[ ElasticSearch ] 螺丝刀学习笔记之 —— ElasticSearch(7.0UP学习概览)
Posted 削尖的螺丝刀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[ ElasticSearch ] 螺丝刀学习笔记之 —— ElasticSearch(7.0UP学习概览)相关的知识,希望对你有一定的参考价值。
在此1024广大猿人欢度佳节之际,作为广大猿族的一员怎能不拿出点东西庆祝庆祝呢?这不,压箱底的两篇学习笔记其中之一 —— ElasticSearch学习概览,就此 JI 出 ~~ , 祝自己和各位猿族兄嘚们节日快乐,同时欢迎各位猿友们一起交流指正 ~ ~ 🐵 😘

什么是ES?
ES是一种开源、RESTful(隐藏了Lucene的复杂性)、可扩展的基于文档的搜索引擎,它构建在Lucene库上。用户通过JSON格式的请求,使用CRUD的REST API就可以完成存储和管理文本、数值、地理空间、结构化或者非结构化的数据。
一句话简述: 实施分布式搜索和分析引擎。它用于大数据的全文搜索、结构化搜索、分析等功能。
用户使用Kibana就可以可视化使用数据,同时Kibana也提供交互式的数据状态呈现和数据分析。
Apache Lucene搜索引擎基于JSON文档来进行搜索管理和快速搜索。
PS:ES6.0和7.0有很大的变化,几乎是分水岭,而我学的恰好是7.0版本以上的 —— 7.6
为什么用ES?
随着业务量增大,数据必然多,再用而数据库的模糊查询是会放弃索引的,这会导致查询非常缓慢。导致系统查询数据时都是全表扫描,在百万级别的数据库中,查询效率是非常低下的,而我们使用 ES 做一个全文索引,将经常查询的系统功能的某些字段,比如说电商系统的商品表中商品名,描述、价格还有 id 这些字段我们放入 ES 索引库里,可以提高查询速度。
核心概念
[ 索引indices、文档documents、字段filds、类型types ]
- indices:就是索引群(这里可理解为数据库,的概念),分片就是对索引群做分片,一个分片就是一个Lucene的索引(倒排索引机制)。ps:从indices是index的复数形式就可以看出,是一个索引集群的概念
- types:类比数据库中的表-table,但是这个在7.0已经弃用了(默认为_doc)
- filds:就是数据库中的字段头概念
- documents:就是数据库中行的概念,就是每一行数据
简单使用:建立数据库(索引群indices) ——> 创建字段(filds) ——> 插入数据行(文档documents)
[ 分片/集群(副本) ]
ES启动的时候就默认给你做好分片了(默认的分片名叫ElasticSearch),之后要做集群也是在这基础上做。
- 分片: 相当于数据库的水平拆分,比如数据量太大了,男、女就拆成两个片放到不同的机器上,或者2020、2021的数据拆分开,类似这样
- 集群(副本): 如果分片的机子宕机了怎么办?那就要有副本集群了。同时做好负载,也可以在副本取数据
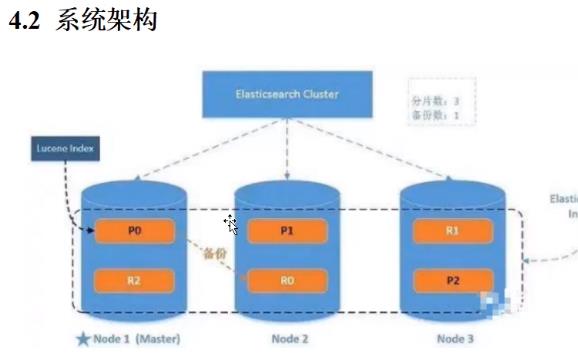
如上图所示:
- 1- 集群中会选举一个主节点master——负责添加/删除整个集群的索引,节点备份管理…(但是数据访问和主节点无关,所有节点都能访问)
- 2 - P开头的都是分片数据
- 3 - R开头的都是备份数据,可以看到没有一个自己的备份数据是在自己本身的机器上的。
#PUT http://127.0.0.1:1001/users
"settings" :
"number_of_shards" : 3,
"number_of_replicas" : 1
上方的请求含义是 —— 把users索引群,分成三片,每片有一个副本(通过elasticsearch-head能观察到集群状态)
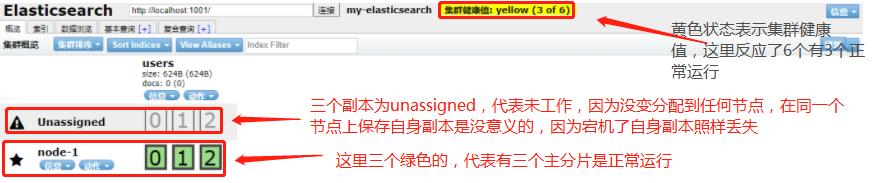
五角星的代表分片主节点,圆圈(上为报警标志)的是副本从节点,当配置好了集群(当然会配masterID等信息咯),启动其他节点后,副本会自动同步到各个节点,最后就会变成全绿的健康状态,如下:
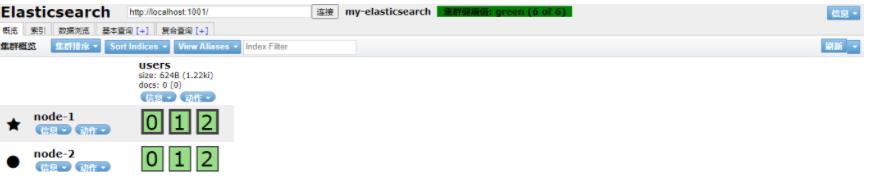
集群配置好,启动会自动进行水平扩容,比如下面,1001机器的0、1分片的副本都不在自己机器上,而是分别分配在1002和1003上。
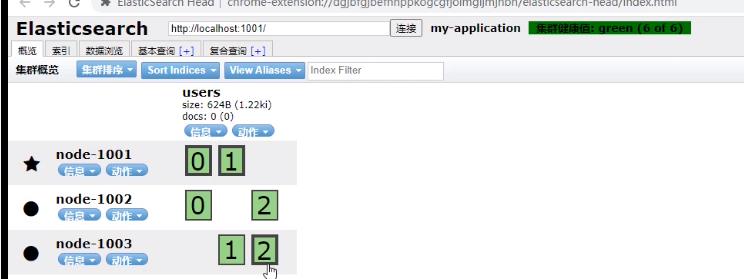
主分片的数量在创建时就已经定好了(数量根据系统硬件自动算出的),但是如果后续要扩容增加吞吐量的话(只能增加吞吐量,因为从节点也能接受读取请求),怎么办? —— 主节点不能再扩容,但是副本从节点是可以动态扩容的,通过下面请求就可以把刚才上面的每个主节点1个副本,扩容成2个:
