Observability:日志监控和非结构化日志数据,超越 tail -f
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Observability:日志监控和非结构化日志数据,超越 tail -f相关的知识,希望对你有一定的参考价值。

几十年来,日志文件和系统日志一直是管理员和开发人员的信息宝库。 但是随着越来越多的活动部件和越来越多的关于在何处运行现代云应用程序的选择,关注日志和解决问题变得越来越困难。
虽然通常可以通过 ssh 连接到服务器并运行诸如 tail -f 之类的命令,但这种方法不适用于大多数开发人员和管理员。 即使你精通命令行,也可以使用 awk 和 grep 在日志文件中找到你要查找的内容,甚至可以计算一些关于特定错误发生频率的简单统计数据。 但是,如果应用程序在数百台服务器或 Kubernetes pod 上运行怎么办? 或者更糟糕的是,如果应用程序分布在多个云提供商中,其中一些在无服务器框架中运行,甚至可能不提供简单地拖尾文件的选项怎么办?
适当的日志管理可以轻松且经济高效地解决此类问题。 通过在像 Elastic 这样的企业平台上收集和存储日志,分析它们变得简单易行。
在本系列博文中,我们将向你介绍一些有关 Elastic 可观察性的日志管理、日志分析和可视化的最佳实践。 让我们从基础开始:收集日志数据以及处理非结构化数据。
如果你想跟随并亲自尝试这个示例,请下载我们在本文中使用的虚拟日志文件!
为 Elastic 可观察性摄取非结构化日志数据
“””
2021-02-02T22:04:44.093Z INFO Returning 3 ads
2021-02-02T22:05.32 213Z INFO Returning 1 ads
2021-02-02T22:07:41.913Z INFO Returning 2 ads
“””非结构化日志数据是应用程序最常记录的遥测数据类型。 这意味着应用程序发出的日志行没有清晰的机器可读结构,这带来了一些挑战。 话虽这么说,即使是非结构化数据也是很好的数据,对于故障排除和调查非常有用。
让我们通过一个从你的服务器之一收集自定义日志文件的快速示例。
我们将使用 Elastic Agent 从服务器读取一个简单的日志文件。 我们将只使用它的 “自定义日志” 集成,但如果你有其他想要加入的数据源,请查看我们提供的数百个其他 Elastic 集成!
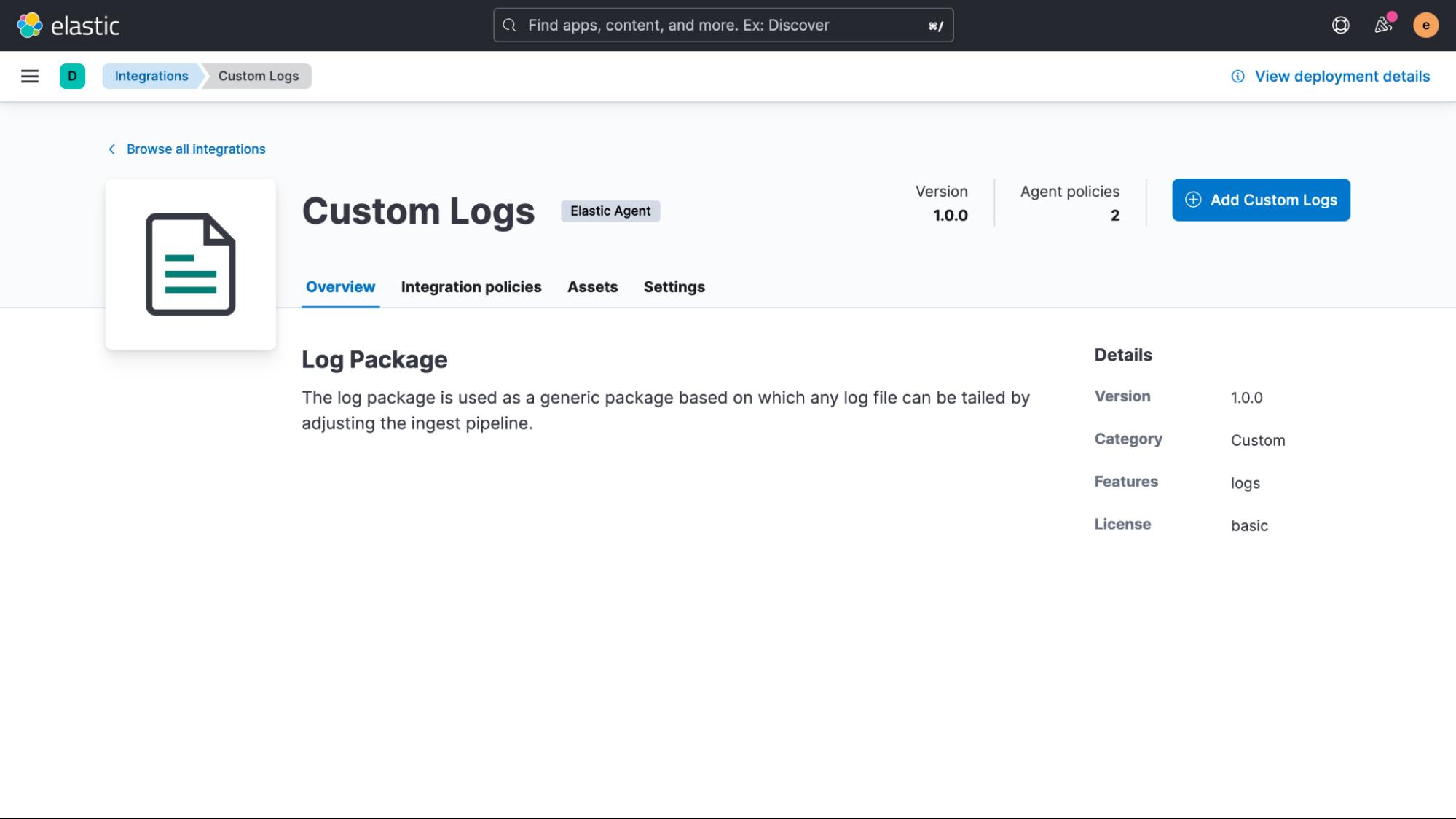
我们现在需要调整的唯一设置是日志文件的路径。 在此示例中,它是 /var/log/adverts.log。
