[ Druid ] 源码拆解 —— 1. 初始化过程的全局概览
Posted 削尖的螺丝刀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[ Druid ] 源码拆解 —— 1. 初始化过程的全局概览相关的知识,希望对你有一定的参考价值。
说到数据库连接池,一定绕不过的坎就是 JDBC, 本文对源码的拆解阅读,默认读者已经了解JDBC,此处只做简单概括,略微回忆,如果已经掌握请直接跳至 Druid 源码(基于1.2.9) 的拆解部分:
JDBC (全称: Java Database Connectivity)
—— 它代表了 Java数据库连接,是你代码逻辑到一切数据库的直接桥梁,我们可以简单鸟瞰一下JDBC的架构和对应的API核心组件
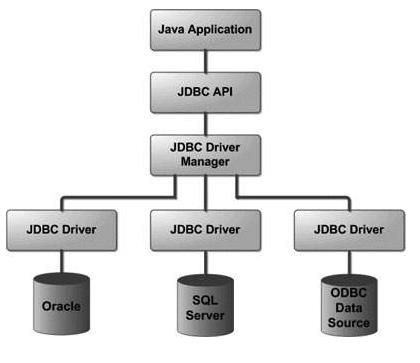
JDBC API提供以下接口和类 :
- DriverManager:此类管理数据库驱动程序列表。 使用通信子协议将来自java应用程序的连接请求与适当的数据库驱动程序进行匹配。在JDBC下识别某个子协议的第一个驱动程序将用于建立数据库连接。
- Driver:此接口处理与数据库服务器的通信。我们很少会直接与Driver对象进行交互。 但会使用DriverManager对象来管理这种类型的对象。 它还提取与使用Driver对象相关的信息。
- Connection:此接口具有用于联系数据库的所有方法。 连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。
- Statement:使用从此接口创建的对象将
- SQL语句提交到数据库。 除了执行存储过程之外,一些派生接口还接受参数。
- ResultSet:在使用Statement对象执行SQL查询后,这些对象保存从数据库检索的数据。 它作为一个迭代器并可移动ResultSet对象查询的数据。
- SQLException:此类处理数据库应用程序中发生的任何错误。
我们先简单看一个通过JDBC 连接 mysql 的 demo,了解一下在没有任何框架的加持下,大致的原生逻辑:
拆解 - Druid
通过对 JDBC 的了解,我们可以看出,它的优点和不足(或者说待改善之处),不足之处就是,通过直接使用JDBC来链接数据库,比如难处就有:
- 代码繁琐,编写SQL困难,重复的事情上要花大量的时间
- 要手动维护链接,用完还得关闭
- 链接的频繁开关是个无法忽视的消耗
- 不同DML语句方法之间没有足够高的通用性,且取值方法相对复杂。
- 事物的复杂维护 以及 异常的处理等
而最大的好处则是在将JDBC作为地基的角度上,提供了极高的改造空间,是很多主流框架的底层基石
- 分布式事务
- 数据源对象
- 连接池技术
而Druid 也不例外, 也是基于这一基础上开发而来的。如果说要参观一座花园,少不了的一定是寻找它的大门口,而在Druid这座花园中的大门,毫无意外就是,DruidDataSource。通过下面这张图我们可以看出他的“花园脉络”
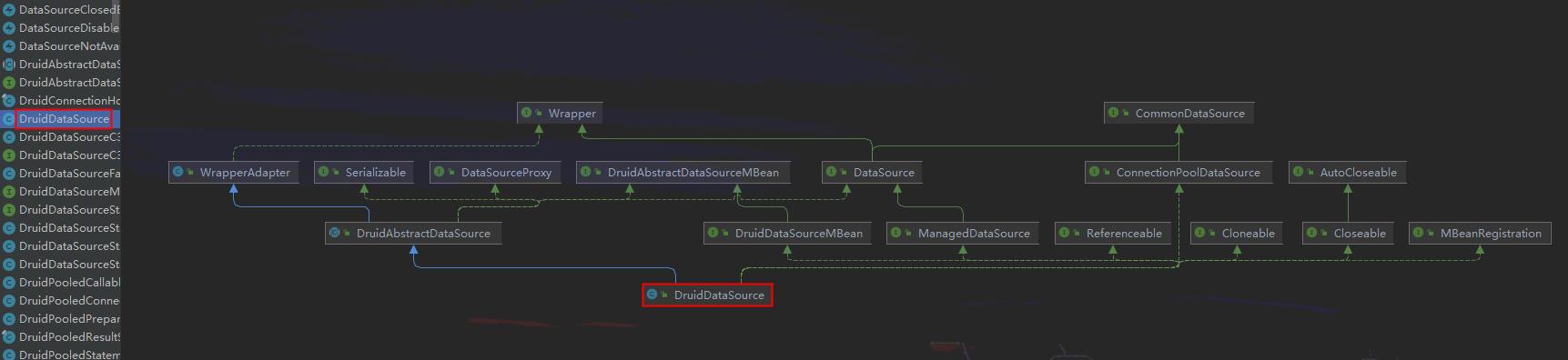
[ Druid 关系图 ]
从上图我们可以看到两个关键点, 一个是蓝色实现直接继承的抽象类 DruidAbstractDataSource 和 以虚线 CommonDataSource 作为顶级接口一路继承实现下来的过程。
//STEP 1. Import required packages
import java.sql.*;
public class FirstExample
// JDBC driver name and database URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://localhost/emp";
// Database credentials
static final String USER = "root";
static final String PASS = "123456";
public static void main(String[] args)
Connection conn = null;
Statement stmt = null;
try
//STEP 2: Register JDBC driver
Class.forName("com.mysql.jdbc.Driver");
//STEP 3: Open a connection
System.out.println("Connecting to database...");
conn = DriverManager.getConnection(DB_URL,USER,PASS);
//STEP 4: Execute a query
System.out.println("Creating statement...");
stmt = conn.createStatement();
String sql;
sql = "SELECT id, first, last, age FROM Employees";
ResultSet rs = stmt.executeQuery(sql);
//STEP 5: Extract data from result set
while(rs.next())
//Retrieve by column name
int id = rs.getInt("id");
int age = rs.getInt("age");
String first = rs.getString("first");
String last = rs.getString("last");
//Display values
System.out.print("ID: " + id);
System.out.print(", Age: " + age);
System.out.print(", First: " + first);
System.out.println(", Last: " + last);
//STEP 6: Clean-up environment
rs.close();
stmt.close();
conn.close();
catch(SQLException se)
//Handle errors for JDBC
se.printStackTrace();
catch(Exception e)
//Handle errors for Class.forName
e.printStackTrace();
finally
//finally block used to close resources
try
if(stmt!=null)
stmt.close();
catch(SQLException se2)
// nothing we can do
try
if(conn!=null)
conn.close();
catch(SQLException se)
se.printStackTrace();
//end finally try
