set的常见用法详解
Posted 辉小歌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了set的常见用法详解相关的知识,希望对你有一定的参考价值。
目录
set翻译为集合,是一个内部自动有序且不含重复元素的容器。在考试中,有可能出现需要去掉重复元素的情况,而且有可能因这些元素比较大或者类型不是int型而不能直接开散列表,在这种情况下就可以用set来保留元素本身而不考虑它的个数。当然,上面说的情况也可以通过再开一个数组进行下标和元素的对应来解决,但是set提供了更为直观的接口,并且加入set之后可以实现自动排序,因此熟练使用set可以在做某些题时减少思维量。
需要的头文件:
#include<set>
需要的其他东西:
using namespace std;
set的定义
set定义的格式:
set<typename> name;
其定义的写法其实和vector基本是一样的,或者说其实大部分STL都是这样定义的。
这里的typename依然可以是任何基本类型,例如int, double, char、结构体等,
或者是STL标准容器,例如vector, set, queue等。
和前面vector中提到的一样,如果typename是一个STL容器,那么定义时要记得在>>符号之间加上空格,
因为一些使用C++ 11之前标准的编译器会把它视为移位操作,导致编译错误。
下面是一些简单的例子:
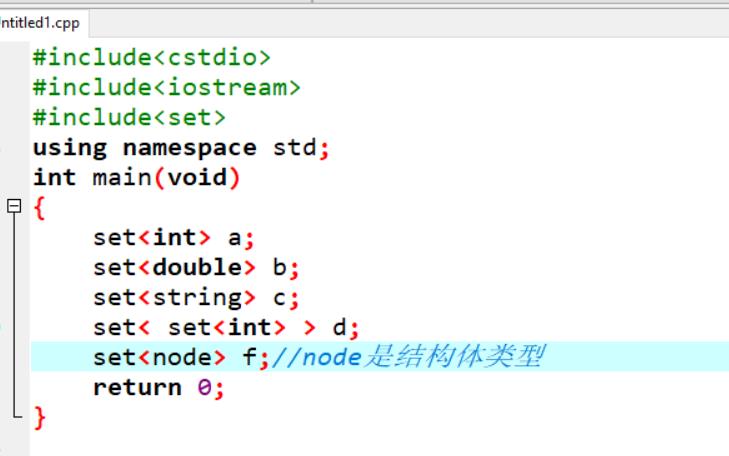
set数组的定义和vector相同:
set<typename> Arrayname[arraySize];
例如:
set<int> a[100];
这样Arrayname[0] ~ Arrayname[ arraySize -1 ]中的每一个都是一个set容器。
set容器内元素的访问
set只能通过迭代器(iterator)访问:
set<typename>:: iterator it;
typename就是定义set时填写的类型,下面是typename为int和char的举例:
set<int>::iterator it;
set<char>::iterator it;
这样就得到了迭代器it,并且可以通过*it来访问set里的元素。
由于除开vector和string之外的STL容器都不支持 * ( it + i )的访问方式,
因此只能按如下方式枚举:

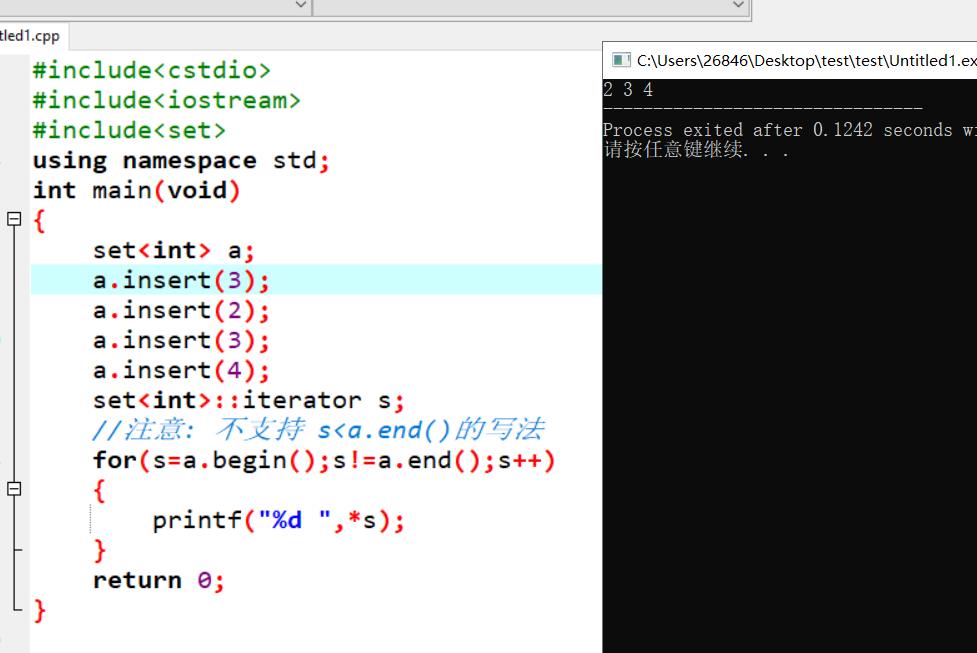
