标准化和归一化概念澄清与梳理
Posted Laurence Geng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了标准化和归一化概念澄清与梳理相关的知识,希望对你有一定的参考价值。
标准化和归一化是特征缩放(feature scalingscaling)的主要手段,其核心原理可以简单地理解为:让所有元素先减去同一个数,然后再除以另一个数,在数轴上的效果就是:先将数据集整体平移到有某个位置,然后按比例收缩到一个规定的区间内。各种特征缩放手段的不同之处在于:他们减去和除以的数字不同,这决定了它们平移后的位置和缩放后的区间。特征缩放的目的是去除数据单位(量纲)的影响,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。本文地址:https://blog.csdn.net/bluishglc/article/details/128696871,转载请注明出处。
但不得不提的是,由于翻译和命名上的歧义性以及各种误传误用,特征缩放领域里的术语和概念非常混乱,包括:标准化、正规化、正则化、归一化、Standardization、Normalization在内的这些概念既有关联又有差异,再加上它们的原始出处已基本都不可考,所以被大量混用和滥用,在一些劣质文章中会经常看到张冠李戴或相互矛盾的说法。本文我们会尽量结合字面含义和多数资料的描述,对这些概念做一轮梳理。在开始之前,我们先把梳理好的结论以表格形式展示出来,然后我们再详细梳理这些概念和分类:

首先,我们需要先统一一下中英文术语,从大量的资料来看,普遍将**“Standardization”翻译为“标准化”,将“Normalization” 翻译为“归一化”**。标准化(Standardization)的概念是非常明确的,没有任何歧义,它明确指向一个确定的算法,我们会在下文详细介绍。但归一化(Normalization)的概念就复杂了:首先,英文的Normalization本身就不是一个含义确定的术语,狭义地看,它被用于指代两种不同的算法,所以是有歧义的,下文会详细介绍,因此有的英文文章建议慎用Normalization一词。其次,它的中文翻译:归一化,其内涵已经超出了英文单词的含义范畴,而被“拓展”到了更为通用的层面上。这些细节我们都会在后面详细讨论。
简单总结一下:标准化(Standardization)可以认为是一个“狭义”的概念,它明确对应一个具体的算法,没有歧义;而归一化(Normalization)则是一个“广义”的概念,可指代多种缩放算法,如不明确说明使用的是什么缩放算法,往往会有歧义。
1. 标准化(Standardization)
在这些广泛流传的诸多术语中,标准化(Standardization)可以算是唯一一个定义明确没有歧义的概念了。它的处理逻辑是:先求出数据集(往往是一列数据)的均值和标准差,然后所有的元素先减去均值,再除以方差。由于标准化(Standardization)是按标准差(σ)缩放的,所以标准化也被叫做“标准差归一化”,所以这应该就是它名称中“标准”一词的来历(注意:使用标准化缩放后数据不一定是在[-1,1]之间,只是数据的整体标准差为1,这一点要清楚)。
由于标准化概念清晰而准确,所以不存在广义的“标准化”概念,但是某些文章会把标准化和归一化混为一谈,进而用标准化指代所有的数据缩放算法,这就不对了,只要大家能分辨出来,心里清楚就可以了。
2. 狭义的“归一化 (Normalization)”
在业界,我们会看到有部分资料会使用归一化(Normalization)指代一个具体的缩放算法,但遗憾的是大家指代的算法却是不同的,所以不像标准化,归一化没有形成统一明确的狭义概念,也就是一提到归一化时,大家就知道指的是哪个具体的算法。
不过,业界比较常见的是将“最大最小值缩放(Min-Max Scaling)”或者是“范数缩放(Norm Scaling)”称为Normalization。请注意,我们这里侧重讨论英文称谓“Normalization”,先不用“归一化”这种表述,因为这块的差异和讨论多见于英文资料,也和英文分词有些关系。
2.1 Normalization是“Min-Max归一化”?
这一说法的出处已不可考,可能是某些权威教材或书籍曾经这样定义过。在《Hands-On ML》一书(Page 72)中也明确提及Min-Max Scaling也叫Normalization;另外一种解释可能是因为标准差缩放和Min-Max缩放是两个最基本也最常用的数据缩放算法,前者使用了Standardization指代,于是就有人习惯用Normalization指代后者了。