#PUT http://127.0.0.1:1001/users/_settings
"number_of_replicas" : 2
、
ES的集群和Eureka一样很简单,配置下Yml就好,之后要复习集群的细节步骤,看这个 https://www.bilibili.com/video/BV1hh411D7sb?p=30,类似Redis,如果主节点宕机了,会继续从副本选一个新的主节点 —— Raft算法,宕机的机器恢复后,也是只能称为从节点,新选举的主节点不会变
[ 集群的路由方式 ]
—— 这个集群都是一样的,万变不离其宗
- hash(id)% 总节点个数(考虑扩容问题,这个是否也有一致性哈希的解决方案?这个之后了解)
- 轮询(因为每个节点都是有各自副本的)
[ 集群数据的读/写/更新/删除流程 ]
- 写: 写完主节点后,还会发信号同步写副本从节点,这个时候可能就要等待的时间长一点,可以设置参数,只要主节点写完后就返回。
- 读: 请求到了集群内部,路由到了机器后,会拿到所有分片和副本的信息,然后轮询准发查找,查到就会返回数据。
- 更新/删除: 其实不管是单个还是批量,流程都和上面一样的,系统会在内部自动完成转发跳转,直到完成任务。
早起的索引一旦建立就会写入磁盘不能改变,如果要改变则全部重新建立写入。
新的索引采用了段追加的概念,每段都是一个Lucene索引,也就是后续新加入的索引会被追加到缓存,不时的缓存数据会被提交(进入磁盘合并,然后各磁盘进行同步),只有落入磁盘的数据,用户才能读到
—— 和其他所有延时刷盘的组件一样,为了保证数据一致性,ES通过一个TransLog来保证**,不过是先写内存,再写TransLog**(和Redis的AOF一样,先写缓存,再写日志),为保证速度,存操作系统的时候也会先存到,操作系统文件缓冲区,所以磁盘也有这个Log(因为存磁盘的过程也会很慢,所以操作系统也有一个内存缓冲区,先存缓冲区然后再写到磁盘,这点和Redis完全一样),最后再一步步刷盘到磁盘,刷盘后磁盘的TransLog才会清除。
所以总体步骤 内存缓存 —— > TransLog(内存) ——>操作系统弄文件缓冲区 ——>TransLog(操作系统) ——> 磁盘刷盘 ——>清空TransLog(操作系统)
这也有个面试题:ES是近实时搜索的,因为是分段补充存储
[ 倒排索引 ]
—— ES查询的核心原理是倒排索引:
- 就是平时的mysql查询时根据id来查询值,而倒排索引是根据值来查询id位置(空间换时间),比如要查zhang,那么会有一个包存了zhang和有zhang的索引ID,直接去查这些id然后返回值就行了。
结构概念:
- 词条:索引中的最小存储单元(英文是单词,中文就是词组)
- 词典: 字典,用于快速查询词条是否在词典中存在的,底层数据结构(B+、HashMap)
- 倒排表:存储的是词条和其对应的所有ID
查询流程 :
- 先去 词典查看 是否有要查的 这个 词条
- 有的话再去 倒排表 拿 到这个词条对应的所有 ID
- 然后直接把这些ID位置的数据返回。
[ IK分词器 ]
- 一个中文分词(当然也有对应的英文分词软件)软件,比如你百度——“棋牌”,这个关键词的结果就有可能被分成“棋牌”、“棋”、“牌”来查找
- 分词算法
- ik_smart —— 最少分词
- ik_max_word —— 最多(细粒度)分词
[ 解决并发问题 ]
- 悲观锁,谁都知道,分布式锁呗
- 乐观锁:
- 早起版本用_version控制,请求带 _version后Es会判断是否可安全更新,新版不用了
- 新版用**if_seq _no **和 if _primary_term 参数,这个参数的值也是在对应文件参数中能拿到的
- 还有可用外部版本号(比如你数据库的号,这个后续要了解再看吧)
常见概念
[ Lucene? ]
- Lucene是一套java开发的信息检索工具包, jar包, 不包含搜索引擎系统;
- Lucene包含索引结构, 读写索引的工具, 排序, 搜索规则, 工具类;
- Lucene和ES的关系:
- ES是基于Lucene做了一些封装和增强, 上手是比较简单的, 比Redis要简单
[ ElasticSearch 和 Solr的对比?]
- 二者都是基于Lucene封装的,ES支持RestFul请求,Solr是WebService的请求
- ES自身支持集群,Solr要借助Zookeeper来集群,且配置复杂(ES解压即可用, Solr需要配置)
- ES比Solr更快
- 当使用索引时, solr会发生io阻塞
- elastic的效率在传统项目下一般有50倍的提升