可以发现,set内的元素自动递增排序,且自动去除了重复元素
set常用函数实例解析
(1)insert()
insert(x)可将x插入set容器中,并自动递增排序和去重,时间复杂度为O(logN),其中N为set内的元素个数
(2)find()
find(value)返回set中对应值为value的迭代器,时间复杂度O(logN),其中N为set内的元素个数。

(3)erase()
erase()有两种方法: 删除单个元素、删除一个区间内的所有元素。
①删除单个元素
st.erase(it) ,it为需要删除元素的迭代器。时间复杂度为O(1)。可以结合find()来使用
案例如下: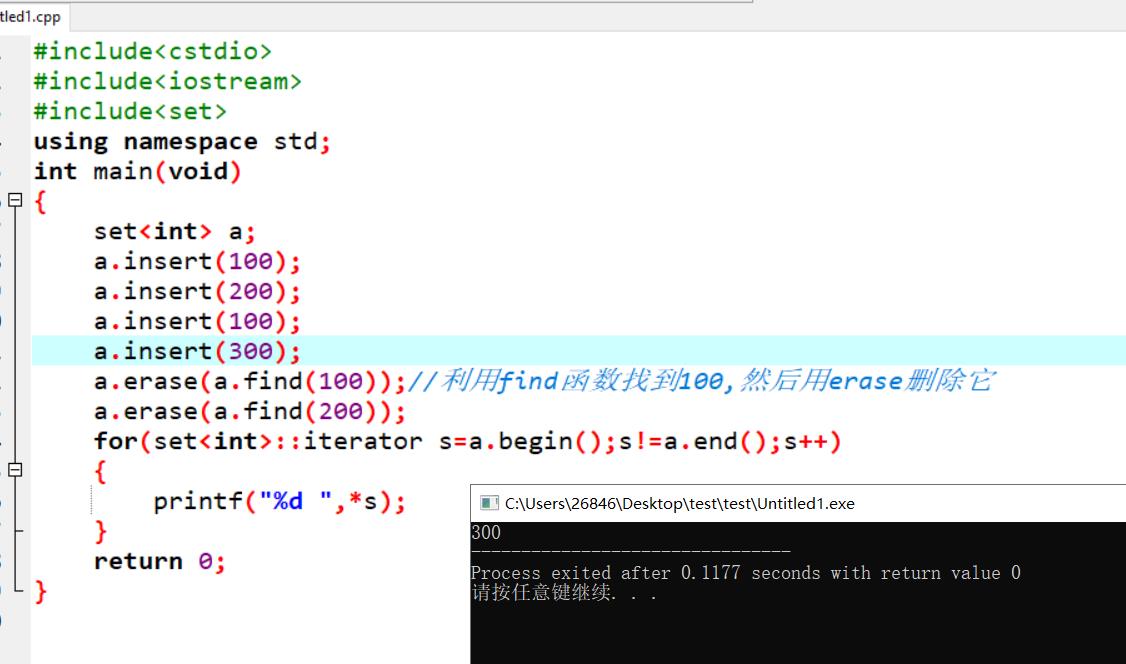 st.erase(value),value为所需要删除元素的值。时间复杂度为O(logN),N为set内的元素个数。
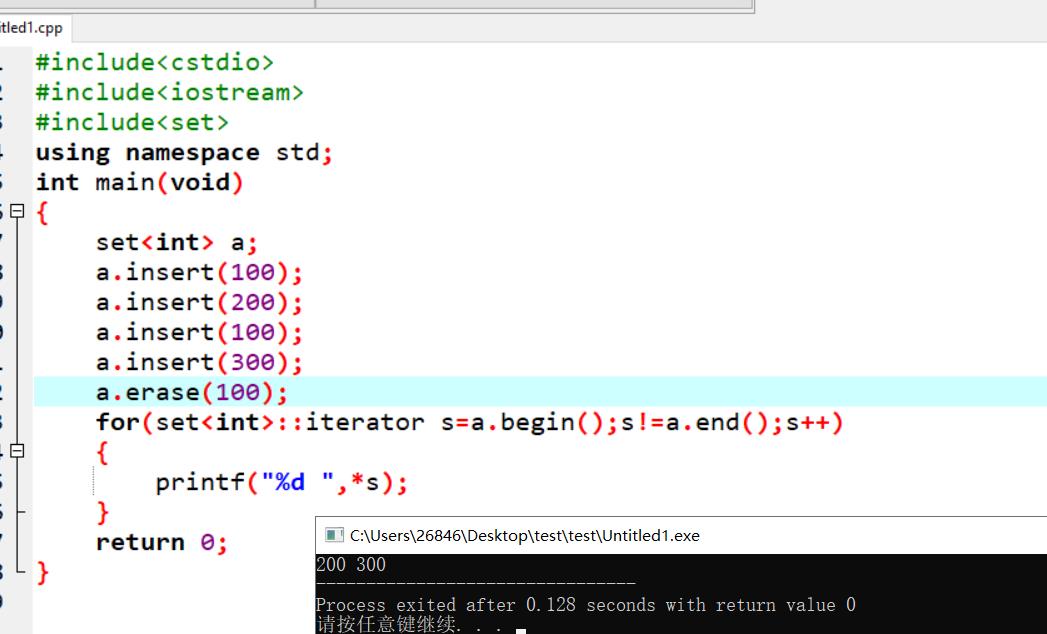
st.erase(value),value为所需要删除元素的值。时间复杂度为O(logN),N为set内的元素个数。
实例如下:
②删除一个区间内的所有元素
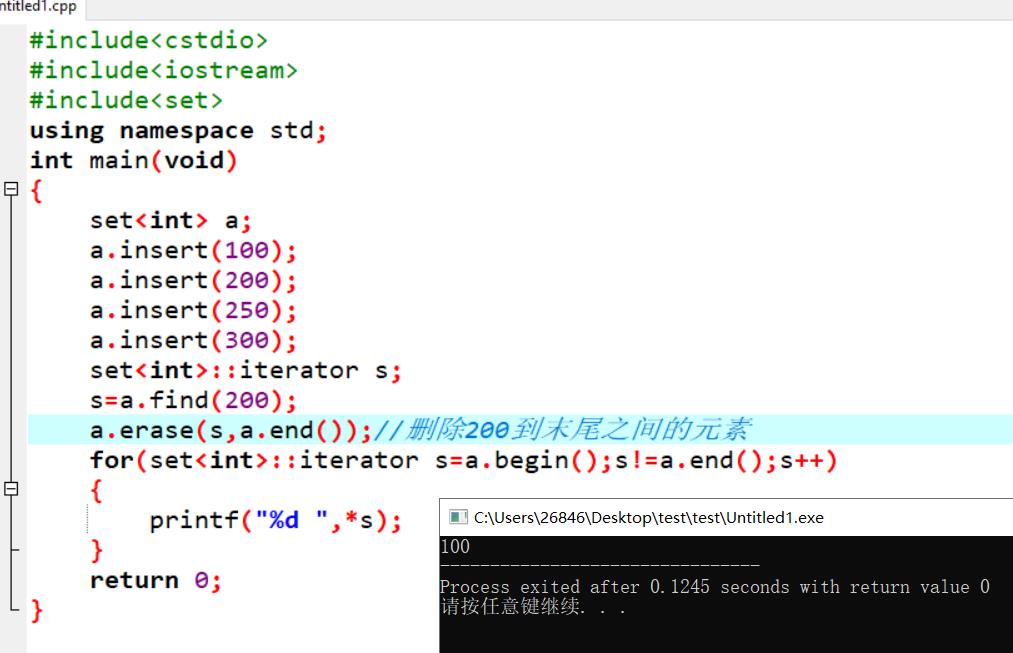
