三天爆肝快速入门机器学习第一天
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三天爆肝快速入门机器学习第一天相关的知识,希望对你有一定的参考价值。
三天爆肝快速入门机器学习第一天
说点想说的,来CSDN一段时间了,主要分享了一些技术文章和学习教程文章,起初纯粹是想分享一些这么多年技术上的心得,练练文笔,如果还能帮助到别人那是更好了,同时也有很多粉丝私信我怎么学习的。于是我发了一些单纯分享学习资料的文章,但是阅读量都比较低,之后在CSDN上只发布自己技术性相关的文章或者自己的一些人生感悟之类的,付费文章这块的内容后期也会打算做,因为我是做后端这块的,打算自己整理一些精品教程上传,这些都是后话了。感谢每一位的关注,与君共勉。
机器学习概述
人工智能概述
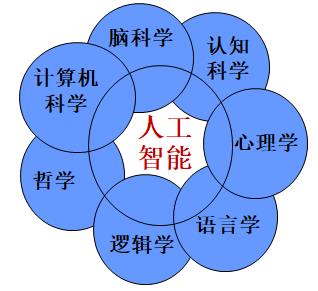
人工智能(Artificial Intelligence):它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。1956年由约翰.麦卡锡首次提出,当时的定义为“制造智能机器的科学与工程”。人工智能目的就是让机器能够像人一样思考,让机器拥有智能。时至今日,人工智能的内涵已经大大扩展,是一门交叉学科
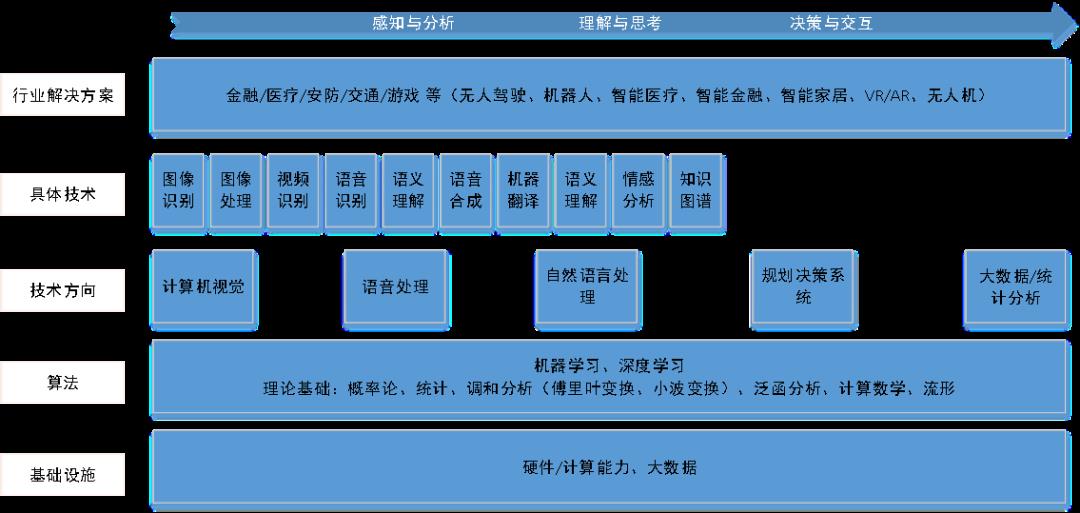
什么是机器学习
机器学习概念
机器学习就是对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。
我们举个例子,我们都知道支付宝春节的“集五福”活动,我们用手机扫“福”字照片识别福字,这个就是用了机器学习的方法。我们可以为计算机提供“福”字的照片数据,通过算法模型机型训练,系统不断更新学习,然后输入一张新的福字照片,机器自动识别这张照片上是否有福字。
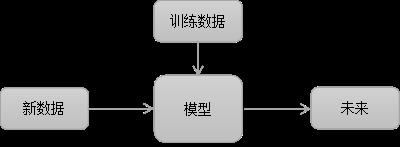
机器学习是一门多领域交叉学科,涉及概率论、统计学、计算机科学等多门学科。机器学习的概念就是通过输入海量训练数据对模型进行训练,使模型掌握数据所蕴含的潜在规律,进而对新输入的数据进行准确的分类或预测。如下图所示:
机器学习开发流程
收集数据
我们可以使用很多方法收集样本数据,例如:制作网络爬虫从网站上抽取数据、从RSS反馈或者API中得到信息、设备发送过来的实测数据(风速、血糖等)。
提取数据的方法非常多,为了节省时间与精力,可以使用公开可用的数据源。
准备输入数据
得到数据之后,还必须确保数据格式符合要求,比如使用 Python 语言的 List 类型。使用 List 这种标准数据格式可以融合算法和数据源,方便匹配操作。
机器学习一般使用 Python 作为开发语言,不了解的读者请猛击《机器学习为什么使用 Python 语言?》进行学习。
此外还需要为机器学习算法准备特定的数据格式,如某些算法要求特征值使用特定的格式,一些算法要求目标变量和特征值是字符串类型,而另一些算法则可能要求是整数类型。
但是,与收集数据的格式相比,处理特殊算法要求的格式相对简单得多。
分析输入数据
此步骤主要是人工分析以前得到的数据。为了确保前两步有效,最简单的方法是用文本编辑器打开数据文件,查看得到的数据是否为空值。
此外,还可以进一步浏览数据,分析是否可以识别出模式;数据中是否存在明显的异常值,如某些数据点与数据集中的其他值存在明显的差异。
