机器学习&sklearn笔记:LDA(线性判别分析)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习&sklearn笔记:LDA(线性判别分析)相关的知识,希望对你有一定的参考价值。
1 介绍
1. 有监督的降维 2. 投影 后类内方差最小,类间方差最大
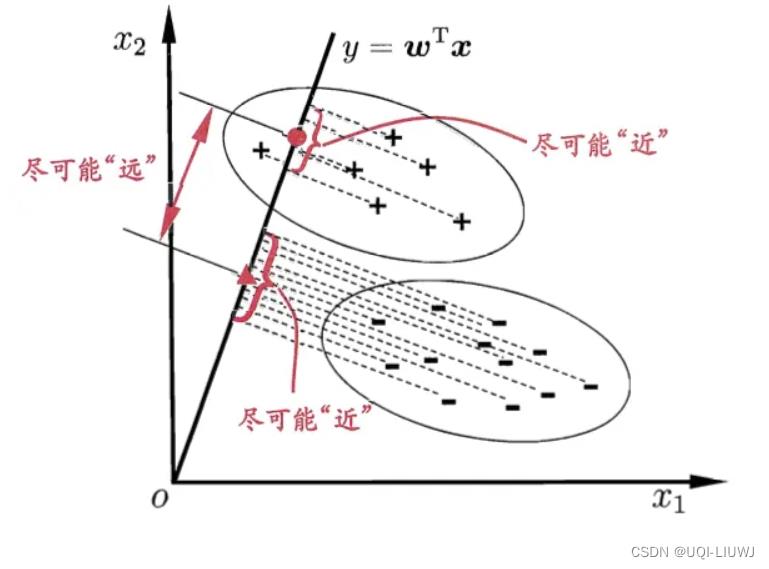
2 推导
- 我们记最佳的投影向量为w,那么一个样例x到方向向量w上的投影可以表示为:
- 给定数据集
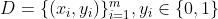
- 令
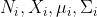 分别表示第i类的样本个数、样本集合、均值向量和协方差矩阵
分别表示第i类的样本个数、样本集合、均值向量和协方差矩阵 
- ——>在投影上的均值是

- ——>在投影上的均值是
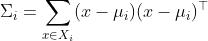 '
'
- ——>在投影上的协方差是

- ——>在投影上的协方差是
- 令
- 我们希望两个类尽可能地远,类内部尽可能地近
- ——>在投影上两个类的均值差距越大越好
 越大越好
越大越好- 记类间散度矩阵
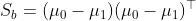 (between)
(between) - 则

- ——>在投影上同一类的均值接近
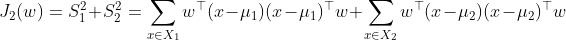
 越小越好
越小越好- 记类内散度矩阵
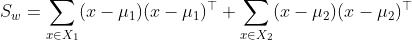 (within)
(within) 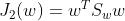
- 将J1(w)和J2(w)的要求合并在一块,有:
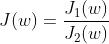 越大越好
越大越好
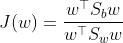
- 上式又称为Sb和Sw的广义瑞利商
- ——>在投影上两个类的均值差距越大越好
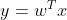
3 确定w
- w是一个向量,我们只需要知道它的方向即可。向量的模任何大小是都可以的【(a,b)和(ka,kb)都是合理的向量】
- 所以我们一定可以找到一个w,使得
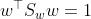
- 于是我们的目标函数变成
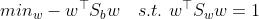
- 使用拉格朗日乘子法,有:


 是一个标量,所以
是一个标量,所以 的方向和
的方向和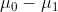 的方向相同/相反
的方向相同/相反- 我们记

- 于是
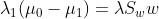
- 所以
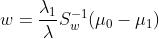
- 对于w,其向量长度可以任意,只要知道他的方向即可,所以我们把前面的λ1/λ去掉,于是有:
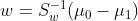
- 也就是说,通过原始样本两个类的均值和方差,就可以确定最佳的投影方位
- 使用拉格朗日乘子法,有:
4 sklearn
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
y = np.array([1, 1, 1, 2, 2, 2])
clf = LinearDiscriminantAnalysis()
#n_components是一个参数,设置降维至多少
#如果这个参数没有设置,那么就默认是min(n_classes-1,n_features)
clf.fit(X, y)
参考内容:LDA线性判别分析 - 知乎 (zhihu.com)
以上是关于机器学习&sklearn笔记:LDA(线性判别分析)的主要内容,如果未能解决你的问题,请参考以下文章