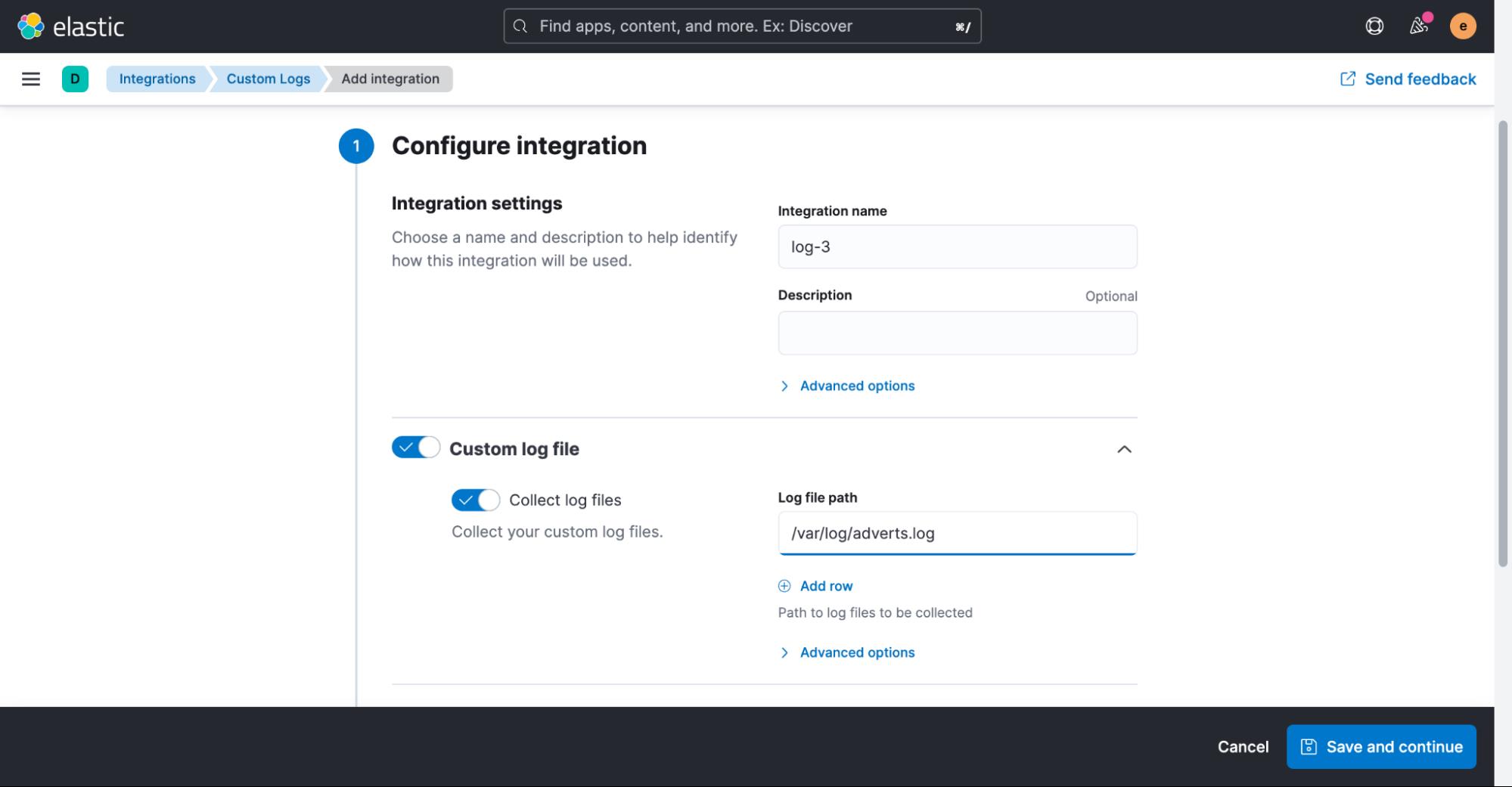
添加集成后,系统会询问我们是否现在要将 Elastic Agent 部署到我们的主机之一。
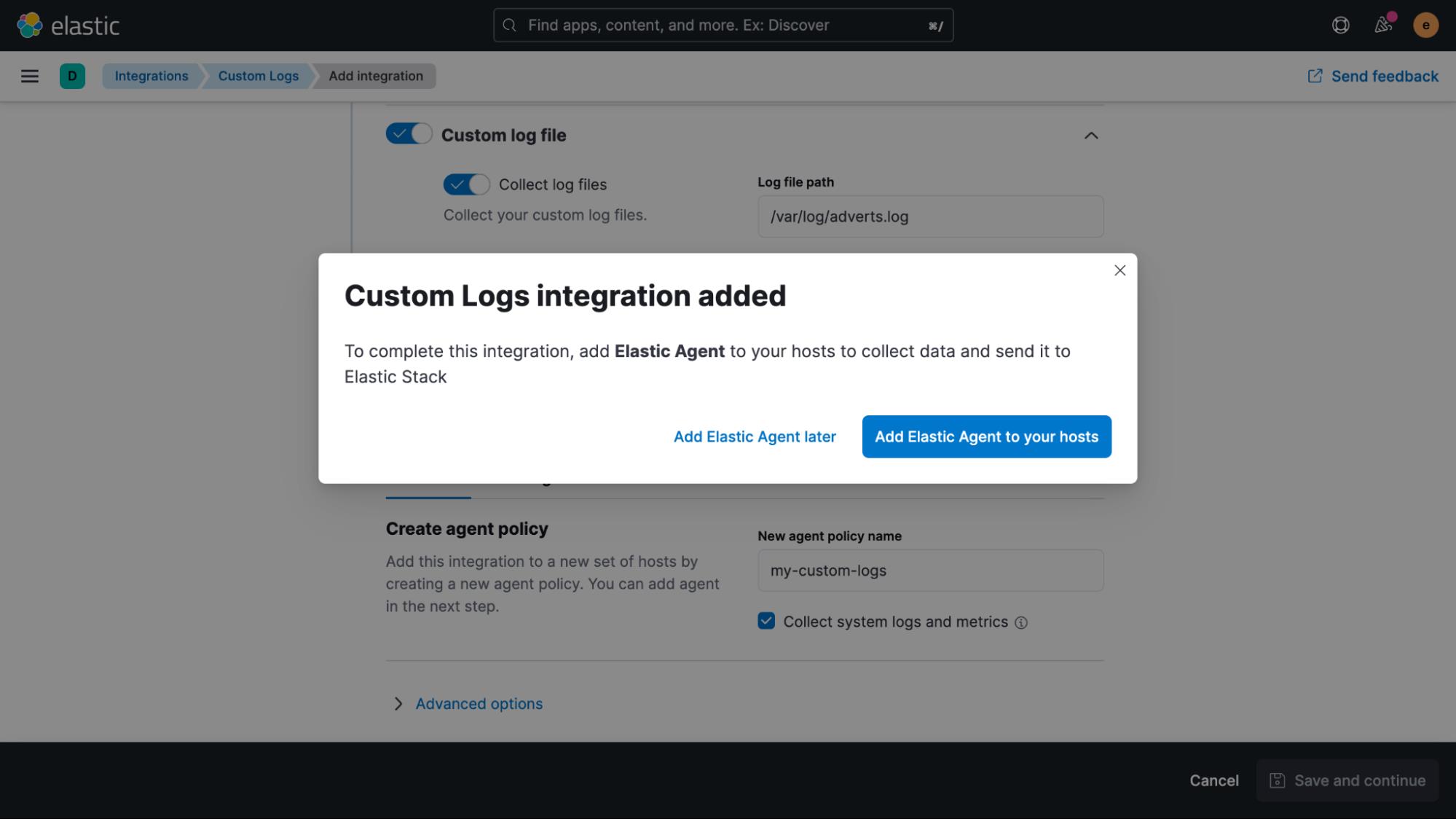
单击蓝色按钮并按照说明操作,只需几秒钟即可成功注册代理。 一旦数据流入 Elasticsearch,我们就可以在 Discover UI 中查看它。
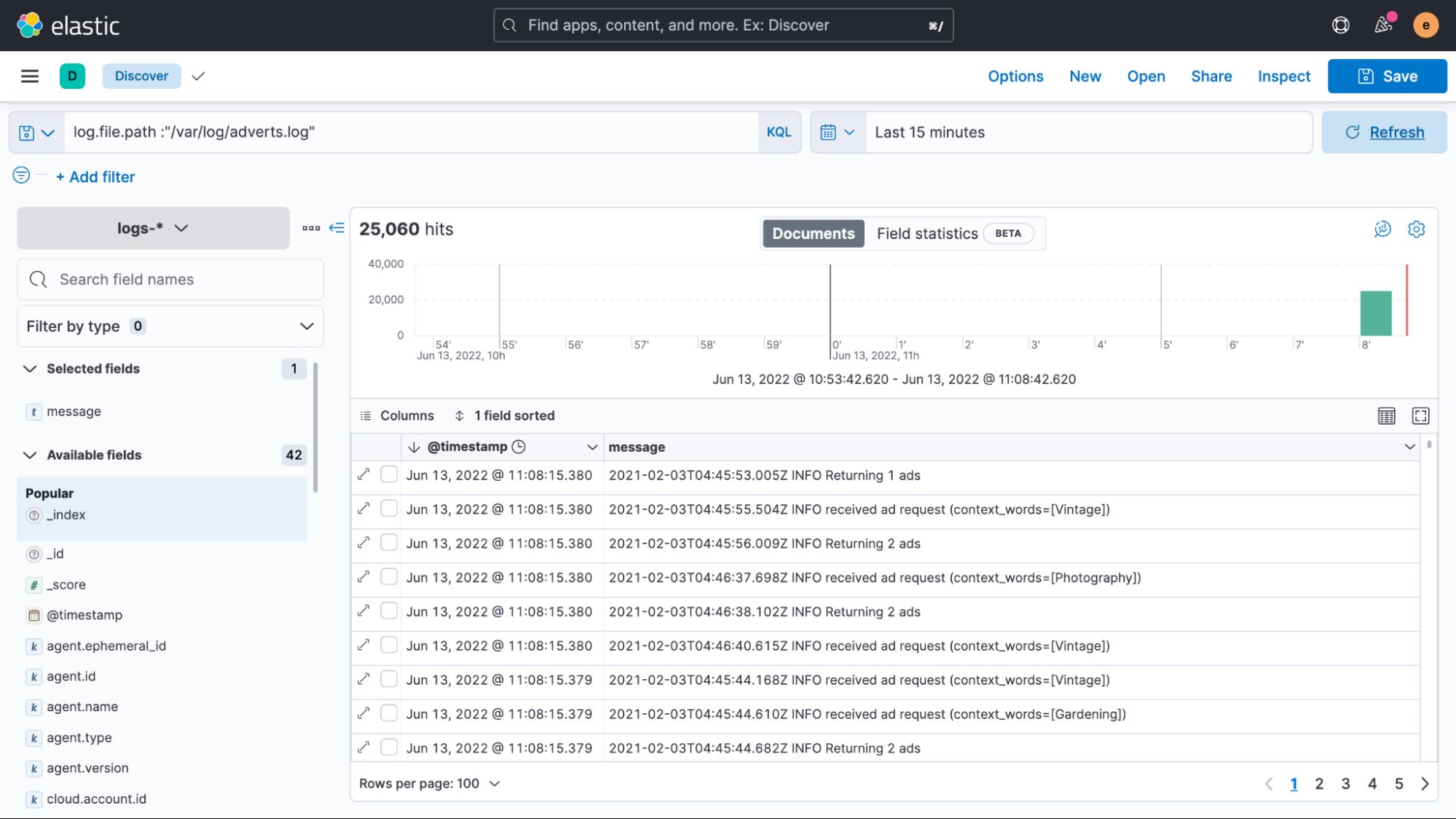
好消息是我们设法轻松地将日志文件数据编入索引。 不幸的是,它都显示为最新数据,即使日志中的时间戳表示完全不同的内容。
每当 Elastic Agent 或 Filebeat 读取非结构化数据时,它会自动为其添加一个包含当前时间的时间戳字段。 在大多数情况下,这很有效,因为在将条目写入文件后,几乎会立即收集日志数据。 但是,如果出现延迟或者正在处理较旧的文件,那么使用这样的时间戳可能会产生误导。 如果你想了解更多信息,我们在集中日志中时间戳的注意事项博客中讨论了很多关于时间戳的内容。
现在,让我们先尝试解决这个问题。
作为一般建议,在收集此类非结构化数据时,你应该采取的唯一步骤是提取写入日志时的时间戳。