2.2 Normalization是“范数归一化”?
这一说就更加直白了,完全是从具体的算法名引申而来。我们知道,Norm是指数学中的范数,Sklearn中有两个对数据进行范数归一的方法:分别是normalize()函数和Normalizer类,这种操作的名词自然会被称为“Normalization”,即三个术语之间的关系是:Norm -> Normalize/Normalizer -> Normalization,所以,范数归一化被叫做Normalization也是顺理成章的。
但正是由于存在上述两种流传都很广的认识,所以我们无法界定归一化(Normalization)具体对应的是哪一种缩放方法。
3. 广义的“归一化 (Normalization)”
由于大部分的特征缩放(feature scalingscaling)手段,数据经过处理之后一般都会被缩放到[0,1]或[-1,1]的区间内,所以中文使用的“归一化”这个术语能更好地体现缩放算法的本质,因而被广泛使用;同时另外一些数据缩放手段数据经处理后是某项特征值变成了1,所以也被习惯性的称之为了归一化,典型的代表就是:标准差归一化和范数归一化。目前,有明确中文称谓且使用“归一化”命名的缩放方法主要有3种,它们是:
- 标准差归一化 / Z-Score归一化 / 标准化
- Min-Max归一化
- 范数归一化
它们的中英文名称和多种别名都以在文章开始的表格中详细列出。
4. 使用无歧义的“缩放函数名/类名”交流
我们应该掌握的当然是每一种具体的缩放算法,而不是这些混乱和没有定论的概念与分类,梳理这些概念还是为了便于平时的交流,如果大家在沟通中有发现了概念不一致的情况,就应该使用具体的缩放方法名来指代。在Sklearn中有五种具体的数据缩放方法,以下是它们的函数名:
| 名称 | 方法名 | 类名 |
|---|---|---|
| 标准差归一化 / Z-Score 归一化 / 标准化 | sklearn.preprocessing.scale | sklearn.preprocessing.StandardScaler |
| Min-Max 归一化 | sklearn.preprocessing.minmax_scale | sklearn.preprocessing.MinMaxScaler |
| 范数归一化 | sklearn.preprocessing.normalize | sklearn.preprocessing.Normalizer |
| Robust Scaler(无常用别名) | sklearn.preprocessing.robust_scale | sklearn.preprocessing.RobustScaler |
| Power Transformer (无常用别名) | sklearn.preprocessing.power_transform | sklearn.preprocessing.PowerTransformer |
下图总结了这五种广义的归一化方法的计算原理和适应场景(boxcox由PowerTransformer提供支持):
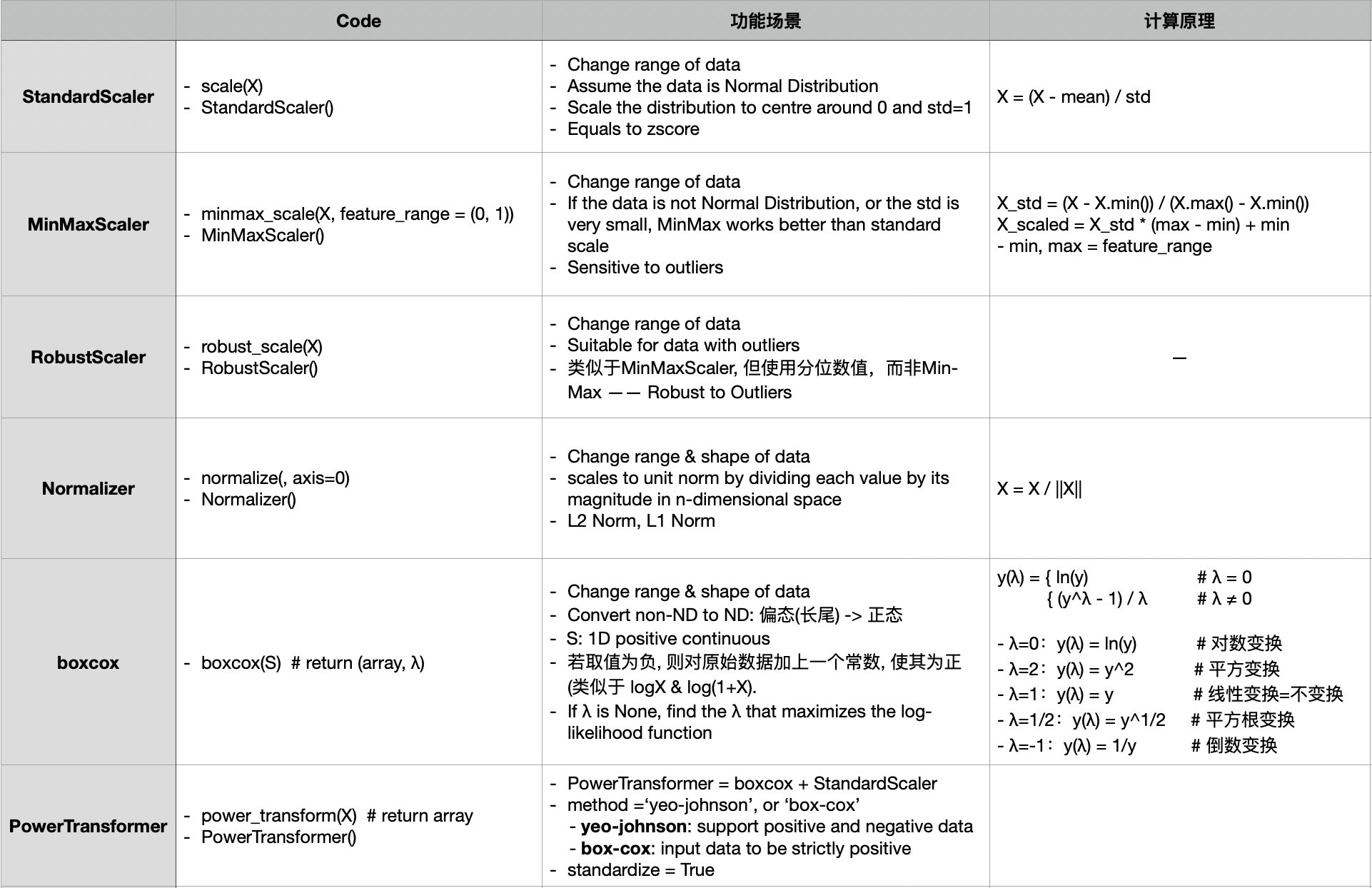
我们将在后续的文章中详细讲解和演示上述的缩放手段。
5. 总结
“标准化”没有广义和狭义之分,就是“标准差归一化”(Z-Score归一化);狭义的“归一化”一种观点认为是“最大最小值归一化”,另一种观点认为是“范数归一化”,没有形成共识,广义的“归一化”则可以泛指“所有数据缩放方法”,只要在前面加上方法名定语修饰一下即可。
参考资料:
Data mining normalization method
Feature Scaling with scikit-learn
Data normalization in machine learning
sklearn中的数据预处理和特征工程
scikit-learn数据预处理之特征缩放
机器学习:盘点最常见的7种数据预处理方法和原理
标准化和归一化什么区别?
以上是关于标准化和归一化概念澄清与梳理的主要内容,如果未能解决你的问题,请参考以下文章