ElasticSearch_04_批量处理命令mget和bulk的使用
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch_04_批量处理命令mget和bulk的使用相关的知识,希望对你有一定的参考价值。
系列文章目录
文章目录
前言
使用批量处理命令可以提高速度,包括mget和bulk两个命令。
一、批量处理命令mget
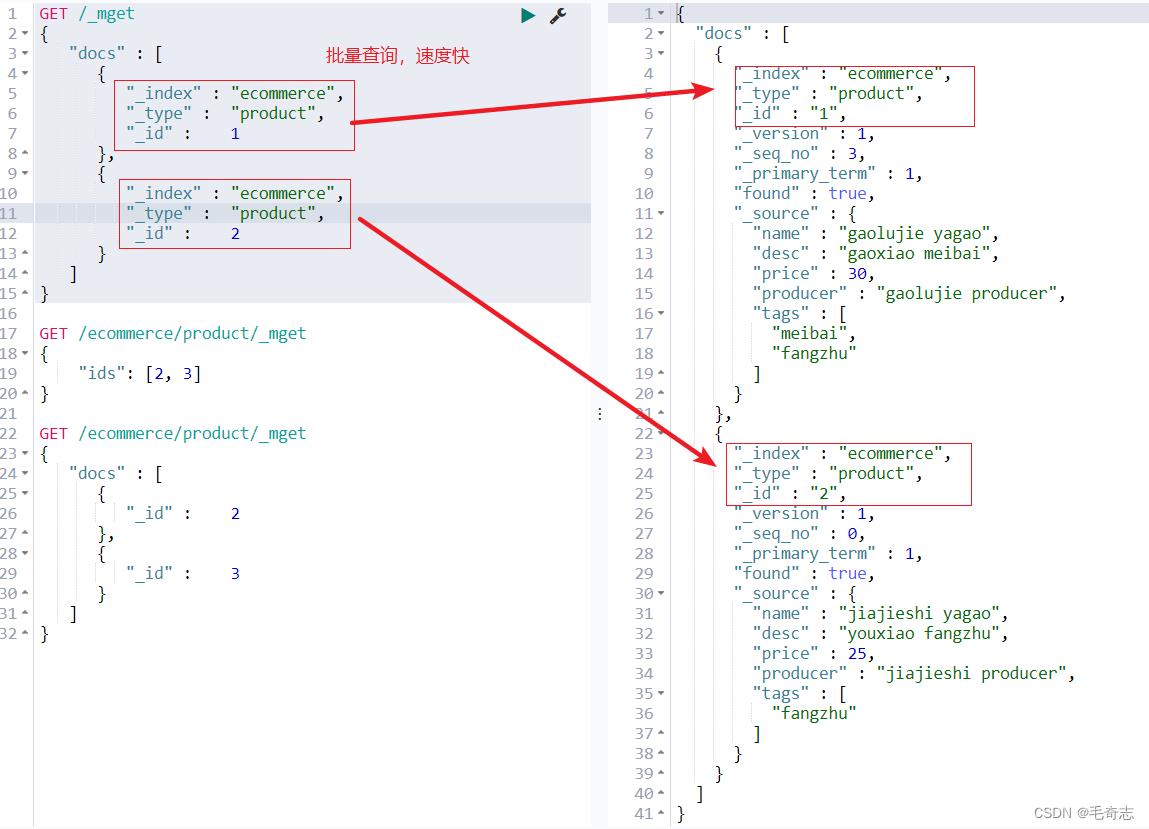
方案1:body请求体中指定index和type
GET /_mget
"docs" : [
"_index" : "ecommerce",
"_type" : "product",
"_id" : 1
,
"_index" : "ecommerce",
"_type" : "product",
"_id" : 2
]