完成此操作的最简单方法是使用摄取管道(ingest pipeline)。 但在我们开始之前,我们将复制一行日志并转到 Kibana 的 Management > DevTools > Grok Debugger 部分。 在此 UI 中,我们可以轻松创建和测试与我们的自定义日志格式匹配的表达式。 现在我们只对更正时间戳感兴趣,但你可能会说出这项技术在其他方面的用处。
匹配一个日志,使用下面的 Sample Data 和 grok pattern 来模拟测试结构化数据是否正确。
Sample Data:
2021-02-03T04:45:53.005Z INFO Returning 1 ads
Grok Pattern:
%TIMESTAMP_ISO8601:timestamp %GREEDYDATA:message 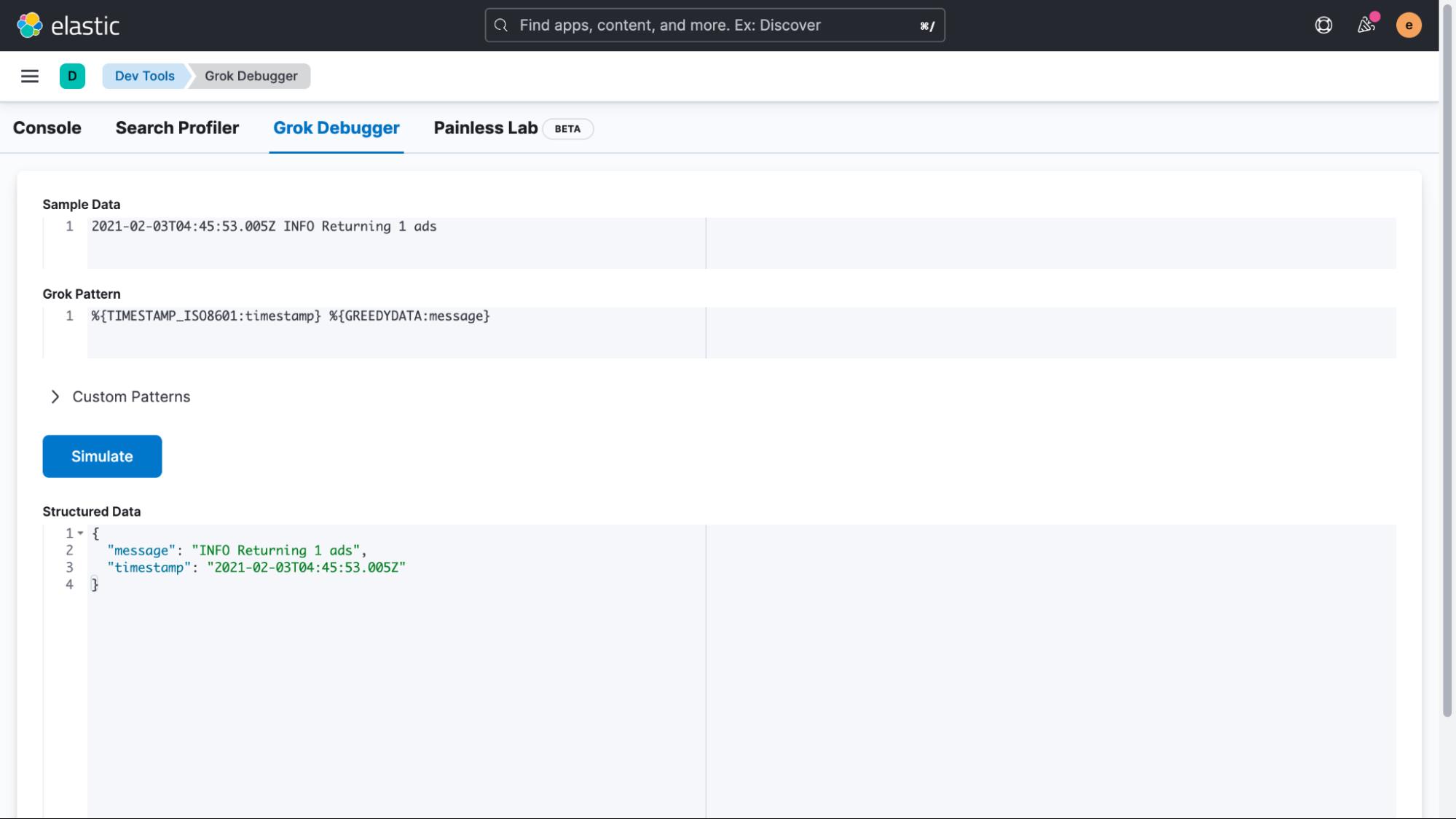
一旦返回的结构化数据被确认为良好,复制 Grok 模式并转到 “Management > Stack Management > Ingest Pipelines” UI,我们在其中创建一个新管道并添加一个 Grok 处理器和一个数据处理器。 在我们的示例中,我们将此管道称为 logs-timestamp。
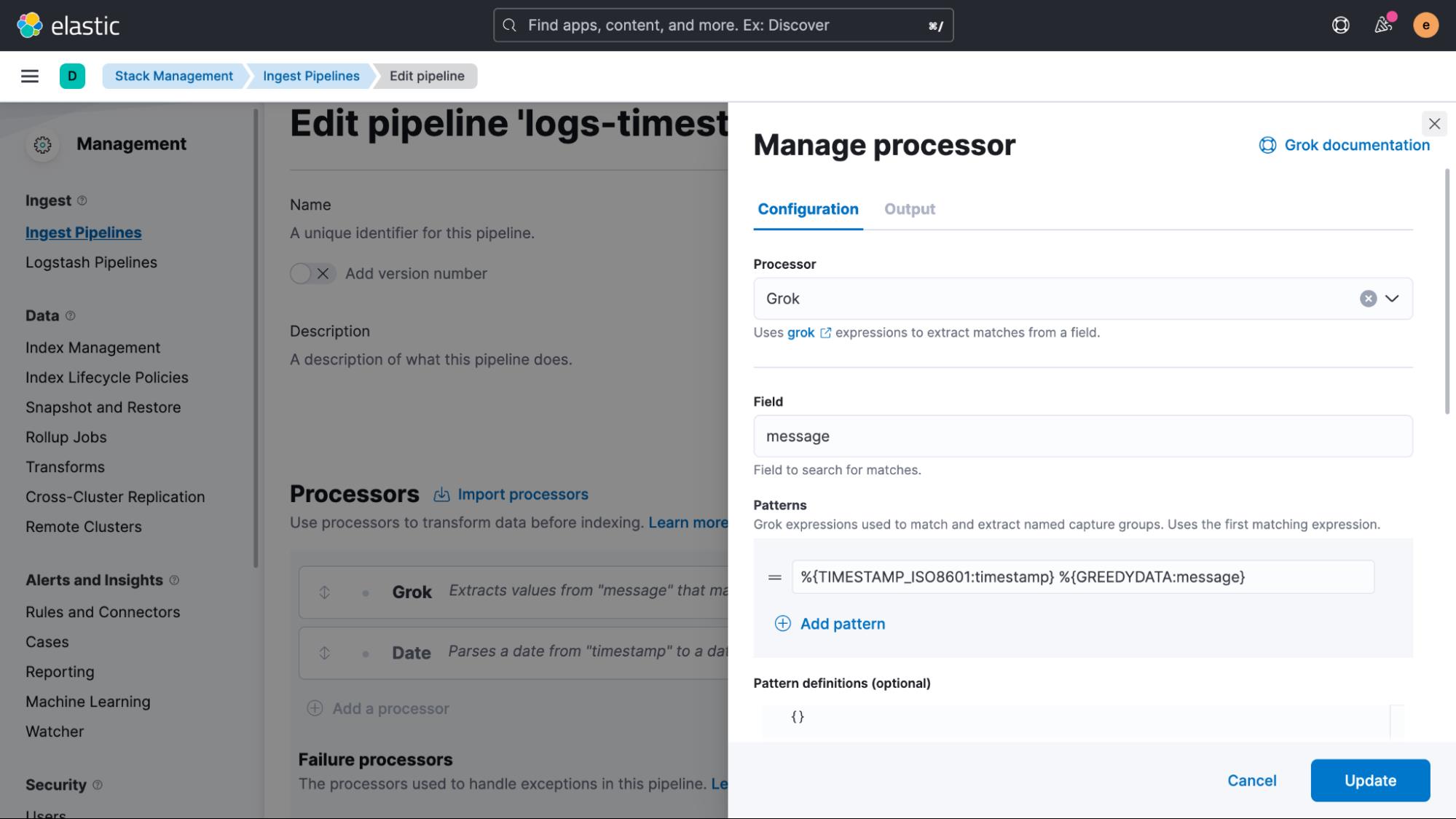
