使用Spark SQL 探索“全国失信人数据”
Posted ZeroTeam_麒麟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Spark SQL 探索“全国失信人数据”相关的知识,希望对你有一定的参考价值。
“全国法院失信被执行人名单”,网址:http://shixin.court.gov.cn/,可供查询,用于惩罚失信人员。数据量有100多万,也算是大数据了。其中身份证号已被处理,并不能直接看到全部号码。本人承诺不将此数据用于非法用途和不正当用途,仅作为个人学习数据处理分析的数据源,不针对任何个人和组织。
数据字段如下:
被执行人姓名/名称
性别
年龄
身份证号码/组织机构代码
法定代表人或者负责人姓名
执行法院
省份
执行依据文号
立案时间
案号
做出执行依据单位
生效法律文书确定的义务
被执行人的履行情况
失信被执行人行为具体情形
发布时间
关注次数
数据保存为JSON格式,比如:
"id":1000000,"iname":"潘靖","caseCode":"(2014)鄂京山执字第00035号","age":23,"sexy":"男","cardNum":"4208211992****4513","courtName":"京山县人民法院","areaName":"湖北","partyTypeName":"580","gistId":"(2012)鄂京山道字第162号民事判决书","regDate":"2014年02月24日","gistUnit":"湖北省京山县人民法院道交法庭","duty":"被告赔偿原告款401700元。","performance":"全部未履行","disruptTypeName":"其他有履行能力而拒不履行生效法律文书确定义务","publishDate":"2015年03月23日"