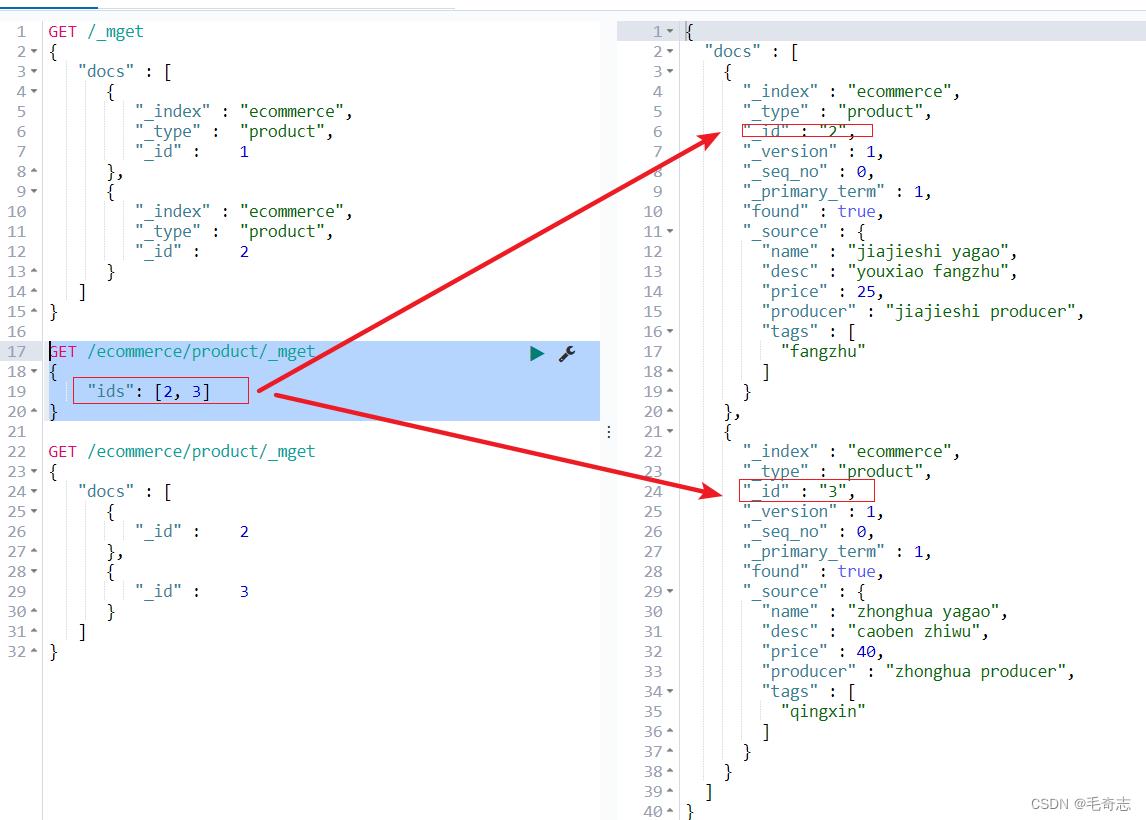
方案2:url中指定index和type,body中仅指定ids
GET /ecommerce/product/_mget
"ids": [2, 3]
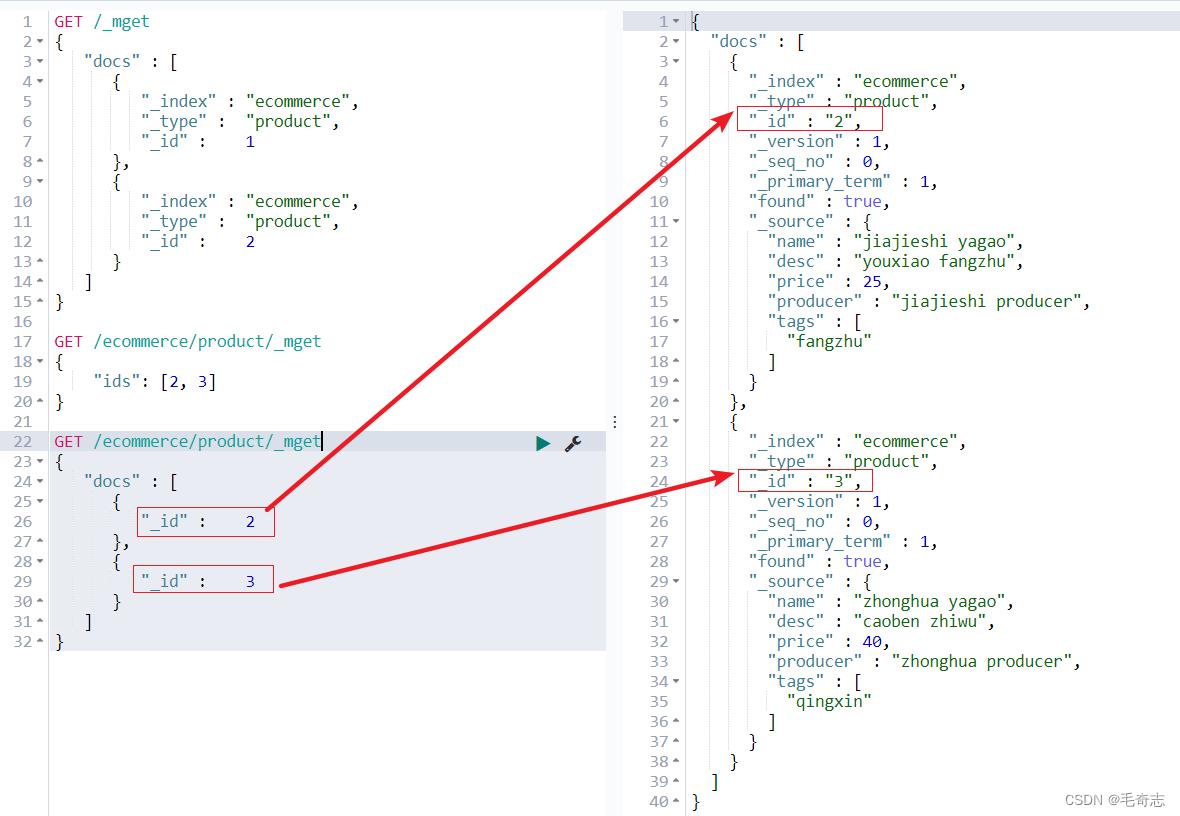
方案2扩展:url中指定index和type,body中仅指定id数组
GET /ecommerce/product/_mget
"docs" : [
"_id" : 2
,
"_id" : 3
]
二、基于bulk的增删改
2.1 bulk api语法
bulk api语法
delete:删除一个文档,只要1个json串就可以了
create:PUT /index/type/id/_create,强制创建
index:普通的put操作,可以是创建文档,也可以是全量替换文档
update:执行的partial update操作