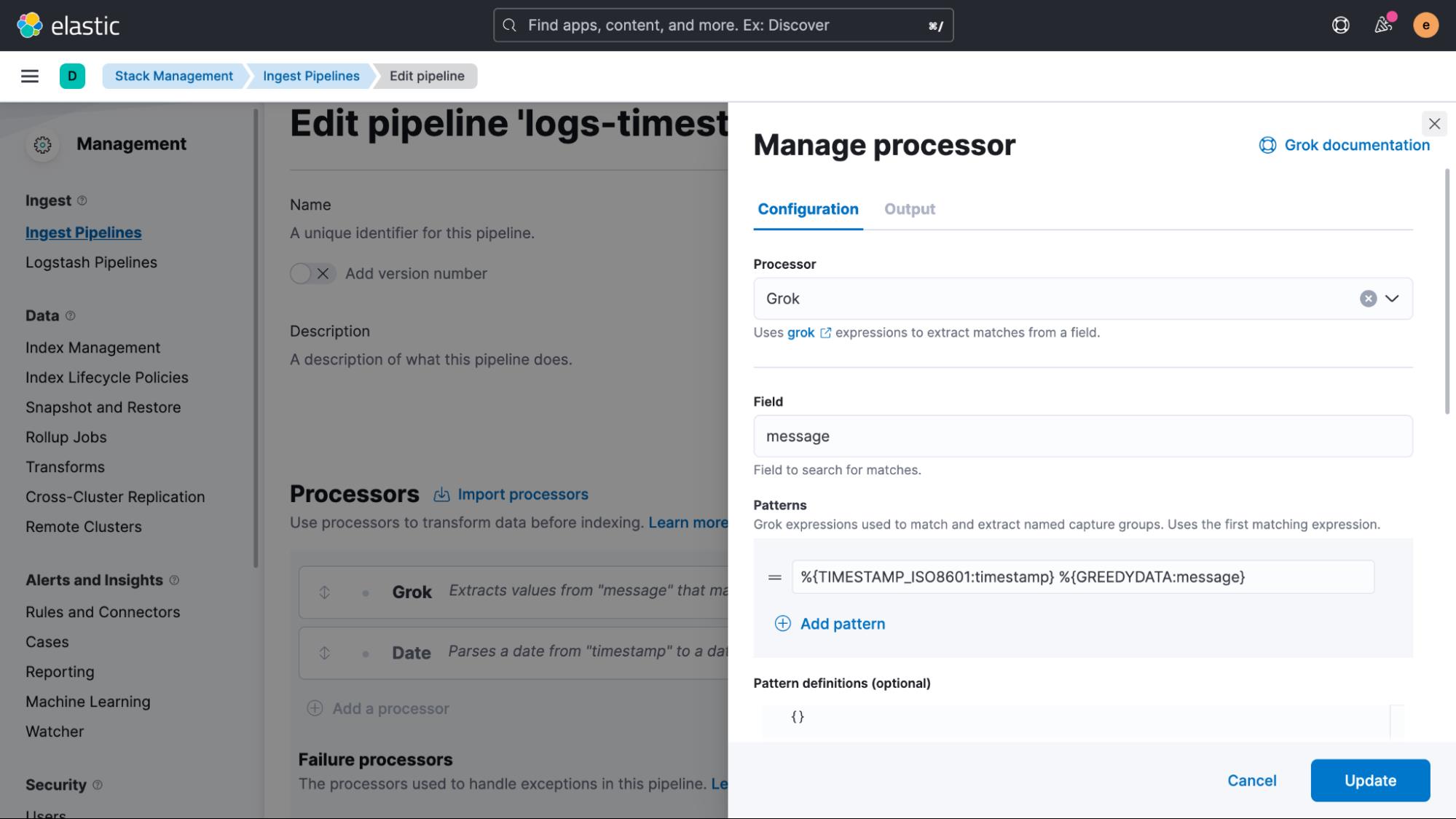
在 Grok 处理器定义中向下滚动并启用 Ignore failure 和 Ignore missing。 如果发生故障,这是避免阻塞管道的非常重要的一步。
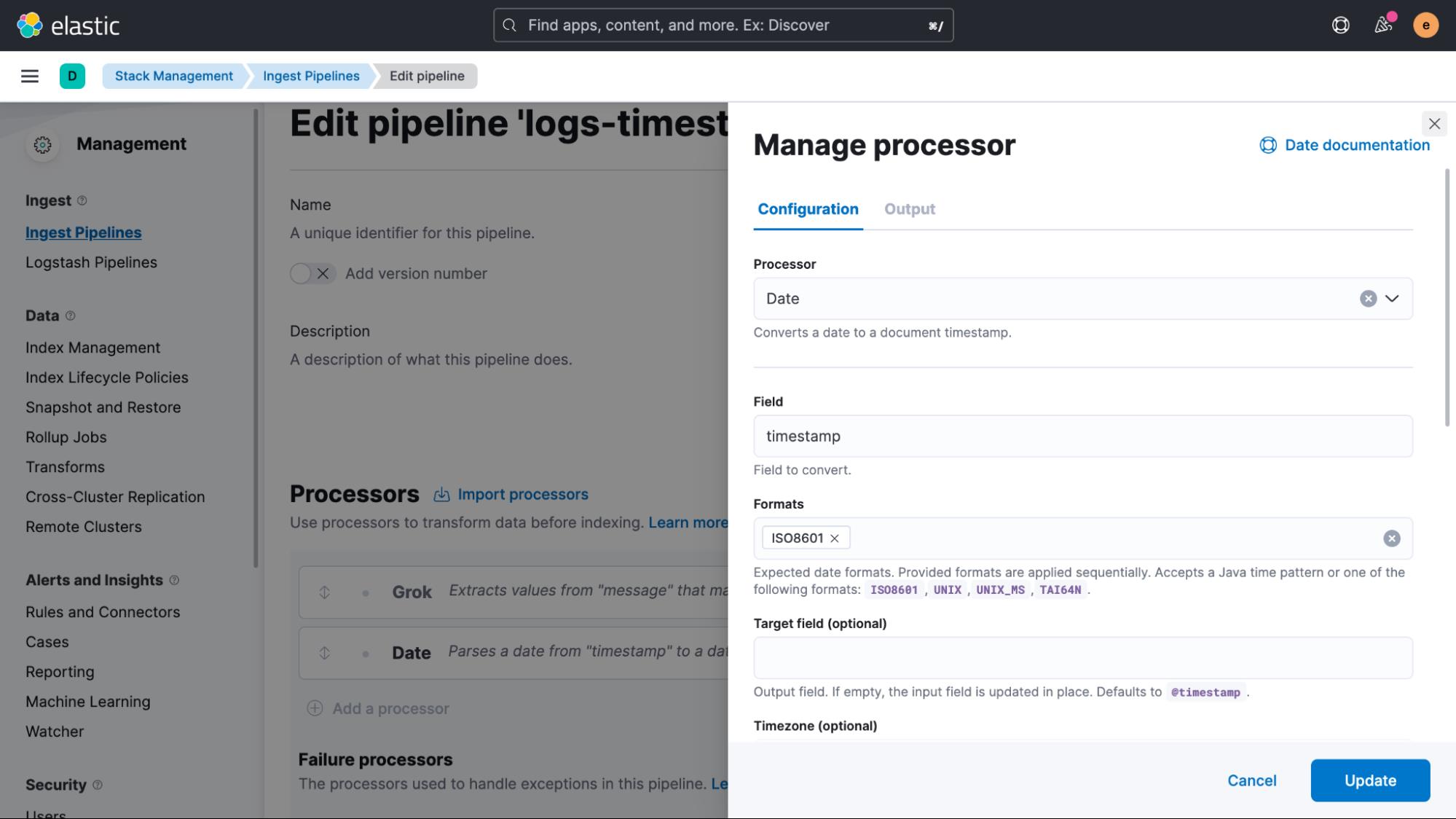
我们快完成了。 我们只剩下两个步骤来确保正确处理实时数据以及修复已经索引的旧数据。 首先从实时数据开始,我们将转到 “Management > Fleet” 并选择我们之前创建的 Agent Policy。 在策略视图中,我们然后单击自定义日志集成的名称以对其进行编辑。
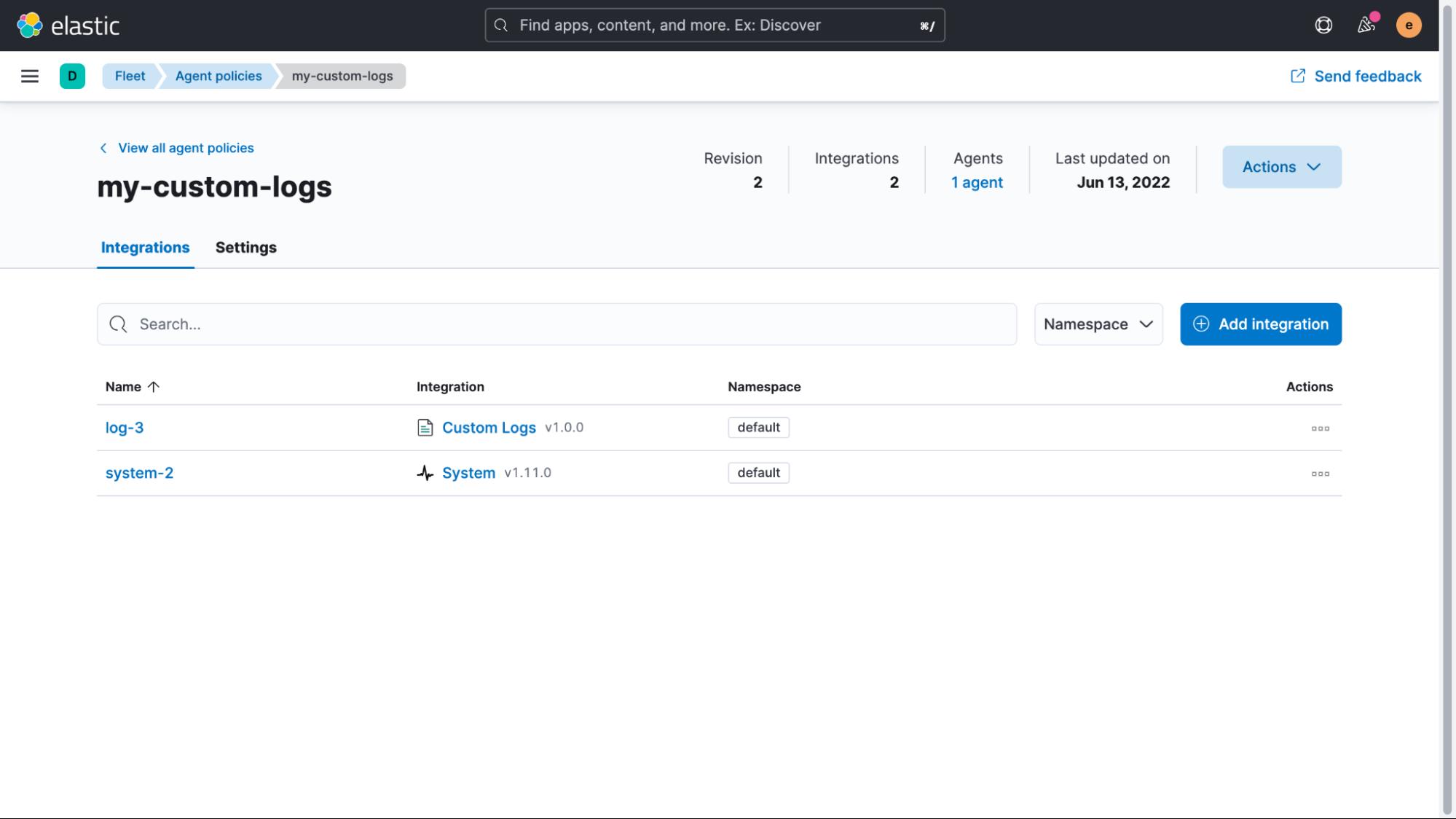
展开 Custom log file 部分,然后展开 Advanced options,我们可以添加 pipeline:logs-timestamp 作为自定义配置。
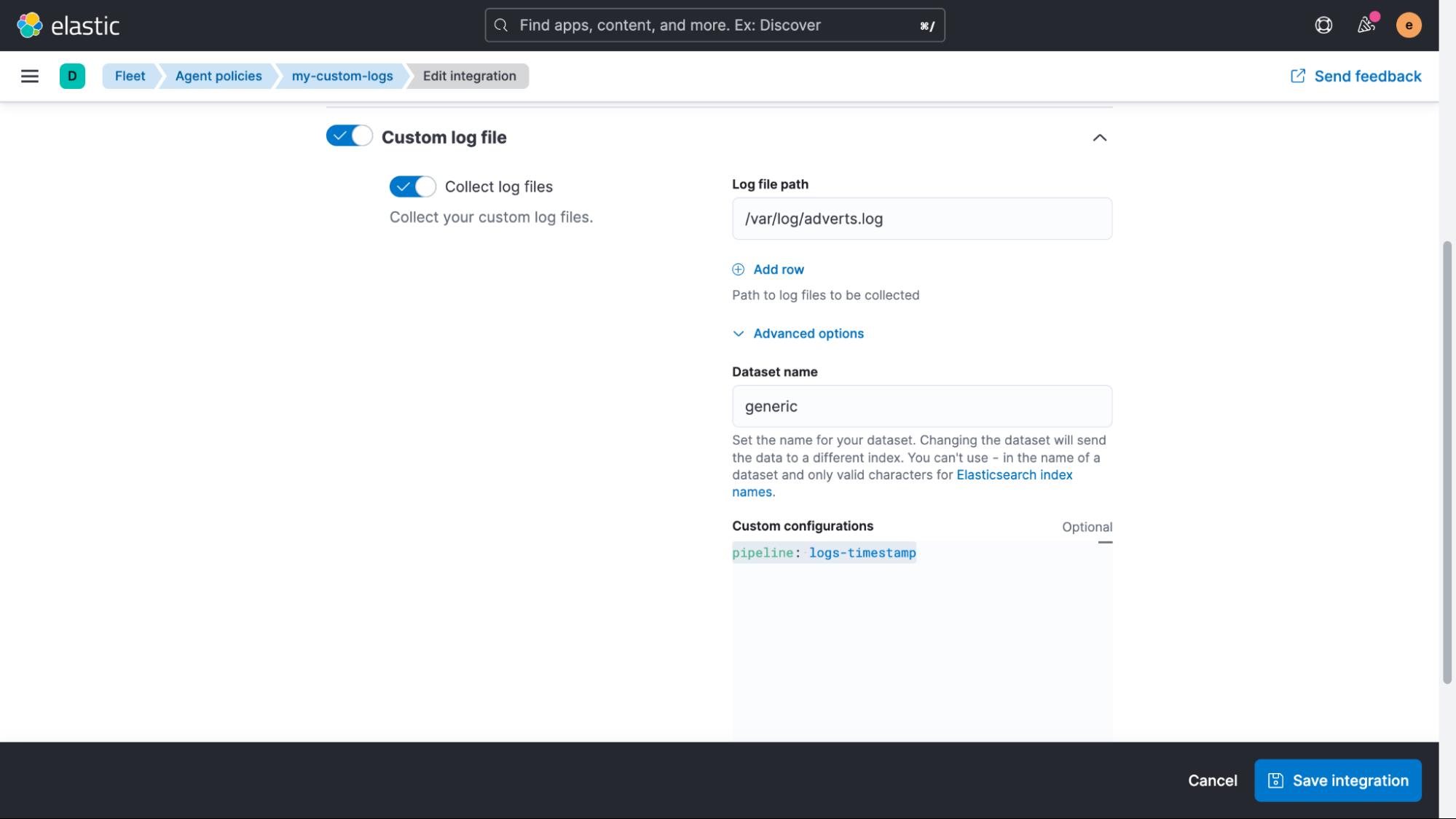
保存此配置后,所有实时数据都将通过管道并提取时间戳。
现在我们只需要修复已经索引的数据。 这里所需要的只是我们在 Management > DevTools > Console 中执行的单个请求。