//end try
System.out.println("There are so thing wrong!");
//end main
//end
我们先从 【DruidDataSource 】获取连接的核心逻辑开始,作为这次拆解 Druid 的学习入口
1. 关键方法getConnection ,从创建到获取链接的最外层逻辑
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException
// 螺丝刀补充:内部完成了校验并初始化一堆配置,同时做信息记录
init();
// 螺丝刀补充: 这下面的判断逻辑核心目的都是为了获取链接,前者是看是否有过滤链要继续执行,后者在最大等待时间内则直接获取
if (filters.size() > 0)
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
else
return getConnectionDirect(maxWaitMillis);
2.初始化细节描述
(关键部分已添加注释,记住核心要点,后期会细化讲解,未标注的其余地方概览即可)
public void init() throws SQLException
if (inited)
return;
// bug fixed for dead lock, for issue #2980
DruidDriver.getInstance();
// 螺丝刀补充: 这里创建一把可重入锁
final ReentrantLock lock = this.lock;
try
// 螺丝刀补充: 尝试获取锁,如果未获取到直接返回
lock.lockInterruptibly();
catch (InterruptedException e)
throw new SQLException("interrupt", e);
boolean init = false;
try
// 螺丝刀补充:小细节 double check 一下是否完成初始化步骤
if (inited)
return;
// 螺丝刀补充: 下面都是 【一堆参数的校验、记录 以及 设置】
initStackTrace = Utils.toString(Thread.currentThread().getStackTrace());
this.id = DruidDriver.createDataSourceId();
if (this.id > 1)
long delta = (this.id - 1) * 100000;
this.connectionIdSeedUpdater.addAndGet(this, delta);
this.statementIdSeedUpdater.addAndGet(this, delta);
this.resultSetIdSeedUpdater.addAndGet(this, delta);
this.transactionIdSeedUpdater.addAndGet(this, delta);
// 螺丝刀补充:这里对配置好的链接地址做空白去除后,内部对这个地址进行一系列的case判断和初始化
if (this.jdbcUrl != null)
this.jdbcUrl = this.jdbcUrl.trim();
initFromWrapDriverUrl();
for (Filter filter : filters)
filter.init(this);
if (this.dbTypeName == null || this.dbTypeName.length() == 0)
this.dbTypeName = JdbcUtils.getDbType(jdbcUrl, null);
DbType dbType = DbType.of(this.dbTypeName);
if (JdbcUtils.isMysqlDbType(dbType))
boolean cacheServerConfigurationSet = false;
if (this.connectProperties.containsKey("cacheServerConfiguration"))
cacheServerConfigurationSet = true;
else if (this.jdbcUrl.indexOf("cacheServerConfiguration") != -1)
cacheServerConfigurationSet = true;
if (cacheServerConfigurationSet)
this.connectProperties.put("cacheServerConfiguration", "true");
if (maxActive <= 0)
throw new IllegalArgumentException("illegal maxActive " + maxActive);
if (maxActive < minIdle)
throw new IllegalArgumentException("illegal maxActive " + maxActive);
if (getInitialSize() > maxActive)
throw new IllegalArgumentException("illegal initialSize " + this.initialSize + ", maxActive " + maxActive);
if (timeBetweenLogStatsMillis > 0 && useGlobalDataSourceStat)
throw new IllegalArgumentException("timeBetweenLogStatsMillis not support useGlobalDataSourceStat=true");
if (maxEvictableIdleTimeMillis < minEvictableIdleTimeMillis)
throw new SQLException("maxEvictableIdleTimeMillis must be grater than minEvictableIdleTimeMillis");
if (keepAlive && keepAliveBetweenTimeMillis <= timeBetweenEvictionRunsMillis)
throw new SQLException("keepAliveBetweenTimeMillis must be grater than timeBetweenEvictionRunsMillis");
if (this.driverClass != null)
this.driverClass = driverClass.trim();
// 螺丝刀补充:尝试通过SPI机制加载
initFromSPIServiceLoader();
// 螺丝刀补充:解析驱动并赋值
resolveDriver();
initCheck();