通过一维、二维或三维图形展示数据也是不错的方法,然而大多数时候我们得到数据的特征值都不会低于三个,无法一次图形化展示所有特征。不过,使用某些提炼数据的方法,可以将多维数据压缩到二维或三维,方便我们图形化展示数据。
这一步的主要作用是确保数据集中没有垃圾数据。如果是在产品化系统中使用机器学习算法并且算法可以处理系统产生的数据格式,或者我们信任数据来源,可以直接跳过第3步。
此步骤需要人工干预,如果在自动化系统中还需要人工干预,显然就降低了系统的价值。
训练算法
机器学习算法从这一步才真正开始学习。根据算法的不同,第4步和第5步是机器学习算法的核心。
我们将前两步得到的格式化数据输入到算法,从中抽取知识或信息。这里得到的知识需要存储为计算机可以处理的格式,方便后续步骤使用。
如果使用非监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容都集中在第5步。
测试算法
这一步将实际使用第4步机器学习得到的知识信息。为了评估算法,必须测试算法工作的效果:
对于监督学习,必须已知用于评估算法的目标变量值;
对于非监督学习,也必须用其他的评测手段来检验算法的成功率。
无论哪种情形,如果不满意算法的输出结果,则可以回到第4步,改正并加以测试。
问题常常会跟数据的收集和准备有关,这时你就必须跳回第1步重新开始。
使用算法
将机器学习算法转换为应用程序,执行实际任务,以检验上述步骤是否可以在实际环境中正常工作。此时如果碰到新的数据问题,同样需要重复执行上述的步骤。
机器学习算法分类
监督学习
如果机器学习的目标是通过建模样本的特征x和标签y之间的关系:

或
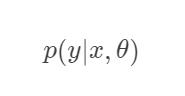
并且训练集中的每个样本都有标签,那么这类学习称之为监督学习(Supervised Learning)。根据标签类型的不同,监督学习又可以分为回归和分类两种。
回归(Regression)
回归问题中的标签y是连续值(实数或者连续整数)

的输出也是连续值。
分类(Classification)
分类问题中的标签y是离散的类别,在分类问题中,学习到的模型也成为分类器(Classifier)。分类问题根据其类别的数量又可以分为二分类(Binary Clssification)和多分类(Mutil-class Classification)。
机构化学习(Structured Learning)
结构化学习的输出对象是结构化的对象,比如序列、树、图等,由于结构化学习的输出空间比较大,因此我们一般定义一个联合特征空间,将x,y映射为该空间中的联合特征向量(x,y),预测模型可以写为:
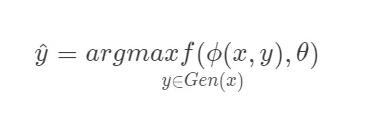
其中gen(x)表示x所有可能的输出目标集合。计算arg max的过程也称为解码(decoding)过程,一般通过动态规划的方法来计算。
无监督学习
无监督学习(Unsupervised Learning)是指从不包含目标标签的训练样本中自动学习到一些有价值的信息。典型的无监督学习问题有聚类、密度估计、特征学习、降维等。
强化学习
强化学习(Reinforcement Learning)是一类通过交互来学习的机器学习算法。在强化学习中,智能体根据环境的状态作出一个动作,并得到即时或延时的奖励。智能体在和环境的交互中不断学习并调整策略,以取得最大化的期望总回报。
下表给出了三种机器学习类型