失信人数据分为个人、机构。
为了能够方便将统计结果图表化,还是采用Zeppelin notebook来处理。
读入数据:
val json_text = sqlContext.jsonFile("/home/zhf/Downloads/shixin_person.txt")
输出JSON字段:
json_text: org.apache.spark.sql.DataFrame = [age: bigint, areaName: string, businessEntity: string, cardNum: string, caseCode: string, courtName: string, disruptTypeName: string, duty: string, gistId: string, gistUnit: string, id: bigint, iname: string, partyTypeName: string, performance: string, performedPart: string, publishDate: string, regDate: string, sexy: string, unperformPart: string]
将表缓存以便后续快速查询:
json_text.registerTempTable("shixinren")
sqlContext.cacheTable("shixinren")
总记录数:
%sql select count(*) from shixinren
1,415,577
机构数量:
#粗略地把名字长度大于5的认为是机构
%sql select count(*) from shixinren where length(iname) >= 5
200,513
其余的都认为是个人。
年龄分布:
%sql select age,count(*) from shixinren group by age order by age
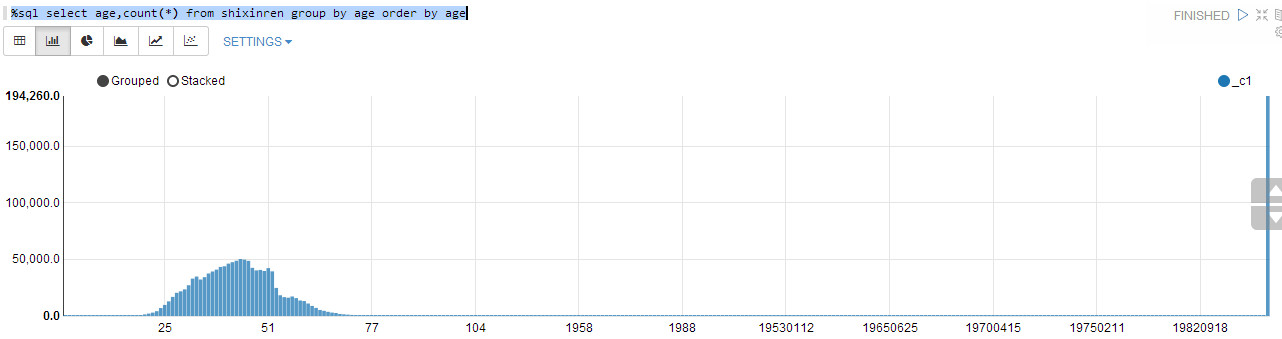
可见,发生纠纷的人主要是成年人,中年人占大多数。数据也有一些问题,可能是数据在填写时候的失误。
性别分布:
%sql select sexy,count(*) from shixinren group by sexy
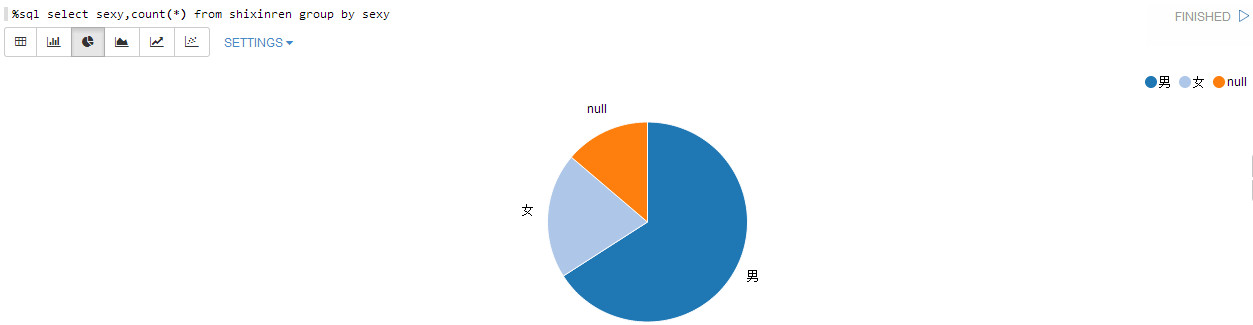
男性较多啊,男性从时候经济活动的比较多。还有部分缺失性别的数据。
省份分布:
%sql select areaName,count(*) c from shixinren group by areaName order by c desc
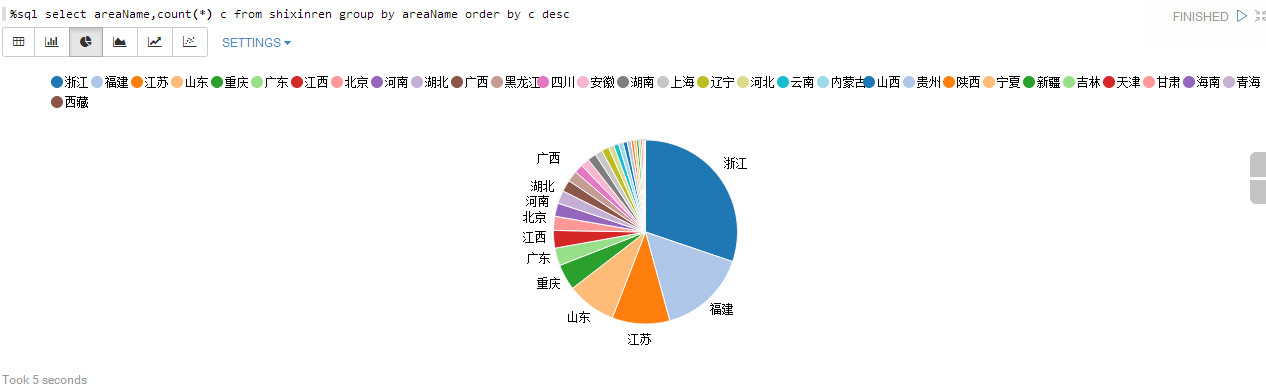
发生纠纷的主要是经济大省和人口大省,一方面这些地方的经济行为较多,另一方面这些地方的人法律意识较强(被告的法律意识不够强啊)。
处理案件最多的前10个法院:
%sql select courtName,count(*) c from shixinren group by courtName order by c desc limit 10