注意点
1.bulk api对json的语法有严格的要求,除了delete外,每一个操作都要两个json串,且每个json串内不能换行,非同一个json串必须换行,否则会报错;
2.bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志;
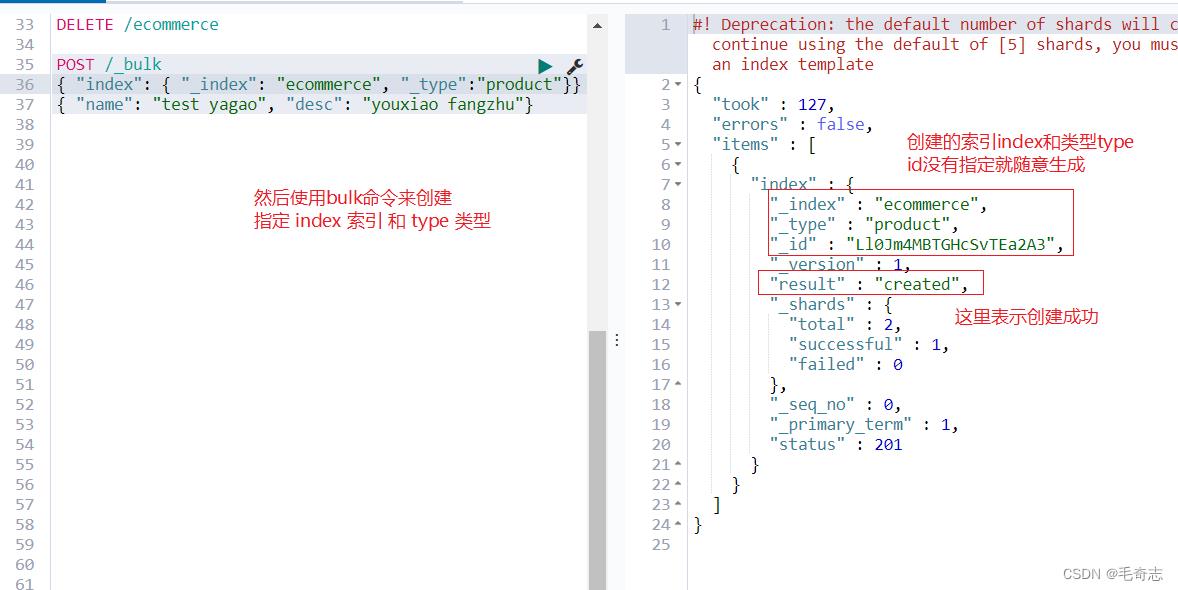
1、创建文档index
# 删除指定名称索引
DELETE /ecommerce

# 使用bulk命令Post创建文档index
POST /_bulk
"index": "_index": "ecommerce", "_type":"product"
"name": "test yagao", "desc": "youxiao fangzhu"
# 查询所有索引
GET /_cat/indices?v&pretty

