Python requests爬取今日头条,为啥获取不了网页内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python requests爬取今日头条,为啥获取不了网页内容相关的知识,希望对你有一定的参考价值。
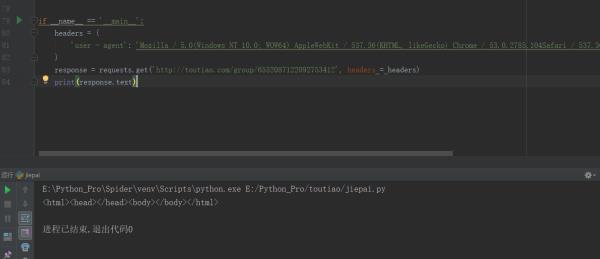
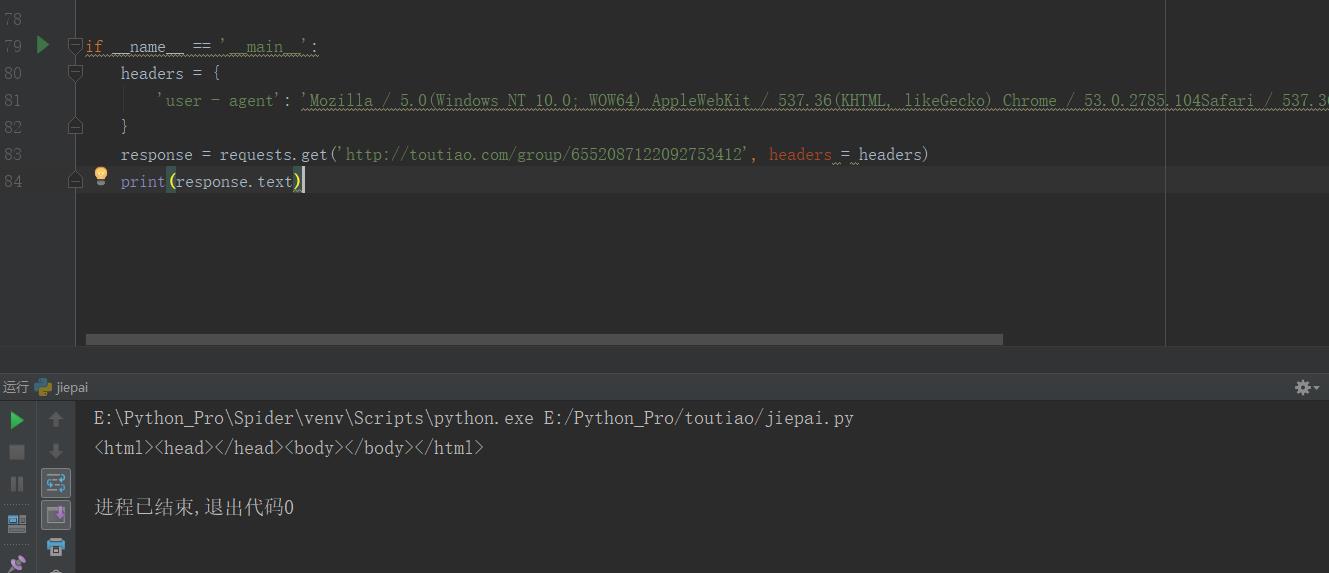
headers =
'user - agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(Khtml, likeGecko) Chrome / 53.0.2785.104Safari / 537.36Core / 1.53.4882.400QQBrowser / 9.7.13059.400'
response = requests.get('http://toutiao.com/group/6552087122092753412', headers = headers)
print(response.text)
-------------------------------------------------------------------------
得到的结果:
---------------------------------------------------------------------------
E:\Python_Pro\Spider\venv\Scripts\python.exe E:/Python_Pro/toutiao/jiepai.py
<html><head></head><body></body></html>
进程已结束,退出代码0
-----------------------------------------------------------------
求大神解答,是因为这个网页有反爬虫机制吗?我需要怎么破解。。萌新求大神指导

感觉并没有什么反爬吧,照着你的写明明可以获取图片呀

也不大可能是requests的版本问题吧,我2.12.4都可以额~
额。这就奇怪了?我这print(response.text),显示不了网页源代码,只能显示
<html><head></head><body></body></html>,导致后面要爬取图片直接报错。
以上是关于Python requests爬取今日头条,为啥获取不了网页内容的主要内容,如果未能解决你的问题,请参考以下文章
python多线程爬取-今日头条的街拍数据(附源码加思路注释)