Hadoop3 - HDFS 文件存储策略
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop3 - HDFS 文件存储策略相关的知识,希望对你有一定的参考价值。
一、HDFS 文件存储策略
Hadoop 允许将不是热数据或者活跃数据的数据分配到比较便宜的存储上,用于归档或冷存储。可以设置存储策略,将较旧的数据从昂贵的高性能存储上转移到性价比较低(较便宜)的存储设备上。
Hadoop 2.5及以上版本都支持存储策略,在该策略下,不仅可以在默认的传统磁盘上存储HDFS数据,还可以在SSD(固态硬盘)上存储数据。
异构存储
异构存储是Hadoop2.6.0版本出现的新特性,可以根据各个存储介质读写特性不同进行选择。例如冷热数据的存储,对冷数据采取容量大,读写性能不高的存储介质如机械硬盘,对于热数据,可使用SSD硬盘存储。在读写效率上性能差距大。异构特性允许我们对不同文件选择不同的存储介质进行保存,以实现机器性能的最大化。
HDFS中4种异构存储类型
- RAM_DISK(内存)
- SSD(固态硬盘)
- DISK(机械硬盘),默认使用。
- ARCHIVE(高密度存储介质,存储档案历史数据)
如何让HDFS知道集群中的数据存储目录是哪种类型存储介质
配置属性时主动声明。HDFS并没有自动检测的能力。例如配置:dfs.datanode.data.dir = [SSD]file:///data/hadoop 如果目录前没有带上[SSD] [DISK] [ARCHIVE] [RAM_DISK] 这4种类型中的任何一种,则默认是DISK类型 。
块存储类型策略
指的是对HDFS文件的数据块副本储存。对于数据的存储介质,HDFS的BlockStoragePolicySuite 类内部定义了6种策略。HOT(默认策略)、COLD、 WARM、 ALL_SSD、 ONE_SSD、 LAZY_PERSIST 前三种根据冷热数据区分,后三种根据磁盘性质区分,在 HDFS 中可以通过下面指令查看支持的策略:
hdfs storagepolicies -listPolicies

-
HOT:用于存储和计算。流行且仍用于处理的数据将保留在此策略中。所有副本都存储在DISK中。 -
COLD:仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。所有副本都存储在ARCHIVE中。 -
WARM:部分热和部分冷。热时,其某些副本存储在DISK中,其余副本存储在ARCHIVE中。 -
All_SSD:将所有副本存储在SSD中。 -
One_SSD:用于将副本之一存储在SSD中。其余副本存储在DISK中。 -
Lazy_Persist:用于在内存中写入具有单个副本的块。首先将副本写入RAM_DISK,然后将其延迟保存在DISK中。

为某个目录设置存储策略,可以使用下面指令:
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
hdfs storagepolicies -setStoragePolicy -path /had/data -policy WARM
取消存储策略
hdfs storagepolicies -unsetStoragePolicy -path <path>
hdfs storagepolicies -unsetStoragePolicy -path /had/data
查看存储策略
hdfs storagepolicies -getStoragePolicy -path <path>
hdfs storagepolicies -getStoragePolicy -path /had/data
下面通过一个案例来深入了解存储策略,首先配置 DataNode 的存储目录为多个介质类型,如下:
| 存储目录 | 类型 |
|---|---|
| file://$hadoop.tmp.dir/dfs/data | DISK |
| file://$hadoop.tmp.dir/dfs/data/archive | ARCHIVE |
然后在 HDFS 中规划三个目录,分别存 热、温、冷 数据:
| 目录 | 类型 |
|---|---|
| hdfs://had/data/hot | 热数据 |
| hdfs://had/data/warm | 温数据 |
| hdfs://had/data/cold | 冷数据 |
下面开始实施
二、热、温、冷 数据操作
- 修改
hdfs-site.xml文件,增加DataNode的存储目录:
vi hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://$hadoop.tmp.dir/dfs/data,[ARCHIVE]file://$hadoop.tmp.dir/dfs/data/archive</value>
</property>

如果是集群,需要同步至其他 DataNode 节点。
重启 HDFS 后,到 web 管理页面验证是否生效:

- 在 HDFS 中创建
热、温、冷目录:
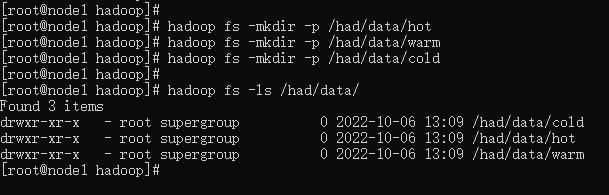
hadoop fs -mkdir -p /had/data/hot
hadoop fs -mkdir -p /had/data/warm
hadoop fs -mkdir -p /had/data/cold
- 对创建的目录指定存储策略:
hdfs storagepolicies -setStoragePolicy -path /had/data/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /had/data/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /had/data/cold -policy COLD

- 查看创建的策略
hdfs storagepolicies -getStoragePolicy -path /had/data/hot
hdfs storagepolicies -getStoragePolicy -path /had/data/warm
hdfs storagepolicies -getStoragePolicy -path /had/data/cold