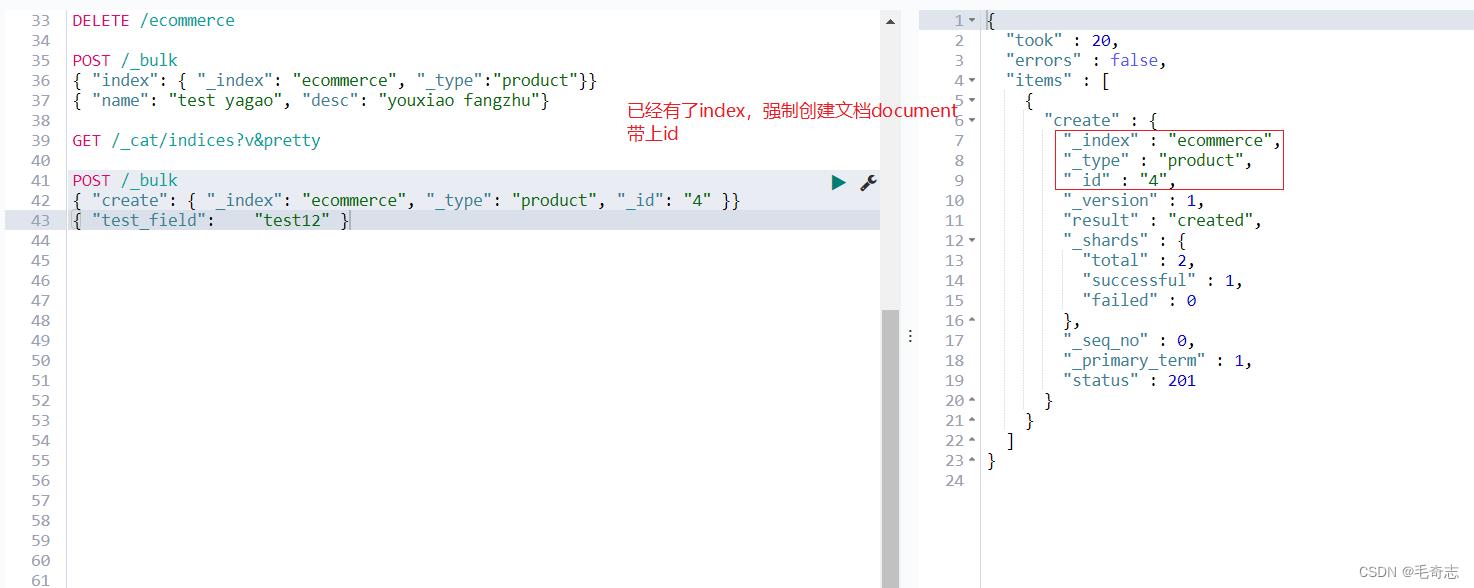
2、强制创建文档create
POST /_bulk
"create": "_index": "ecommerce", "_type": "product", "_id": "4"
"test_field": "test12"
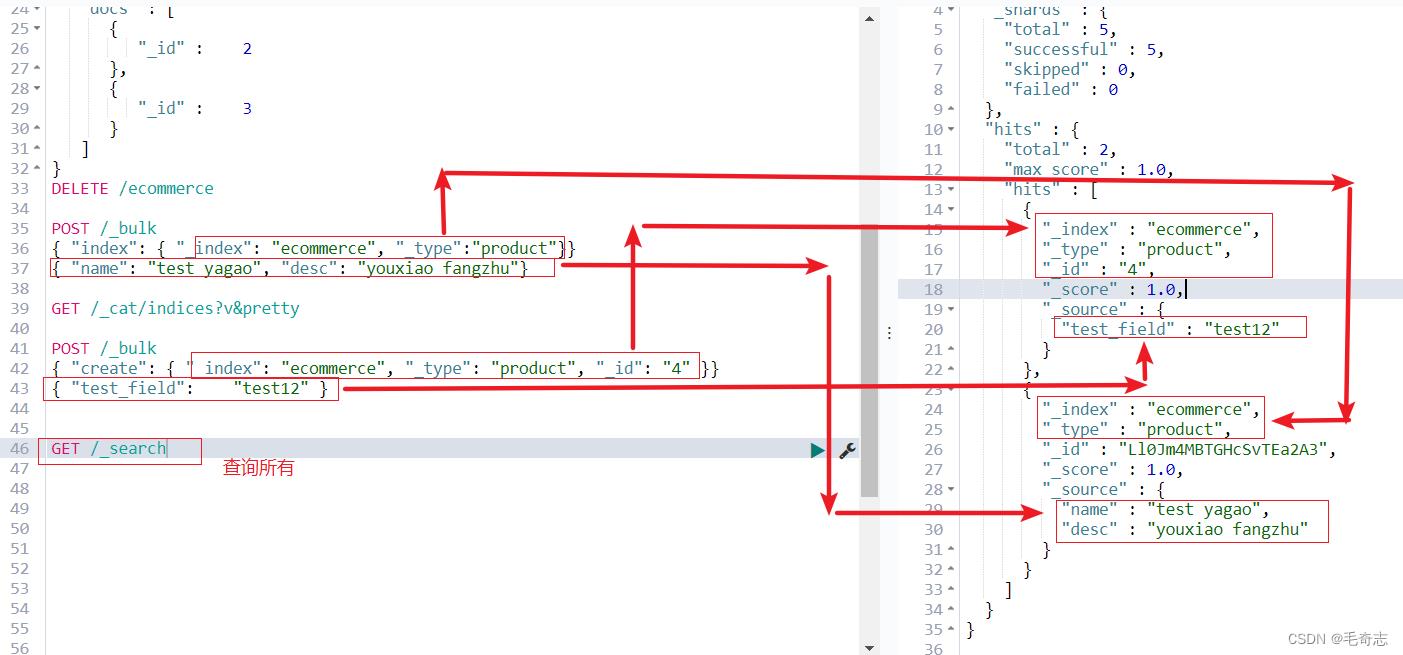
3、修改文档update
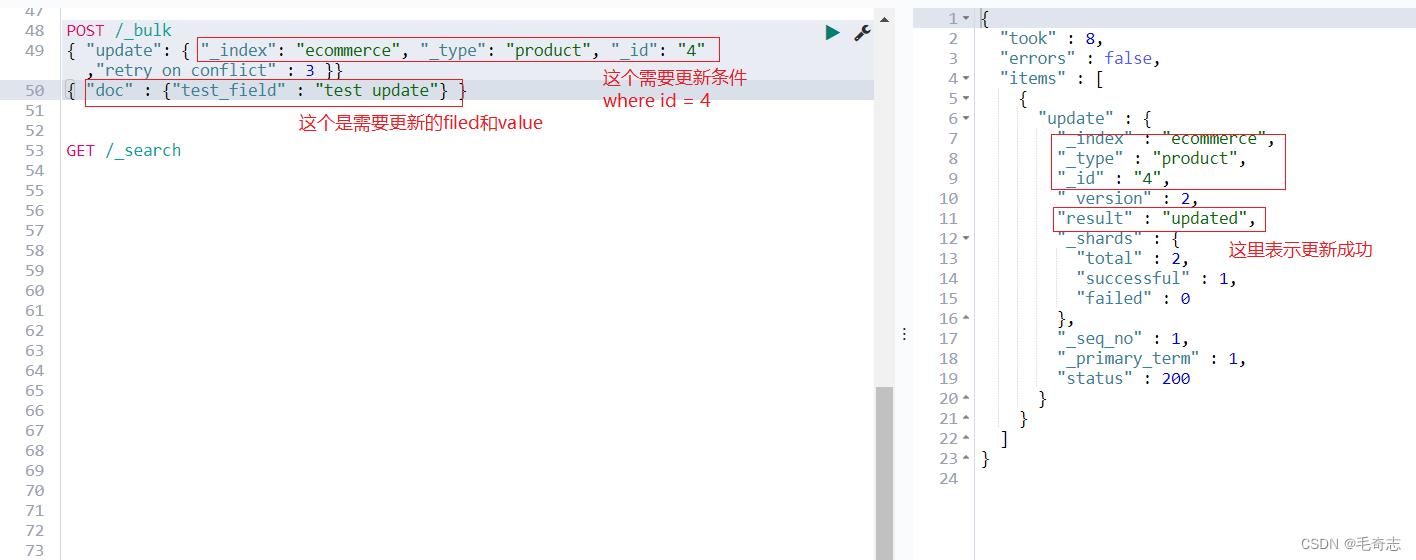
POST /_bulk
"update": "_index": "ecommerce", "_type": "product", "_id": "4","retry_on_conflict" : 3
"doc" : "test_field" : "test update"
GET /_search
