重新认识Hive
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重新认识Hive相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
说起Hive这个曾经叱咤风云的大数据数仓分析平台(好像现在依然老骥伏枥) ,可谓无人不晓,但是如果现在让你们重新选择一项数据仓库分析平台,恐怕无人再去选择它她,毕竟Spark、Impala、Kylingence、Presto、Trino、Clickhouse、Starrocks等才是当红明星,谁还会正眼看她一眼呢?
回头看当时的Hadoop、Hive生态现在被新兴技术挖墙脚,挖的还剩下什么:
MapReduce计算框架被Spark、Flink替代;
HDFS被对象存储替代,开源的对象存储系统有MinIo、商业版的有S3、OSS、OBS等;
YARN资源调度框架已经让位于Mesos、Kubernetes等;
Hive分析查询被Impala、Kylingence、Presto、Trino取代,当然也有企业尝试应用Flink做OLAP。另外 DorisDB、StarRocks、Clickhouse、Snowflake等更不用说。
好像就剩下一个元数据系统:Hive metastore。
我们再看 Hadoop、Hive在吃红利的这些年,新兴技术都在干什么:
Spark 推出了基于RDD的内存计算模型,相比Hive MapReduce计算框架性能呈数量级的提升,同时基于微批实现了流计算能力;
Flink 泛化了Spark的微批计算范式,除了支持流计算能力,还统一了流批一体,通过Tablestore集成了数据存储;
DorisDB、StarRocks、Clickhouse等通过自立门户,在自家存储的基础上针对性优化,进行极致查询性能提升;impala、Presto、Trino 绕过Mapreduce,直接对接元数据和HDFS,通过内存 Pipeline 达到快速交互式查询的目标,同时支持跨数据源的联邦查询;
那Hive是不是湮灭了?瘦死的骆驼比马大,Hive的影响力也还是在的,她的客户遍布大大小小的企业中,使得Spark、Flink、Impala、Trino等在不断地开疆拓土中仍不得不给她几分颜面-向其靠拢。
再看看Hive为维持庞大基业,如何续命的:
为了提升Mapreduce计算性能,Hive 支持了 tez;
Hadoop 除了支持HDFS,也支持了S3、OSS、OBS等(多亏了友商的赞助);
Hive 打不过 Spark,那就直接拥抱Spark,Hive执行引擎可以选配spark作为内置计算引擎;
Kafka、Spark、Flink 拥有了流,Hive也有了 Hive Streaming;
Spark、Flink、Trino支持了多数据源connector,Hive也有了类似八爪鱼的触角-HiveStorageHandler;
Flink 1.16支持了Hive SQl,并在Hive sql中支持了Streaming(Hive得叩谢Flink了)
Hive 支持了 Iceberg(Hive做了正确的事)
上面基本都是续命的大招,但是有些招,比如 :计算引擎支持 tez,计算模式支持Streaming,这些招是否有效果,用户是否买账,还不好说。但有几个招,很值得叫好:
1 拥抱Spark,计算引擎支持spark,相当于把Spark纳入Hive的麾下,Spark直接为Hive打工,想试用Spark的用户几乎无成本的切入Spark,这招可谓是事半功倍。同样的,Flink支持了Hive SQL,使得用户在不迁移HQL的情况下 享受了Flink的流式计算能力,这个效果是Flink免费送的,Hive 最好顺势将这一大礼集成过来。
2 Hive支持多数据源
这相当于补齐了Hive的传统短板,毕竟Hive天生设计就是在HDFS上,也许是受到了新框架的刺激,HiveStorageHander顺势拿下了MongoDB、ES、Casandra、Kudu、mysql、Druid、Kafka、Hbase、Iceberg等:
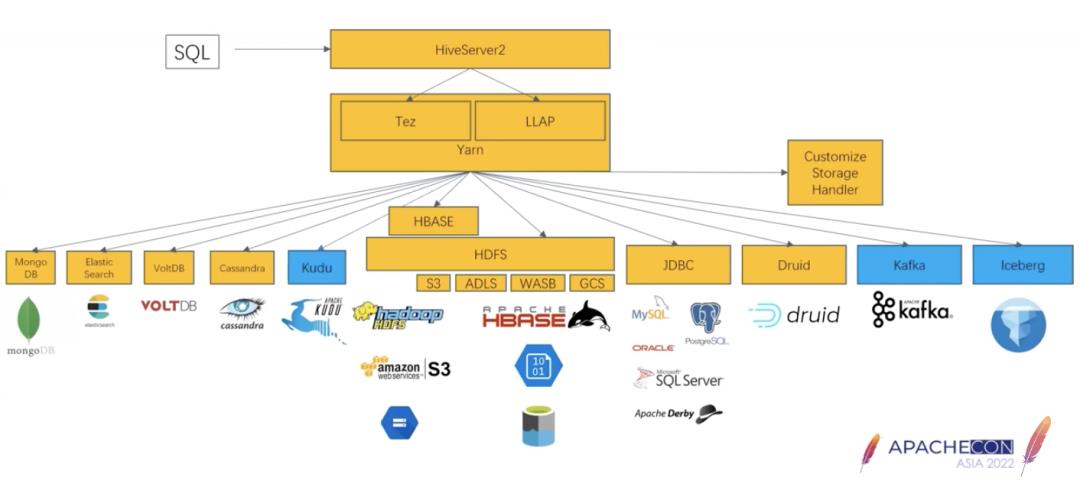
有了多数据源的支持,Hive也可以做联邦查询了,特别是在数仓建模上,不仅扩大了数据来源的范围,而且也不必将全部数据源数据都同步到数仓,减轻了ETL的压力,提升了数仓的效率。