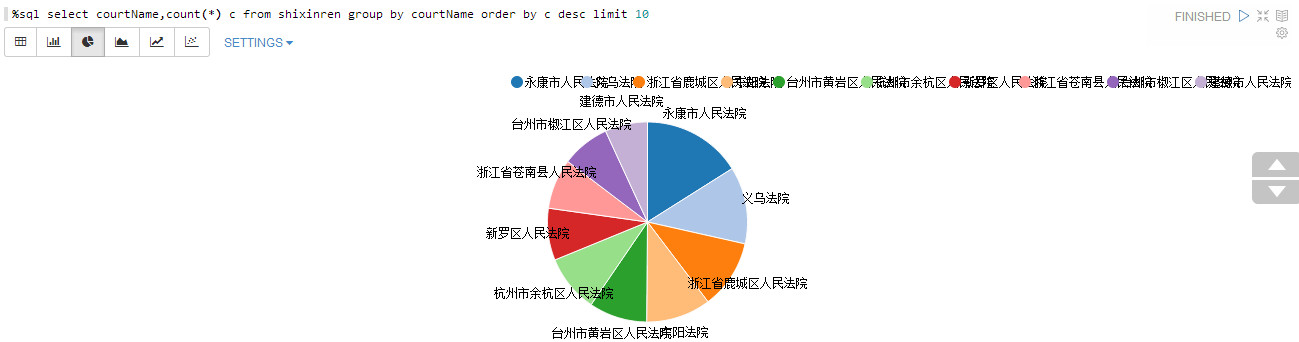
好像都是浙江的法院,然并卵啊。
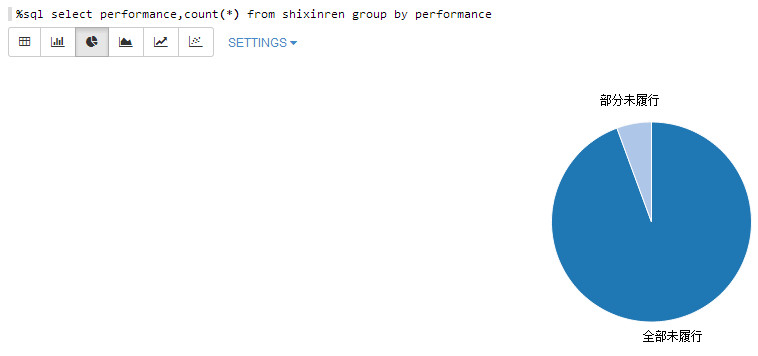
责任履行情况:
%sql select performance,count(*) from shixinren group by performance
不履行责任的原因:
%sql select disruptTypeName,count(*) c from shixinren group by disruptTypeName order by c desc limit 10
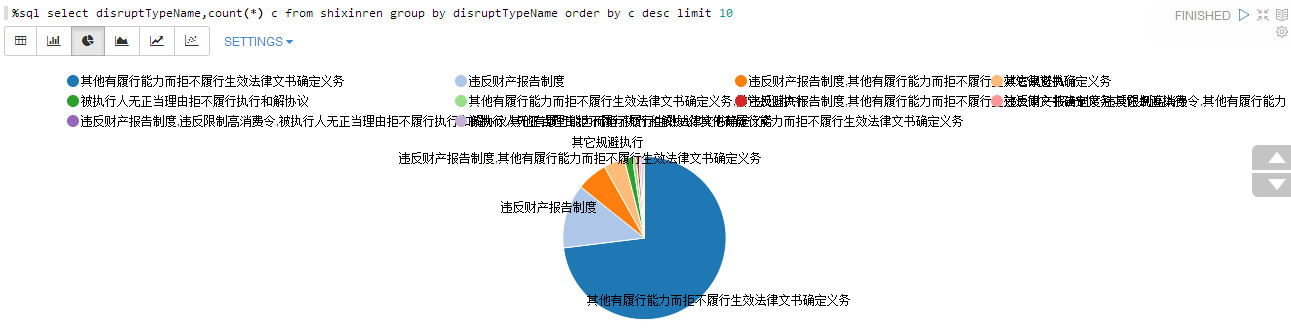
看来不履行法院判定的责任并不是没有能力啊。
不履行责任的姓氏TOP20:
%sql select substr(iname,0,1),count(*) c from shixinren where length(iname) <3 group by substr(iname,0,1) order by c desc limit 20
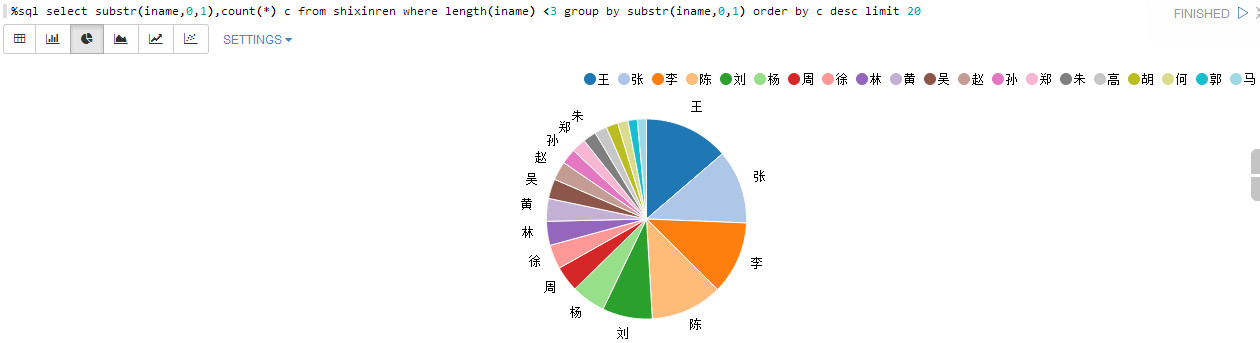
为了方便,不统计复姓。排前的都是常见的姓氏。
法院立案的年份:
%sql select substr(regdate,0,4),count(*) c from shixinren group by substr(regdate,0,4)
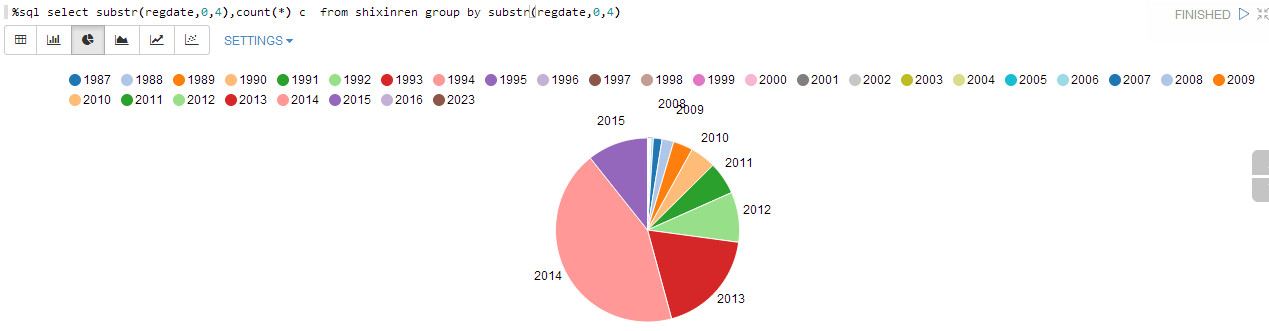