POST logs-generic-default/_update_by_query?pipeline=logs-timestamp
"query":
"term":
"log.file.path":
"value": "/var/log/adverts.log"
这将从我们添加的路径中搜索所有日志,并通过管道发送它们来更新它们。 如果我们现在再次返回 Discover UI 查看日志,我们会看到时间戳已被正确解析和更新。
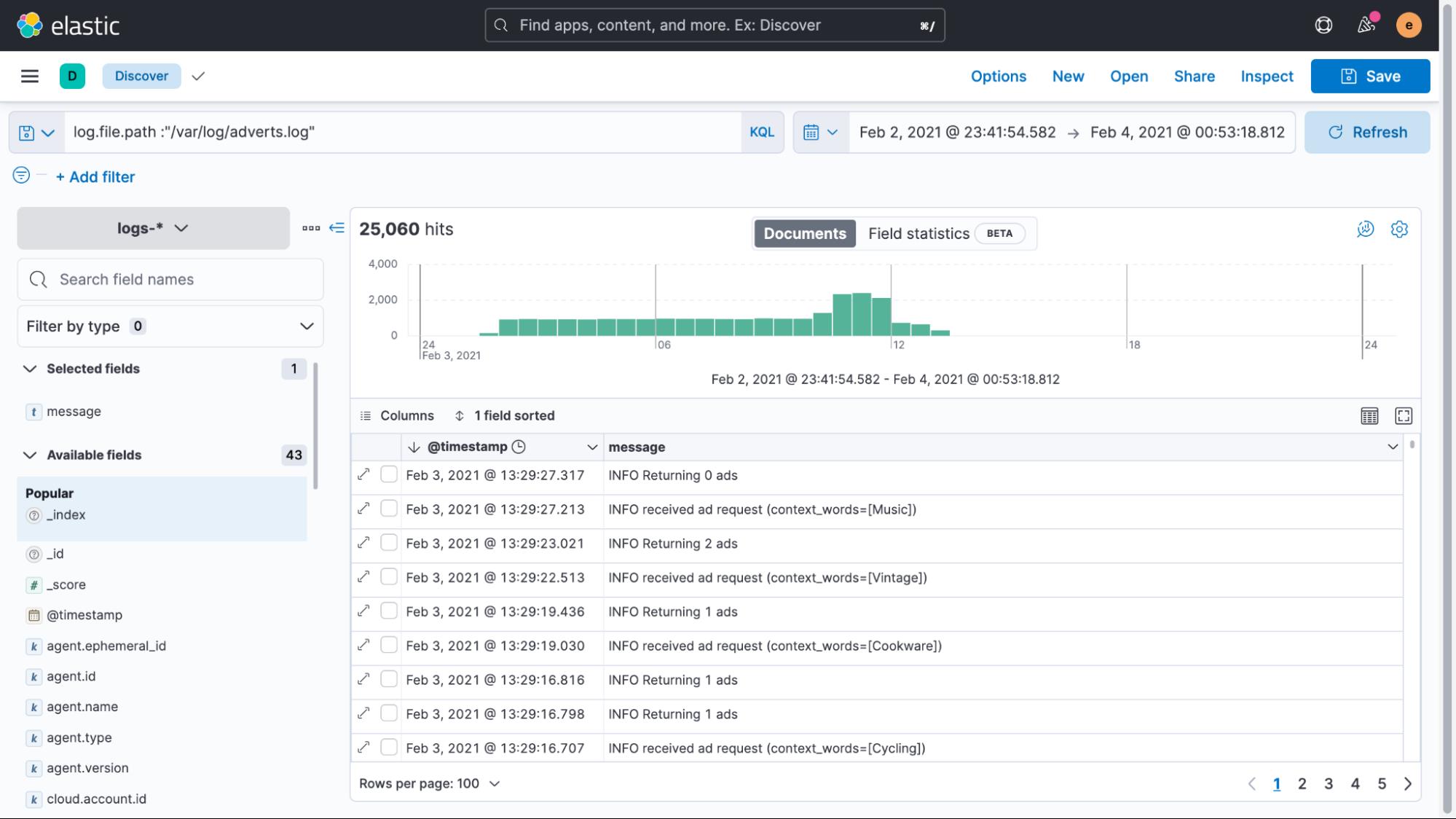
正如我们之前提到的,这是索引自定义日志的最重要的一步。 从技术上讲,这些修复是可选的,但这样做可以让你从非结构化日志中获得最大价值。 日志消息本身仍然是非结构化的,可以包含任何内容——文本日志、数字、期望值、错误,应有尽有。
如果你在 Discover 中展开并查看你的日志事件之一,你可能会注意到事情并不像你想象的那样非结构化。
举个例子,例子中使用的主机运行在 GCP 中。 在没有任何额外配置的情况下,除了主机级别的元数据之外,我们现在还可以获得云提供商特定字段的广泛元数据。 稍后进行日志分析时,此云提供商元数据非常强大。
此元数据允许你按一组主机或特定实例过滤或分组日志数据。 这一重要元数据的成本和开销也很低。 尽管除了我们开始的时间戳和消息之外还可以添加很多字段,但这些额外的数据字段可以非常有效地压缩,因为它们始终包含特定来源的相同信息。