initExceptionSorter();
initValidConnectionChecker();
validationQueryCheck();
if (isUseGlobalDataSourceStat())
dataSourceStat = JdbcDataSourceStat.getGlobal();
if (dataSourceStat == null)
dataSourceStat = new JdbcDataSourceStat("Global", "Global", this.dbTypeName);
JdbcDataSourceStat.setGlobal(dataSourceStat);
if (dataSourceStat.getDbType() == null)
dataSourceStat.setDbType(this.dbTypeName);
else
dataSourceStat = new JdbcDataSourceStat(this.name, this.jdbcUrl, this.dbTypeName, this.connectProperties);
dataSourceStat.setResetStatEnable(this.resetStatEnable);
connections = new DruidConnectionHolder[maxActive];
evictConnections = new DruidConnectionHolder[maxActive];
keepAliveConnections = new DruidConnectionHolder[maxActive];
SQLException connectError = null;
if (createScheduler != null && asyncInit)
for (int i = 0; i < initialSize; ++i)
submitCreateTask(true);
else if (!asyncInit)
// init connections
while (poolingCount < initialSize)
try
// 螺丝刀补充:创建物理链接
PhysicalConnectionInfo pyConnectInfo = createPhysicalConnection();
DruidConnectionHolder holder = new DruidConnectionHolder(this, pyConnectInfo);
// 螺丝刀补充:链接存入数组
connections[poolingCount++] = holder;
catch (SQLException ex)
LOG.error("init datasource error, url: " + this.getUrl(), ex);
if (initExceptionThrow)
connectError = ex;
break;
else
Thread.sleep(3000);
if (poolingCount > 0)
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
createAndLogThread();
// 螺丝刀补充: 可以看到全局变量有一个值为2的初始化Latch,其目的就是为了等待这下面两个方法中(分别是初始化创建者线程和销毁者线程)守护线程的创建,
createAndStartCreatorThread();
createAndStartDestroyThread();
initedLatch.await();
init = true;
initedTime = new Date();
registerMbean();
if (connectError != null && poolingCount == 0)
throw connectError;
// 螺丝刀补充:是否建立心跳任务
if (keepAlive)
// async fill to minIdle
if (createScheduler != null)
for (int i = 0; i < minIdle; ++i)
submitCreateTask(true);
else
this.emptySignal();
catch (SQLException e)
LOG.error("dataSource-" + this.getID() + " init error", e);
throw e;
catch (InterruptedException e)
throw new SQLException(e.getMessage(), e);
catch (RuntimeException e)
LOG.error("dataSource-" + this.getID() + " init error", e);
throw e;
catch (Error e)
LOG.error("dataSource-" + this.getID() + " init error", e);
throw e;
finally
inited = true;
lock.unlock();
if (init && LOG.isInfoEnabled())
String msg = "dataSource-" + this.getID();
if (this.name != null && !this.name.isEmpty())
msg += ",";
msg += this.name;
msg += " inited";
LOG.info(msg);
3.获取链接过程
public DruidPooledConnection getConnectionDirect(long maxWaitMillis) throws SQLException
int notFullTimeoutRetryCnt = 0;
// 螺丝刀补充: 上自旋锁
for (;;)
// handle notFullTimeoutRetry
DruidPooledConnection poolableConnection;
try
// 螺丝刀补充: 获取链接的关键方法
poolableConnection = getConnectionInternal(maxWaitMillis);
catch (GetConnectionTimeoutException ex)
if (notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount && !isFull())
notFullTimeoutRetryCnt++;
if (LOG.isWarnEnabled())
LOG.warn("get connection timeout retry : " + notFullTimeoutRetryCnt);
continue;
throw ex;
if (testOnBorrow)
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate)