监督学习需要每个样本都有标签,而无监督学习则不需要标签。一般而言,监督学习通常大量的有标签数据集,这些数据集是一般都需要由人工进行标注,成本很高。因此,也出现了很多弱监督学习(Weak Supervised Learning)和半监督学习(Semi-Supervised Learning)的方法,希望从大规模的无标注数据中充分挖掘有用的信息,降低对标注样本数量的要求。强化学习和监督学习的不同在于强化学习不需要显式地以“输入/输出对”的方式给出训练样本,是一种在线的学习机制。
特征工程
数据集
数据集由数据对象组成,一个数据对象代表一个实体
属性(attribute)是一个数据字段,表示数据对象的一个特征。属性向量(或特征向量)是用来描述一个给定对象的一组属性。
属性的分类:
标称属性(nominal attribute)
二元属性(binary attribute)
序数属性(ordinal attribute)— 常量表中的某个值
数值属性(numerical attribute)= 离散属性 + 连续属性
数据清洗
清洗标注数据,主要是数据采样和样本过滤
数据增强( Data Augmentation)
数据增强是指从给定数据导出的新数据的添加
如CV领域中的图像增广技术
预处理
缺失值的处理
(1)丢弃
(2)均值
(3)上下数据填充
(4)插值法 线性插值
(5)随机森林拟合
标准化和归一化
标准化
标准化是依照特征矩阵的列处理数据,使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1
基于正态分布假设
标准化后可能为负
(X-X_mean)/std
归一化
对每个样本计算其p-范数,再对每个元素除以该范数,这使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
区间缩放法
常见的一种为利用两个最值进行缩放
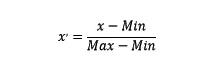
具有加速收敛的作用,原因如下图:
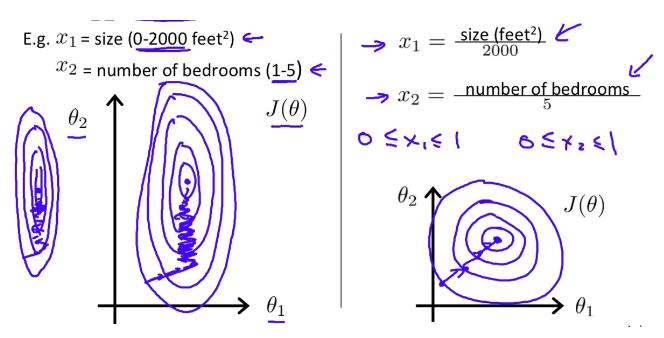
可以使用sklearn中的preproccessing库来进行数据预处理
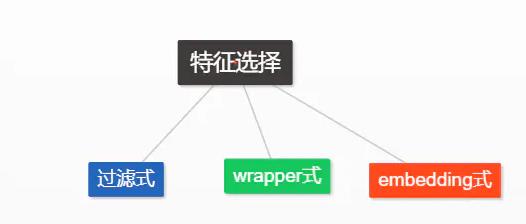
选择
定义: 从给定的特征集合中选择出相关特征子集的过程
两个关键问题:
子集搜索
forward搜索: 逐渐增加相关特征的策略
backward搜索:逐渐减少特征的策略
bidirectional搜索
子集评价
特征选择方法 = 子集搜索机制 + 子集评价机制
特征选择的作用
减少(冗余)特征数量、降维,使模型泛化能力更强,减少过拟合
增强对特征和特征值之间的理解
去噪
降维
定义:通过某种数学变化将原始高维属性空间转变为低维子空间(subspace)
低维嵌入(三维–>二维):

降维方法分类
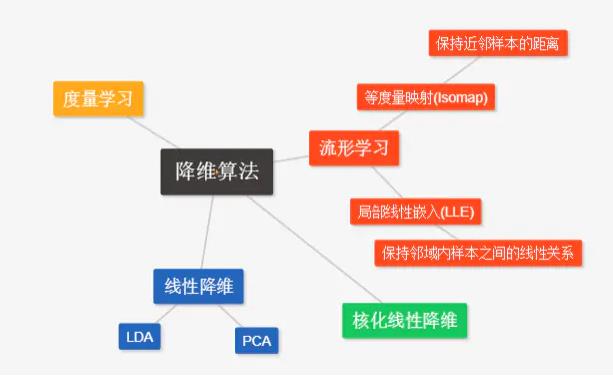
个人总结
这一周打算更新机器学习这个系列的,预计出三篇机器学习入门的文章,相信大家看了这三篇文章会对机器学习会有深入的了解,初次接触写文章,对于排版内容什么的都有很大进步的空间,大家有什么建议都可以在评论中留言,同时大家对哪一块的技术感兴趣,我后期也会出相关的文章,感谢朋友们的关注,持续更新中。
以上是关于三天爆肝快速入门机器学习第一天的主要内容,如果未能解决你的问题,请参考以下文章