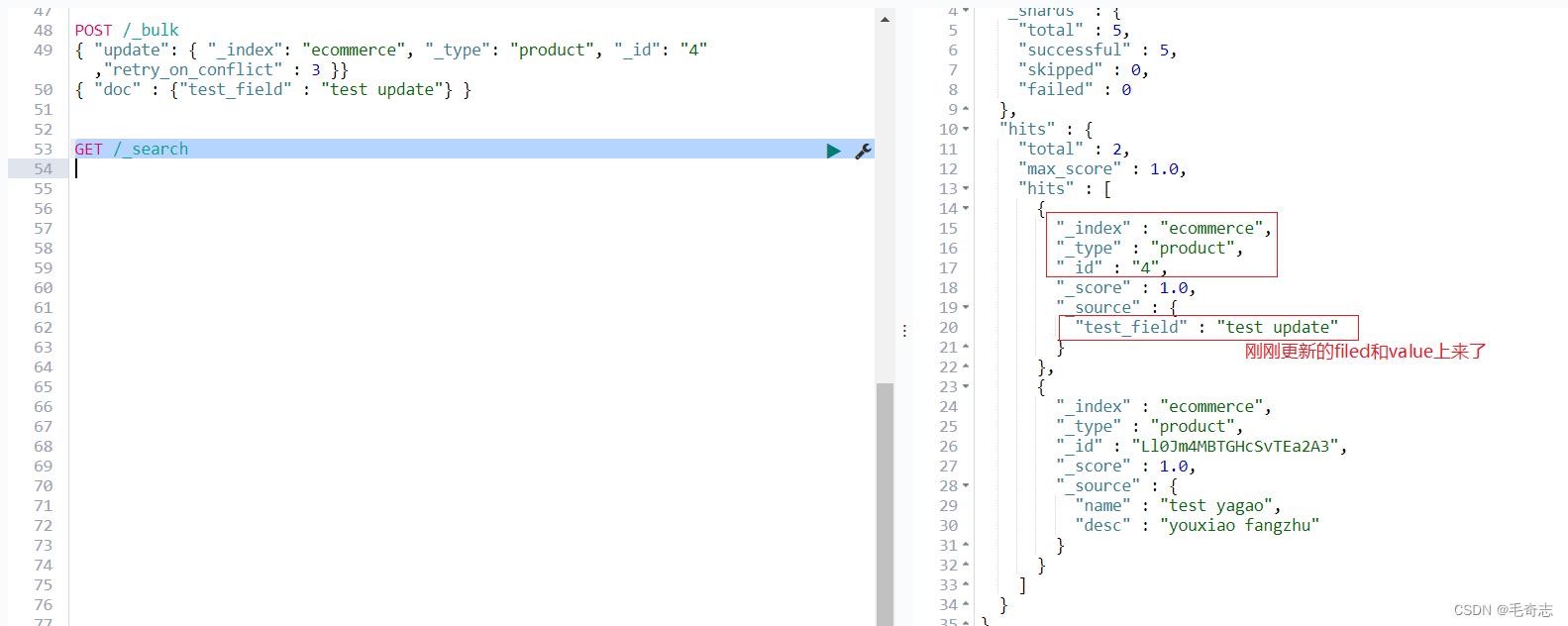
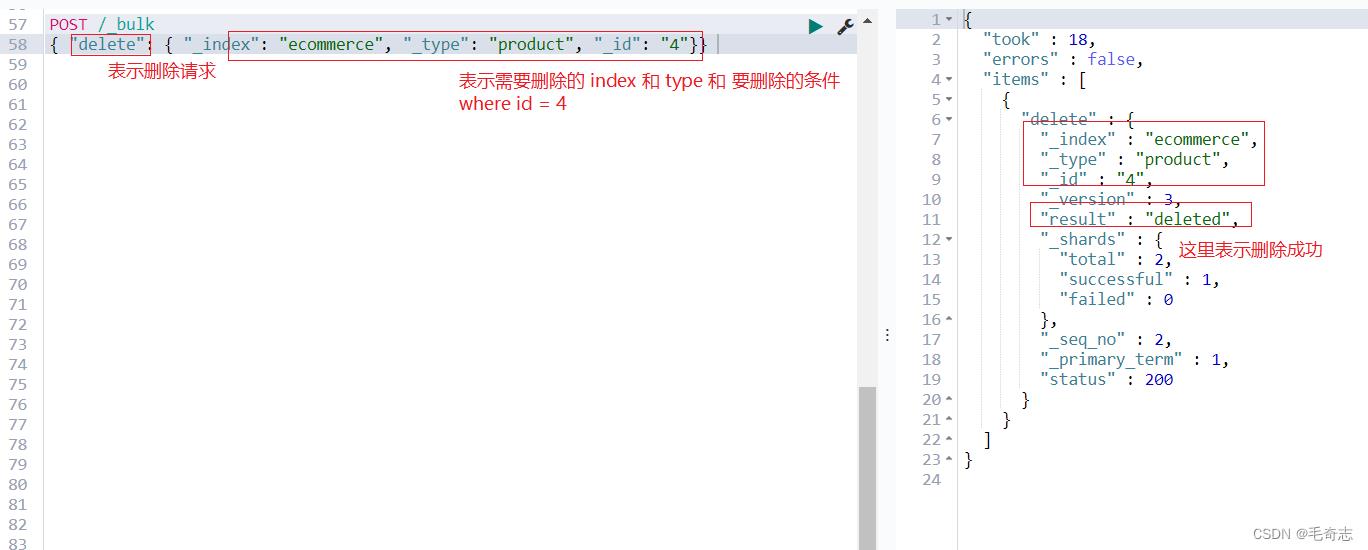
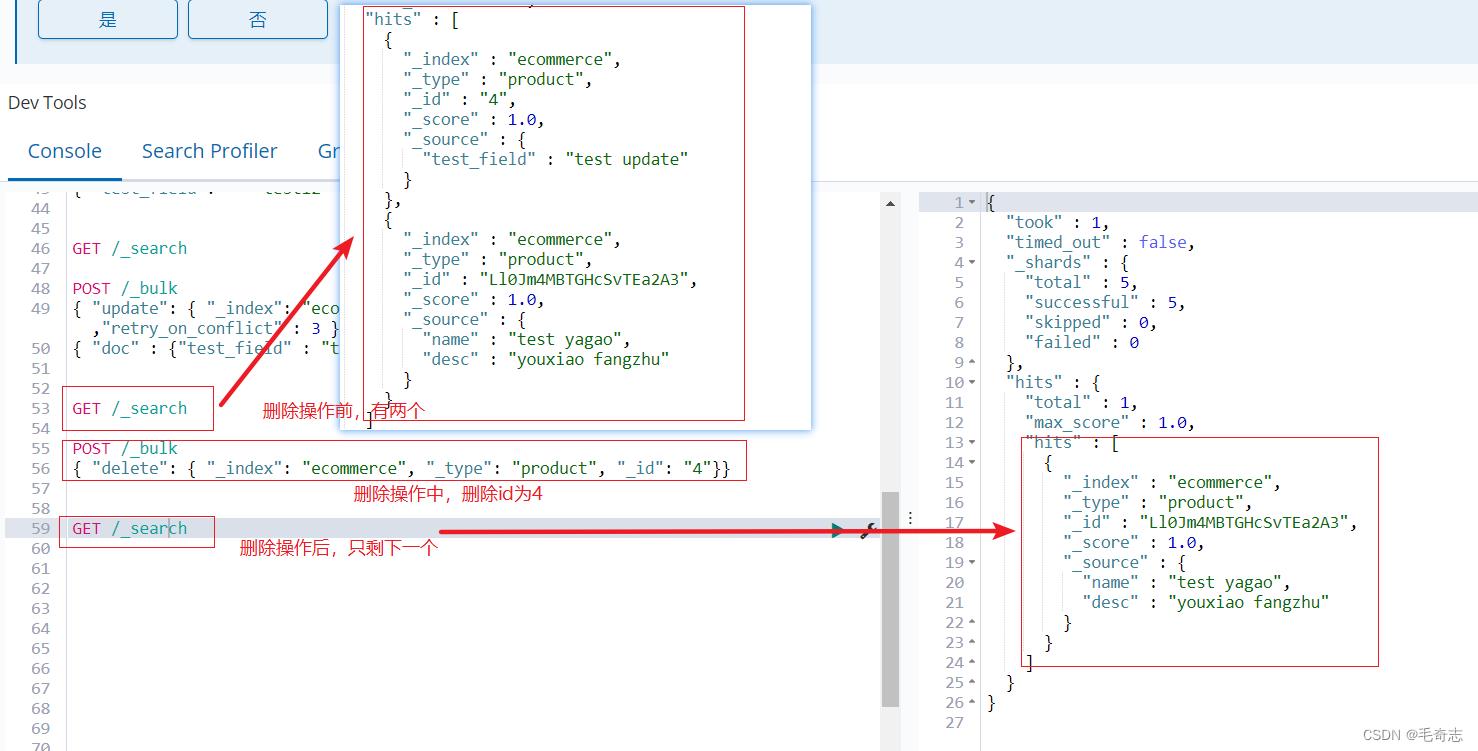
4、删除文档delete
GET /_search
POST /_bulk
"delete": "_index": "ecommerce", "_type": "product", "_id": "4"
GET /_search
2.2 bulk api奇特的json格式
目前处理流程/基本api处理流程
1、直接按照换行符切割json,不用将其转换为json对象,不会出现内存中的相同数据的拷贝;
2、对每两个一组的json,读取meta,进行document路由;
3、直接将对应的json发送到node上去;
换成良好json格式的处理流程