- Solr支持更多格式的数据, json, xml, csv, Elastic只支持json
- Solr查询快, 但是更新索引时慢(如插入和删除慢), Elastic查询相对慢, 但是实时性查询快, 用于facebook新浪等搜索
- solr是传统搜索应用的解决方案, elastic适用于新兴的实时搜索应用
大数据方向学习的展望
- ELK技术(elastic+logstash+kibana) (不过这好像属于运维工程师…后续再了解完善把) ——
- Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制等。(存储/查询/展示)
- Logstash 是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用。(收集/清洗)
- Kibana 也是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供汇总、分析和搜索重要数据日志。(ES的可视化平台)
语法 (注意聚合没有讲,自己要去查)
[ 概览 ]
结构:
索引indices(库)、类型types(表)、属性filds(字段)、文档documents(行) —— 注意表在版本7之后弃用了,要写默认的_doc
请求:
遵循Restful风格,PUT创建、POST更新;DELETE 删除;GET;查询,下面列举几个常用请求(此处仅为概览,所以省略JSON体)
注意不建议下面这样使用,因为PUT主管创建,POST主管更新,在PUT请求后加 _create即可,在POST请求后加 _update
-
POST /indices(库)/ types(表)/ id
-
PUT /indices(库)/ types(表)/ id
—— 没值创建,有值覆盖更新 indices(库)下 types(表)中ID为 id的值
(比如原id下有三个字段的值,我更新的请求只有一个字段,那更新完后就只剩我这一个字段了,这就叫覆盖更新)
-
PUT /indices(库)/ types(表)/ id / _create
—— 在indices(库)下创建 types(表),ID为id (如果已有该ID下的值,则会返回一个id冲突异常,原值不会发生任何改变)
-
PUT /indices(库)/ _mapping
—— 创建**indices(库)**下表字段的映射关系(也叫创建规则,就是指定字段类型的意思),下面肯定要接Json具体查询内容的
-
POST /indices(库)/ types(表)/ id /_update
—— 替换更新 indices(库)下 types(表)中ID为 id 的值
( 注意末尾加的这个**_update**相当于固定搭配,指明了只更新当前属性,也就是说原来有三个字段,我现在更新请求只有一个字段,那只会更新这个字段,另外两个不变,且任然存在,总数依然三个。)
-
GET /indices(库)/ types(表)/ id
—— 查询indices(库)下types(表)总ID为id的值
-
GET /indices(库)/ types(表)/ **_search?q=**name:张三
—— 等值查询indices(库)下types(表)总ID为id的值(**_search?q=**后面的值为要精确匹配的值)
-
DELETE /indices(库)/ types(表)/ id
—— 删除indices(库)下types(表)总ID为id的值(如果你不写ID,那就是删除这个表,如果id和表都不写,那就是删除这个库)
-
GET /indices(库)/_search
—— 这个是查询语句,下面肯定要接Json具体查询内容的
-
GET /indices(库)/_mapping
—— 直接获取indices这个索引库内字段的映射关系(也叫规则or字段类型)
-
GET _cat/
—— 这是一个系统信息的查询命令,你输入_cat三个字就会有各种系统属性的查询提示了
语法:
因为都是Json请求,Json内容涉及层级关系,为方便概览,我在这里先不用Json而是用层级关系展示出来,所有有括号描述的都是固定语法。
[ 查询: 查询请求都是以 _search 结尾,请求体Json最外层则都是以==query==开头的,然后在内部指定具体查询规则 ]
-
query (查询)
-
term(精确查询,类似mysql的等值查询)
-
*match_all (查询所有,类似mysql的直接select )
-
match(查询匹配的字段,这个查出来的是分词结果,这个也可以写在bool中,做多条件查询类似and/or,这个就是全文检索 [内部用了倒排索引的查询] 的查询语句)
-
match_phrase(完全匹配,和term一个样)