我们可以用这样的非结构化日志数据做什么?
搜索一下! 在搜索数 TB 的数据时,Elasticsearch 非常强大且快速。 由于它默认为每个文档的内容编制索引,因此搜索所有内容变得快速而容易。
在使用 Kibana 时对应用程序或服务器进行故障排除的一种常见方法是简单地打开 Discover UI 并开始搜索。 首先排除所有你不感兴趣的日志,方法是根据字段值删除它们或使用 Kibana 查询语言 (KQL) 进行完整测试搜索。 你可以在此处找到有关 Kibana 查询语言的更多信息,但让我们看一些示例:
Exact term matching (OR query)
http.response.status_code:400 401 404
Phrase Matching
http.response.body.content.text:"quick brown fox"
OR query on different fields
response:200 or extension:php
Exclude terms
not INFO
Wildcard matching
kubernetes.pod.name:advert*在此博客中,我们了解了如何快速加入额外的数据源,即使它是自定义日志数据。 这种丰富将使你能够从日志中获得更多价值,并最终帮助你更快地排除应用程序故障或通过能够跟踪 KPI 为你的业务创造价值。
在本日志系列的下一篇文章中,我们将开始使用数据并介绍一些额外的概念来进行额外的解析,同时使用摄取管道,但也会回顾一种带有运行时字段的更临时的方法。 在未来的博客中,我们将专注于构建仪表板并讨论围绕数据保留和信息生命周期管理 (ILM) 的策略。
更多阅读 Observability:如何使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中。
以上是关于Observability:日志监控和非结构化日志数据,超越 tail -f的主要内容,如果未能解决你的问题,请参考以下文章
Observability:从零开始创建 Java 微服务并监控它
Observability:从零开始创建 Java 微服务并监控它
Observability:从零开始创建 Java 微服务并监控它
Observability:使用 Elastic Agent 来摄入日志及指标 - Elastic Stack 8.0
Observability:如何在使用 Elastic Agents 把多行的日志摄入到 Elasticsearch 中