1、将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象;
2、解析json数组里的每个json,对每个请求中的document进行路由;
3、为路由到同一个shard上的多个请求,创建一个请求数组;
4、将这个请求数组序列化;
5、将序列化后的请求数组发送到对应的节点上去;
奇特格式的优缺点
缺点:可读性差;
优点:不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,能够尽可能地保证性能;
例如:
bulk size最佳大小一般建议说在几千条,大小在10MB左右。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降。
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多。
总结
使用批量处理命令可以提高速度,包括mget和bulk两个命令。
所有命令
GET /_mget
"docs" : [
"_index" : "ecommerce",
"_type" : "product",
"_id" : 1
,
"_index" : "ecommerce",
"_type" : "product",
"_id" : 2
]
GET /ecommerce/product/_mget
"ids": [2, 3]
GET /ecommerce/product/_mget
"docs" : [
"_id" : 2
,
"_id" : 3
]
DELETE /ecommerce
POST /_bulk
"index": "_index": "ecommerce", "_type":"product"
"name": "test yagao", "desc": "youxiao fangzhu"
GET /_cat/indices?v&pretty
POST /_bulk
"create": "_index": "ecommerce", "_type": "product", "_id": "4"
"test_field": "test12"
GET /_search
POST /_bulk
"update": "_index": "ecommerce", "_type": "product", "_id": "4","retry_on_conflict" : 3
"doc" : "test_field" : "test update"
GET /_search
POST /_bulk
"delete": "_index": "ecommerce", "_type": "product", "_id": "4"
GET /_search
以上是关于ElasticSearch_04_批量处理命令mget和bulk的使用的主要内容,如果未能解决你的问题,请参考以下文章