st.erase(first,last)可以删除一个区间内的所有元素,其中first为所需删除区间的起始迭代器,而last则为所需要删除区间的末尾迭代器的下一个地址,即删除 [ first , last) 内的所有元素。时间复杂度为 O( last - first )。
(4) size()
size()用来获得set内元素的个数,时间复杂度为O(1)。

(5) clear()
clear()用来清空set中的所有元素,复杂度为O(N),其中N为set内元素的个数。

set的常见用途
set最主要的作用是自动去重并按升序排序,因此碰到需要去重但是却不方便直接开数组的情况,可以尝试用set解决。
延伸: set中元素是唯一的,如果需要处理不唯一的情况,则需要使用multiset。另外C++ 11标准中还增加了unordered_set,
以散列代替set内部的红黑树(Red Black Tree,一种自平衡二叉查找树)实现,使其可以用来处理只去重但不排序的需求,速度比set要快得多,有兴趣的读者可以自行了解,此处不多作说明。
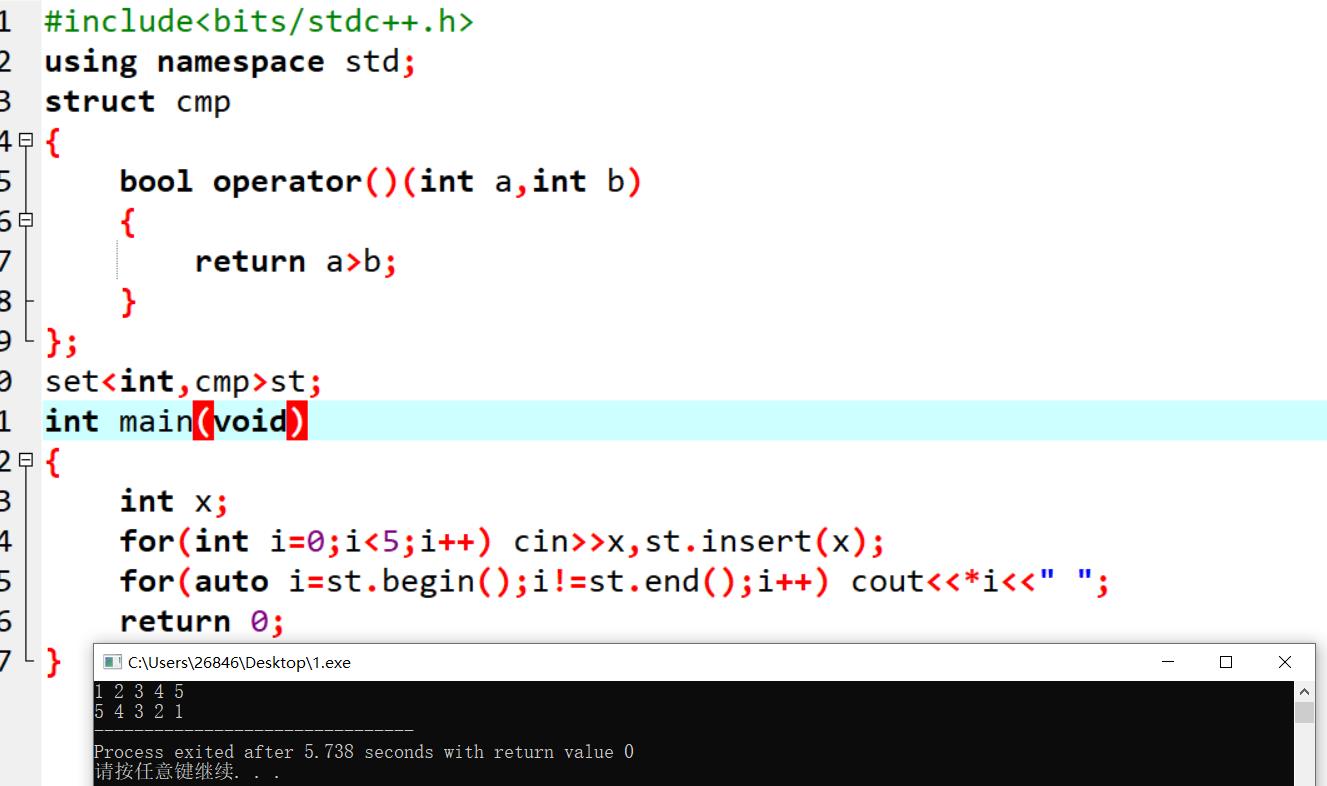
set自定义比较规则
以上是关于set的常见用法详解的主要内容,如果未能解决你的问题,请参考以下文章