if (LOG.isDebugEnabled())
LOG.debug("skip not validate connection.");
discardConnection(poolableConnection.holder);
continue;
else
if (poolableConnection.conn.isClosed())
discardConnection(poolableConnection.holder); // 传入null,避免重复关闭
continue;
if (testWhileIdle)
final DruidConnectionHolder holder = poolableConnection.holder;
long currentTimeMillis = System.currentTimeMillis();
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
long lastExecTimeMillis = holder.lastExecTimeMillis;
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
if (checkExecuteTime
&& lastExecTimeMillis != lastActiveTimeMillis)
lastActiveTimeMillis = lastExecTimeMillis;
if (lastKeepTimeMillis > lastActiveTimeMillis)
lastActiveTimeMillis = lastKeepTimeMillis;
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0)
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
)
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate)
if (LOG.isDebugEnabled())
LOG.debug("skip not validate connection.");
discardConnection(poolableConnection.holder);
continue;
if (removeAbandoned)
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
poolableConnection.connectStackTrace = stackTrace;
poolableConnection.setConnectedTimeNano();
poolableConnection.traceEnable = true;
activeConnectionLock.lock();
try
activeConnections.put(poolableConnection, PRESENT);
finally
activeConnectionLock.unlock();
if (!this.defaultAutoCommit)
poolableConnection.setAutoCommit(false);
return poolableConnection;
4.回收链接过程
/**
* close datasource
* 螺丝刀补充: 回收线程
*/
public void close()
if (LOG.isInfoEnabled())
LOG.info("dataSource-" + this.getID() + " closing ...");
// 螺丝刀补充: 上可重入锁
lock.lock();
try
if (this.closed)
return;
if (!this.inited)
return;
this.closing = true;
if (logStatsThread != null)
logStatsThread.interrupt();
if (createConnectionThread != null)
createConnectionThread.interrupt();
if (destroyConnectionThread != null)
destroyConnectionThread.interrupt();
if (createSchedulerFuture != null)
createSchedulerFuture.cancel(true);
if (destroySchedulerFuture != null)
destroySchedulerFuture.cancel(true);
// 螺丝刀补充:遍历池子,关闭对应链接
for (int i = 0; i < poolingCount; ++i)
DruidConnectionHolder connHolder = connections[i];
for (PreparedStatementHolder stmtHolder : connHolder.getStatementPool().getMap().values())
connHolder.getStatementPool().closeRemovedStatement(stmtHolder);
connHolder.getStatementPool().getMap().clear();
Connection physicalConnection = connHolder.getConnection();
try
physicalConnection.close();
catch (Exception ex)
LOG.warn("close connection error", ex);
connections[i] = null;
destroyCountUpdater.incrementAndGet(this);
poolingCount = 0;
unregisterMbean();
enable = false;
notEmpty.signalAll();
notEmptySignalCount++;
this.closed = true;
this.closeTimeMillis = System.currentTimeMillis();
disableException = new DataSourceDisableException();
for (Filter filter : filters)
filter.destroy();
finally
this.closing = false;
lock.unlock();
if (LOG.isInfoEnabled())
LOG.info("dataSource-" + this.getID() + " closed");
以上是关于[ Druid ] 源码拆解 —— 1. 初始化过程的全局概览的主要内容,如果未能解决你的问题,请参考以下文章