- 上传文件测试异构存储
echo "hello" > test.txt
hadoop fs -put test.txt /had/data/hot
hadoop fs -put test.txt /had/data/warm
hadoop fs -put test.txt /had/data/cold

- 查看
热数据文件的block位置
hdfs fsck /had/data/hot/test.txt -files -blocks -locations

存储在了 DISK 类型的磁盘中
- 查看
温数据文件的block位置
hdfs fsck /had/data/warm/test.txt -files -blocks -locations

可以看到存储在了 DISK 类型的磁盘中,由于我这里就一个 DataNode 节点,所以存在 DISK 中了,如果再来一个,就会看到存在了 ARCHIVE 类型。
- 查看
冷数据文件的block位置
hdfs fsck /had/data/cold/test.txt -files -blocks -locations

冷数据就毋庸置疑了,肯定存在 ARCHIVE 类型。
三、LAZY PERSIST 类型实施
当设置为 LAZY PERSIST 类型 DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,注意:该特性从Apache Hadoop 2.6.0开始支持。
LAZY PERSIST执行流程
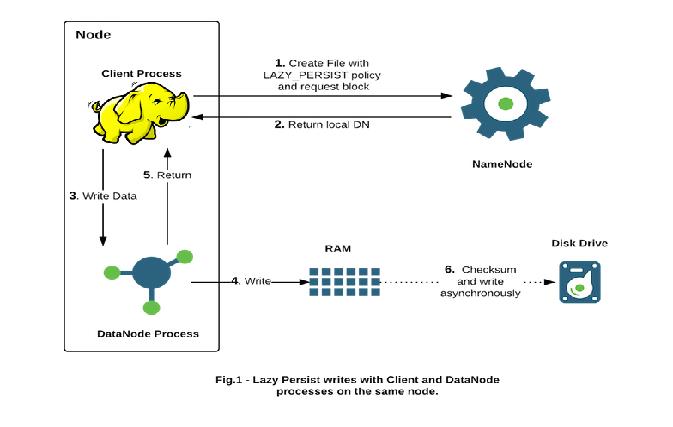
- 对目标文件目录设置 StoragePolicy 为 LAZY_PERSIST 的内存存储策略 。
- 客户端进程向 NameNode 发起创建/写文件的请求 。
- 客户端请求到具体的 DataNode 后 DataNode 会把这些数据块写入 RAM 内存中,同时启动异步线程服务将内存数据持久化写到磁盘上 。
- 内存的异步持久化存储是指数据不是马上落盘,而是懒惰的、延时地进行处理 。
配置过程
- 创建虚拟内存挂载目录
mkdir -p /data/tmp
- 虚拟内存盘挂载,限制内存使用大小为1GB,相当于存在
/data/tmp中的文件,实际存在了内存中
mount -t tmpfs -o size=1g tmpfs /data/tmp
- 修改
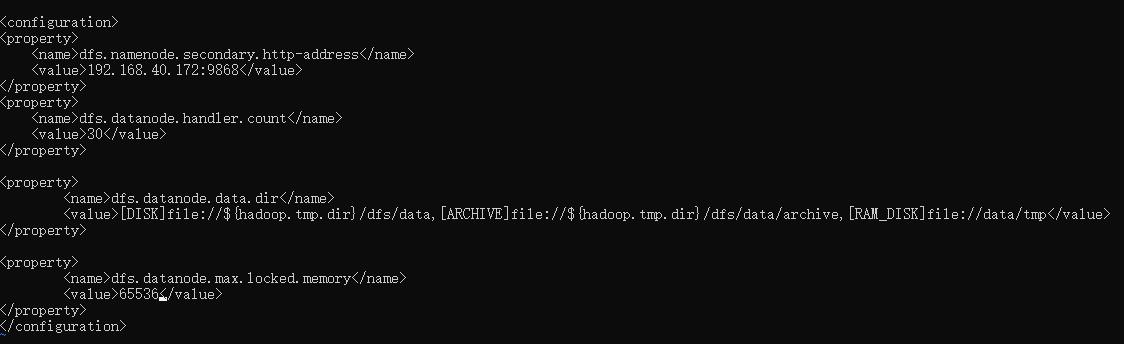
hdfs-site.xml文件,增加存储目录:
vi hdfs-site.xml
<!-- 是否开启异构存储,默认true开启, 可不设置-->
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://$hadoop.tmp.dir/dfs/data,[ARCHIVE]file://$hadoop.tmp.dir/dfs/data/archive,[RAM_DISK]file://data/tmp</value>
</property>
<!-- 用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内 存大小的话,部分内存块会被直接移出 。byte 类型 -->
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
修改后重启 hadoop ,到web管理页面查看是否生效:

- 在 HDFS 中创建目录:
hadoop fs -mkdir -p /had/data/lazy/
- 为目录指定策略为 LAZY_PERSIST
hdfs storagepolicies -setStoragePolicy -path /had/data/lazy/ -policy LAZY_PERSIST
以上是关于Hadoop3 - HDFS 文件存储策略的主要内容,如果未能解决你的问题,请参考以下文章