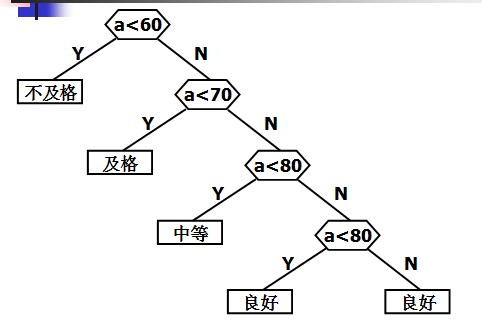 第二种构造方式:
第二种构造方式:
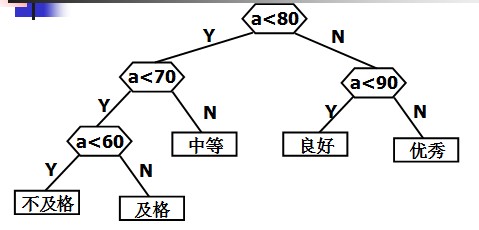 这两种方式,显然后者的判定过程的效率要比前者高。在也没有别地判定过程比第二种方式的效率更高。
我们称判定过程最优的二叉树为哈夫曼树,又称最优二叉树
===================================================================================================
这两种方式,显然后者的判定过程的效率要比前者高。在也没有别地判定过程比第二种方式的效率更高。
我们称判定过程最优的二叉树为哈夫曼树,又称最优二叉树
===================================================================================================
定义哈夫曼树之前先说明几个与哈夫曼树有关的概念:
路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
路径长度:路径上的分枝数目称作路径长度。
树的路径长度:从树根到每一个结点的路径长度之和。
结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值
之积称为该结点的带权路径长度(weighted path length)
什么是权值?( From 百度百科 )
计算机领域中(数据结构)
权值就是定义的路径上面的值。可以这样理解为节点间的距离。通常指字符对应的二进制编码出现的概率。
至于霍夫曼树中的权值可以理解为:权值大表明出现概率大!
一个结点的权值实际上就是这个结点子树在整个树中所占的比例.
abcd四个叶子结点的权值为7,5,2,4. 这个7,5,2,4是根据实际情况得到的,比如说从一段文本中统计出abcd四个字母出现的次数分别为7,5,2,4. 说a结点的权值为7,意思是说a结点在系统中占有7这个份量.实际上也可以化为百分比来表示,但反而麻烦,实际上是一样的.
树的带权路径长度:如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带
权路径长度。
设某二叉树有n个带权值的叶子结点,则该二叉树的带权路径长度记为:
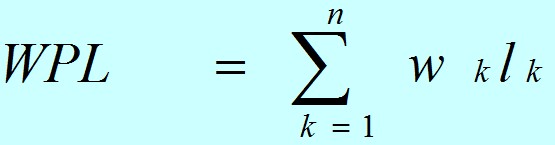
公式中,Wk为第k个叶子结点的权值;Lk为该结点的路径长度。
示例:
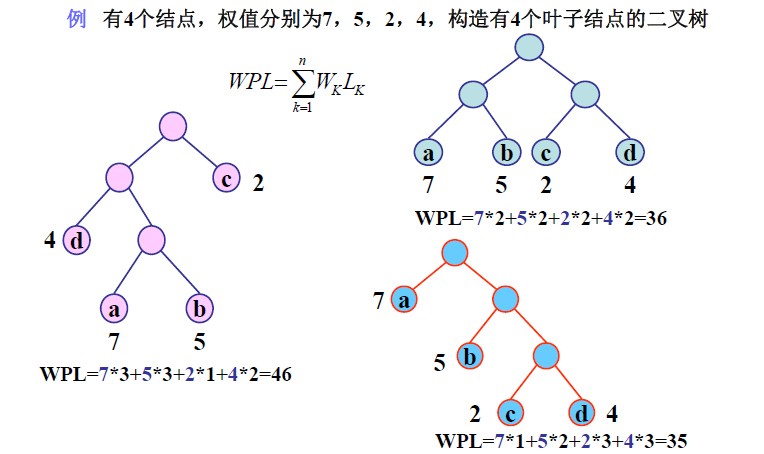
二、哈夫曼树的构造
根据哈弗曼树的定义,一棵二叉树要使其WPL值最小,必须使权值越大的叶子结点越靠近根结点,而权值越小的叶子结点 越远离根结点。 哈弗曼依据这一特点提出了一种构造最优二叉树的方法,其基本思想如下: 下面演示了用Huffman算法构造一棵Huffman树的过程:
下面演示了用Huffman算法构造一棵Huffman树的过程:

三、哈夫曼树的在编码中的应用