- 具体属性……
-
filter(过滤)
- range(范围查询)
- 具体属性……
- gt(大于)
- gte(大于等于)
- lt(小于)
- lte(小于等于)
- 具体属性……
- range(范围查询)
-
bool(条件查询,相当于Mysql的Where)
- must(必须匹配,相当于Mysql的And) —— 后接数组
- match(查询匹配的字段)
- 具体属性……
- match(查询匹配的字段)
- should(应该匹配,相当于Mysql的Or)—— 后接数组
- match(查询匹配的字段)
- 具体属性……
- match(查询匹配的字段)
- minimum_should_match (should只要满足minimum_should_match 个条件就行了)
- must(必须匹配,相当于Mysql的And) —— 后接数组
-
-
from(分页 —— 从哪页开始,下标0开始计算的,所以是前端传的 页码-1*每页数据条数)
-
size (分页 —— 页面大小)
-
sort(排序)
- 具体属性……
- “order” : “desc”(倒序)
- “order” : “asc” (正序)
- 具体属性……
-
_source(只返回规定字段filds下所有的值) —— 后接数组,直接放fild,逗号隔开,比如 “_source”: [“name”,“desc”]
-
highlight(高亮)
- fields(要显示的字段)
- 具体属性……
- fields(要显示的字段)
-
aggs(高级语法 - 聚合操作) —— 可以分组统计相同字段的个数,比如a有3个、b有4个,那结果就是两组,分别为“key”:“a”,”doc_count”:3,“key”:“b”,”doc_count”:4 , 类似于mysql的select id , count(id) group by id
- 结果名称 —— 自定义即可
- terms (精准匹配统计)
- 具体属性……
- avg(上面的terms换成avg就变成求平均值了,这样查出来的是一个结果,即平均值)
- terms (精准匹配统计)
- 结果名称 —— 自定义即可
[ 创建规则:相当于建库 indices 时指定字段 Fields 类型 ]
- mappings
- properties
- 具体属性和类型……
- properties
PUT /indices1
"mappings":
"properties":
"name" :
# 指定以后只要是type字段的值都属于text,下面类似
"type": "text"
,
"birthday" :
"type": "date"
,
"age" :
"type": "long"
注意:
- 所有常见的英文字符必须为小写
- 未指定类型的filds字符串,默认为keyword类型,此类型为一个整体,无法分词
- 如果指定filds字符串为text类型,则可以分词。
代码:
代码关键在两个对象的操作 —— QueryBuilder、SearchQuery,设置好这两个对象的细节内容即可,其中QueryBuilder是装在SearchQuery中运行的,请求的时候直接带SearchQuery即可。
进阶玩法:
这些进阶方法,不是后续要练习的,就是要探究背后原理
[ 同义词 ]
- ES可以配置同义词,用在这样的需求场景 —— 你想搜索汉语,但是你中文、普通话也会被查出来,具体配置有两种:
- a=>b: 通俗的来讲,就是尽管用户输入的是a,但是es在查询的是会转成b去搜索,比如 保温杯=>杯子,用户输入的是"保温杯",但是es会用"杯子"去做搜索
- a,b:通俗的来讲,就是不管用户输入的是a还是b,es在查询都是用其对立的去搜索。比如 保温杯,杯子,用户输入的是"保温杯",es会用"杯子"去做搜索,也会用"保温杯"搜索
[Template中的JPA玩法,不用实现,只需要根据命名规则,定义好方法就行]
| 键字 | 使用示例 | 等同于的ES查询 |
|---|---|---|
| And | findByNameAndPrice | “bool” : “must” : [ “field” : “name” : “?”, “field” : “price” : “?” ] |
| Or | findByNameOrPrice | “bool” : “should” : [ “field” : “name” : “?”, “field” : “price” : “?” ] |
| Is | findByName | “bool” : “must” : “field” : “name” : “?” |