近年来数量逐步增加,可不是好事啊。同样数据有少量错误。
立案月份分布:
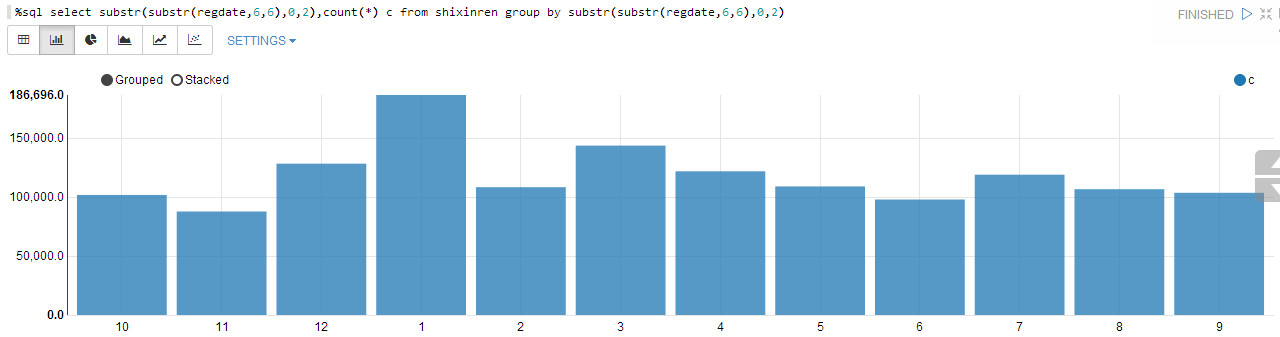
%sql select substr(substr(regdate,6,6),0,2),count(*) c from shixinren group by substr(substr(regdate,6,6),0,2)
全年分布均匀,1月份最多,可能是到年头了,还不还款,只好到法院解决(没想到最后还是没能解决!)。
一个人/机构多次作为被告的情况:
#姓名、证件号码一致就认为是同一个被告了
%sql select count c from shixinren group by iname,cardNum having c>1)t
187,020
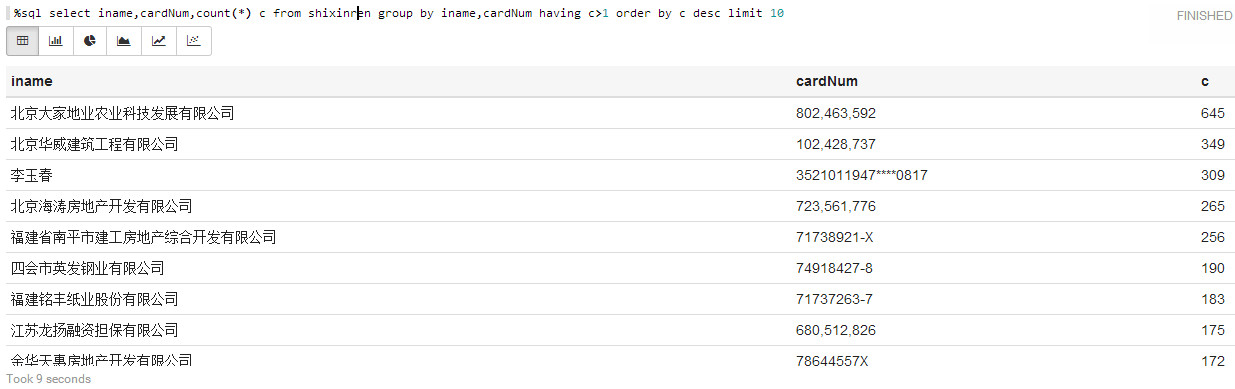
前10:
%sql select iname,cardNum,count(*) c from shixinren group by iname,cardNum having c>1 order by c desc limit 10
竟然有这么多,这种时候主要还是公司,但也有“牛人”啊。
其中,案件的【生效法律文书确定的义务】如果通过分词,再统计词频,就可以知道哪些事件发生欠款的比较多了,用SQL的话,需要写UDF来分词,这里就不处理了。
转载地址:http://lib.csdn.net/article/spark/63646
以上是关于使用Spark SQL 探索“全国失信人数据”的主要内容,如果未能解决你的问题,请参考以下文章