在电文传输中,需要将电文中出现的每个字符进行二进制编码。在设计编码时需要遵守两个原则: (1)发送方传输的二进制编码,到接收方解码后必须具有唯一性,即解码结果与发送方发送的电文完全一样; (2)发送的二进制编码尽可能地短。下面我们介绍两种编码的方式。 1. 等长编码 这种编码方式的特点是每个字符的编码长度相同(编码长度就是每个编码所含的二进制位数)。假设字符集只含有4个字符A,B,C,D,用二进制两位表示的编码分别为00,01,10,11。若现在有一段电文为:ABACCDA,则应发送二进制序列:00010010101100,总长度为14位。当接收方接收到这段电文后,将按两位一段进行译码。这种编码的特点是译码简单且具有唯一性,但编码长度并不是最短的。 2. 不等长编码 在传送电文时,为了使其二进制位数尽可能地少,可以将每个字符的编码设计为不等长的,使用频度较高的字符分配一个相对比较短的编码,使用频度较低的字符分配一个比较长的编码。例如,可以为A,B,C,D四个字符分别分配0,00,1,01,并可将上述电文用二进制序列:000011010发送,其长度只有9个二进制位,但随之带来了一个问题,接收方接到这段电文后无法进行译码,因为无法断定前面4个0是4个A,1个B、2个A,还是2个B,即译码不唯一,因此这种编码方法不可使用。 因此,为了设计长短不等的编码,以便减少电文的总长,还必须考虑编码的唯一性,即在建立不等长编码时必须使任何一个字符的编码都不是另一个字符的前缀,这宗编码称为前缀编码(prefix code) (1)利用字符集中每个字符的使用频率作为权值构造一个哈夫曼树; (2)从根结点开始,为到每个叶子结点路径上的左分支赋予0,右分支赋予1,并从根到叶子方向形成该叶子结点的编码 例题: 假设一个文本文件TFile中只包含7个字符A,B,C,D,E,F,G,这7个字符在文本中出现的次数为5,24,7,17,34,5,13 利用哈夫曼树可以为文件TFile构造出符合前缀编码要求的不等长编码 具体做法: 1. 将TFile中7个字符都作为叶子结点,每个字符出现次数作为该叶子结点的权值 2. 规定哈夫曼树中所有左分支表示字符0,所有右分支表示字符1,将依次从根结点到每个叶子结点所经过的分支的二进制位的序列作为该 结点对应的字符编码 3. 由于从根结点到任何一个叶子结点都不可能经过其他叶子,这种编码一定是前缀编码,哈夫曼树的带权路径长度正好是文件TFile编码 的总长度 通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code)
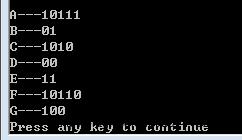
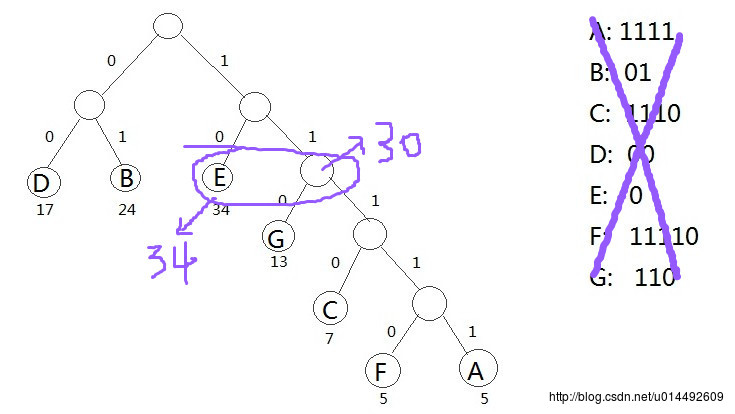 注意图中圈起来的两个圆交换位置结果就正确了,最终结果应该是:
注意图中圈起来的两个圆交换位置结果就正确了,最终结果应该是:
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
#define N 10 // 带编码字符的个数,即树中叶结点的最大个数
#define M (2*N-1) // 树中总的结点数目
struct HTNode // 树中结点的结构
unsigned int weight;
unsigned int parent,lchild,rchild;
;
struct HTCode
char data; // 待编码的字符
int weight; // 字符的权值
char code[N]; // 字符的编码
;
void Init(HTCode hc[], int *n)
// 初始化,读入待编码字符的个数n,从键盘输入n个字符和n个权值
int i;
printf("input n = ");
scanf("%d",n);
getchar();//这里一定要注意啊,处理掉缓冲区的'\\n'
printf("\\ninput %d character\\n",*n);
for(i=1; i<=*n; ++i)
scanf("%c",&hc[i].data);
printf("\\ninput %d weight\\n",*n);
for(i=1; i<=*n; ++i)