| Not | findByNameNot | “bool” : “must_not” : “field” : “name” : “?” |
| Between | findByPriceBetween | “bool” : “must” : “range” : “price” : “from” : ?,”to” : ?,”include_lower” : true,”include_upper” : true |
| LessThanEqual | findByPriceLessThan | “bool” : “must” : “range” : “price” : “from” : null,”to” : ?,”include_lower” : true,”include_upper” : true |
| GreaterThanEqual | findByPriceGreaterThan | “bool” : “must” : “range” : “price” : “from” : ?,”to” : null,”include_lower” : true,”include_upper” : true |
| Before | findByPriceBefore | “bool” : “must” : “range” : “price” : “from” : null,”to” : ?,”include_lower” : true,”include_upper” : true |
| After | findByPriceAfter | “bool” : “must” : “range” : “price” : “from” : ?,”to” : null,”include_lower” : true,”include_upper” : true |
| Like | findByNameLike | “bool” : “must” : “field” : “name” : “query” : “? *”,”analyze_wildcard” : true |
| StartingWith | findByNameStartingWith | “bool” : “must” : “field” : “name” : “query” : “? *”,”analyze_wildcard” : true |
| EndingWith | findByNameEndingWith | “bool” : “must” : “field” : “name” : “query” : “*?”,”analyze_wildcard” : true |
| Contains/Containing | findByNameContaining | “bool” : “must” : “field” : “name” : “query” : “?”,”analyze_wildcard” : true |
| In | findByNameIn(Collectionnames) | “bool” : “must” : “bool” : “should” : [ “field” : “name” : “?”, “field” : “name” : “?” ] |
| NotIn | findByNameNotIn(Collectionnames) | “bool” : “must_not” : “bool” : “should” : “field” : “name” : “?” |
| True | findByAvailableTrue | “bool” : “must” : “field” : “available” : true |
| False | findByAvailableFalse | “bool” : “must” : “field” : “available” : false |
| OrderBy | findByAvailableTrueOrderByNameDesc | “sort” : [ “name” : “order” : “desc” ],”bool” : “must” : “field” : “available” : true |
后续遗留:
我这次学的是ES的入门,各种概念、操作方法都掌握了,接下来就是要深入熟悉了,下面列出未来ES的深入方向。ES我从这里面看的: https://www.bilibili.com/video/BV1hh411D7sb,也有面试题、调优啥的,日后要复习就从这里开始再做延伸吧
- 原理
- 调优规则
- 上面的进阶操作、以及可能不知道的高阶语法
以上是关于[ ElasticSearch ] 螺丝刀学习笔记之 —— ElasticSearch(7.0UP学习概览)的主要内容,如果未能解决你的问题,请参考以下文章