但是目前对这些数据源的支持还很不完善,特别是联邦查询如果是做批计算,Hive慢点就慢点,但是如果是做交互式查询,那Hive需要做的事情就多了,想要补上Trino的能力,不是一朝一夕,所以明智的做法,Hive还是应该像集成Spark、Flink那样,直接拥抱Trino:Hive on Trino。
如此一来,同一套Hive sql语法,可以同时支持Spark、Flink、Trino计算引擎,用户爽得不要不要的~
3 支持数据湖Iceberg
不要小看了Iceberg,它可是社区送给Hive的最重磅的礼物,因为湖才是未来,而且Hadoop的基业就是湖,用户已经接受了数据入Hive湖的习惯认知,如果某项技术不支持湖,在用户眼里就已经偏离了主流,比如Druid、DorisDB、Clickhouse等,如果不支持湖,可能就要成为少数有钱的主的特供了。
Iceberg虽然只是一个jar包,对现有Hive毫无代码侵入性,可谓是即插即拔。Iceberg作为数据湖的技术之一,对Hive现有的技术可谓是既“破”又“立”:破的是HDFS不支持事务更新,“立”的是在HDFS(包括对象存储)基础上新的表存储格式。本来Hadoop勉强也称得上是数据湖技术,无奈它存在过多的致命伤,这次好了,Iceberg直接给Hive移植了新的“心脏”-存储。
对Hive来讲,当前做的仍然应该是 欣然接受,并且 顺势 收了Hudi、Delta lake。
还记得我在《大数据平台到底该如何设计?》这篇文章中给出的大数据平台设计准则吗:
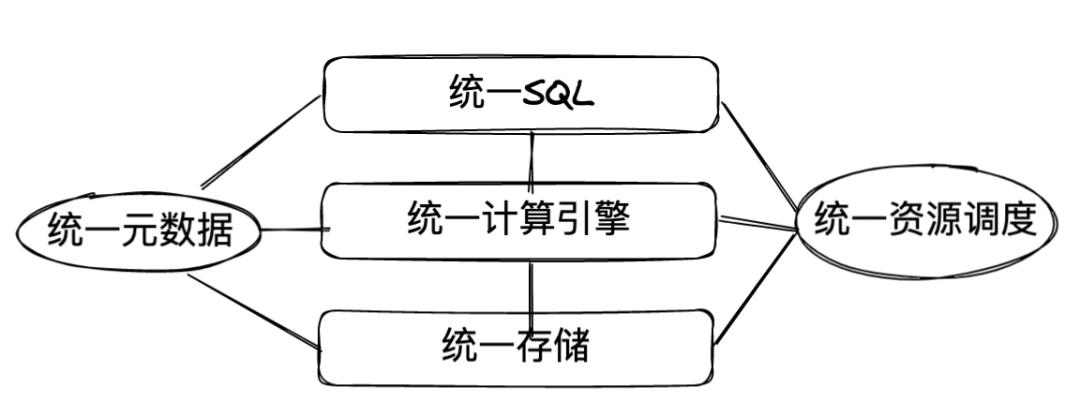
如果Hive能够做到以上,那么Hive就是当之无愧的超级统一大平台,集 统一SQL、统一计算引擎、统一存储于一身,关键是有自家的HiveMetastore啊,以及众多忠实的用户,这是目前Hive最值钱的资产了。
试问,Hive一统江湖,谁与争锋?
Spark?Flink?Trino?能统一SQL吗?假设能统一SQL,能统一引擎吗?
Apache Kyubbi?
一起来看看Kyuubi的部署方式:主要是在其部署目录下$KYUUBI_HOME/conf/kyuubi-env.sh 中设置计算引擎代码包HOME,以及当前引擎类型:kyuubi.engine.type。
比如,如果设置Spark为当前计算引擎,只需要配置:
SPARK_HOME=~/Downloads/spark-3.2.0-bin-hadoop3.2如果设置Flink为当前计算引擎,需要配置:
FLINK_HOME=/Downloads/flink-1.15.1
kyuubi.engine.type FLINK_SQL如果设置Trino为当前计算引擎,除了提供Trino客户端包外,还需要以下配置:
kyuubi.engine.type TRINO
# Your trino cluster server url
kyuubi.session.engine.trino.connection.url http://localhost:8080
# The default catalog connect to
kyuubi.session.engine.trino.connection.catalog hive
其他配置信息则需要配置在:$KYUUBI_HOME/conf/kyuubi-defaults.conf
部署Kyuubi之后,就可以使用Hive兼容的Beelione工具连接使用了:
bin/beeline -u 'jdbc:hive2://localhost:10009/关于Kyuubi的更多信息可以参考:
https://kyuubi.readthedocs.io/en/v1.6.1-incubating/quick_start/quick_start.html
从其部署和使用方式可知,Kyuubi的一个部署实例,只能使用一种计算引擎,输入的SQL语法是当前引擎对应的SQL,不能够动态切换SQL引擎。不管怎么样,能做到这点,已经很令人兴奋了。另外,Kyuubi宣称支持多租户,这可是企业级的服务产品啊。再看看Hive,连数据目录Catalog都支持不好,遑论多租户,可见当时的设计人员眼界之高~
Hive具备先发优势,而且家底殷实,但是Hive革新,任重道远,最终的结局到底是凤凰涅槃还是扶不起的阿斗,我们拭目以待!
以上是关于重新认识Hive的主要内容,如果未能解决你的问题,请参考以下文章