scanf("%d",&(hc[i].weight) );
//
void Select(HTNode ht[], int k, int *s1, int *s2)
// ht[1...k]中选择parent为0,并且weight最小的两个结点,其序号由指针变量s1,s2指示
int i;
for(i=1; i<=k && ht[i].parent != 0; ++i)
; ;
*s1 = i;
for(i=1; i<=k; ++i)
if(ht[i].parent==0 && ht[i].weight<=ht[*s1].weight)//注意这里面的<=号,为什么要加=呢?先自己思考下吧
*s1 = i;
for(i=1; i<=k; ++i)
if(ht[i].parent==0 && i!=*s1)
*s2 = i;break;
for(i=1; i<=k; ++i)
if(ht[i].parent==0 && i!=*s1 && ht[i].weight<=ht[*s2].weight)//同上
*s2 = i;
void HuffmanCoding(HTNode ht[],HTCode hc[],int n)
// 构造Huffman树ht,并求出n个字符的编码
char cd[N];
int i,m,c,f,s1,s2,start;
m = 2*n-1;
for(i=1; i<=m; ++i)
if(i <= n)
ht[i].weight = hc[i].weight;
else
ht[i].weight = 0;
ht[i].parent = ht[i].lchild = ht[i].rchild = 0;
for(i=n+1; i<=m; ++i)
Select(ht, i-1, &s1, &s2);
printf("s1位置对应权值:%d s2位置对应权值:%d\\n",ht[s1].weight,ht[s2].weight);//为了看得明白才添加的,
ht[s1].parent = i;
ht[s2].parent = i;
ht[i].lchild = s1;
ht[i].rchild = s2;
ht[i].weight = ht[s1].weight+ht[s2].weight;
printf("新生成节点在ht结构数组中的下标:%d 权值:%d\\n",i,ht[i].weight);//同上
cout<<endl<<endl;
cd[n-1] = '\\0';
for(i=1; i<=n; ++i)
start = n-1;
for(c=i,f=ht[i].parent; f; c=f,f=ht[f].parent)
if(ht[f].lchild == c)
cd[--start] = '0';
else
cd[--start] = '1';
strcpy(hc[i].code, &cd[start]);
int main()
int i,n;
HTNode ht[M+1];
HTCode hc[N+1];
Init(hc, &n); // 初始化
HuffmanCoding(ht,hc,n); // 构造Huffman树,并形成字符的编码
for(i=1; i<=n; ++i)
printf("\\n%c---%s",hc[i].data,hc[i].code);
printf("\\n");
return 0;
这篇文章来自 http://blog.csdn.net/shuangde800/article/details/7341289,但其代码上出现了一些问题,在这里予以改正,不过还是谢谢原文的博主了。
以上是关于树问题总结之哈夫曼树的主要内容,如果未能解决你的问题,请参考以下文章