Go 性能优化之pprof 实战
Posted 技术能量站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go 性能优化之pprof 实战相关的知识,希望对你有一定的参考价值。
一、前言
如果要说在 golang 开发过程进行性能调优,pprof 一定是一个大杀器般的工具。但在网上找到的教程都偏向简略,难寻真的能应用于实战的教程。这也无可厚非,毕竟 pprof 是当程序占用资源异常时才需要启用的工具,而我相信大家的编码水平和排查问题的能力是足够高的,一般不会写出性能极度堪忧的程序,且即使发现有一些资源异常占用,也会通过排查代码快速定位,这也导致 pprof 需要上战场的机会少之又少。即使大家有心想学习使用 pprof,却也常常相忘于江湖。
想要进行性能优化,首先瞩目在 Go 自身提供的工具链来作为分析依据,本文将带你学习、使用 Go 后花园,涉及如下:
- runtime/pprof:采集程序(非 Server)的运行数据进行分析
- net/http/pprof:采集 HTTP Server 的运行时数据进行分析
二、pprof 基础
2.1 pprof 是什么
pprof 是用于可视化和分析性能分析数据的工具
pprof 以 profile.proto 读取分析样本的集合,并生成报告以可视化并帮助分析数据(支持文本和图形报告)
profile.proto 是一个 Protocol Buffer v3 的描述文件,它描述了一组 callstack 和 symbolization 信息, 作用是表示统计分析的一组采样的调用栈,是很常见的 stacktrace 配置文件格式
2.2 支持哪些模式
- Report generation:报告生成
- Interactive terminal use:交互式终端使用
- Web interface:Web 界面
2.3 可以做什么
- CPU Profiling:CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置
- Memory Profiling:内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏
- Block Profiling:阻塞分析,记录 goroutine 阻塞等待同步(包括定时器通道)的位置
- Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况
三、如何分析
基于go tool pprof工具分析
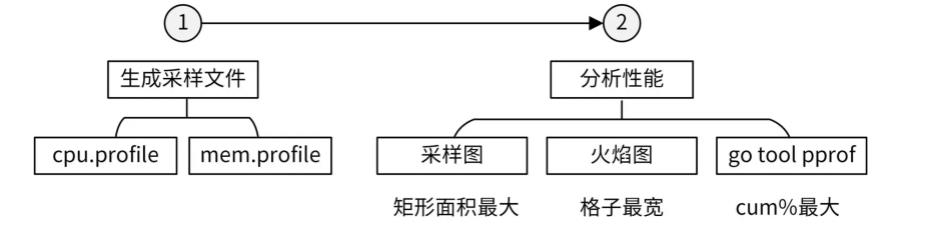
接下来,我先给你介绍下 pprof 工具,再介绍下如何生成性能数据,最后再分别介绍下 CPU 和内存性能分析方法。
3.1 生成性能数据
我们在做性能分析时,主要是对内存和 CPU 性能进行分析。为了分析内存和 CPU 的性能,我们需要先生成性能数据文件。
测试案例
// 文件名 pprof_test
package pprof
import "testing"
const url = "https://github.com/iswxw"
func TestAdd(t *testing.T)
s := AddList(url)
if s == ""
t.Errorf("Test.Add error!")
func BenchmarkAdd(b *testing.B)
for i := 0; i < b.N; i++
Add(url)
var dataList []string
func AddList(str string) string
data := []byte(str)
sData := string(data)
dataList = append(dataList, sData)
return sData
执行下面命令生成性能分析文件
$ go test -benchtime=30s -benchmem -bench=".*" -cpuprofile cpu.profile -memprofile mem.profile
goos: windows
goarch: amd64
pkg: src/com.wxw/project_actual/src/01_basic_grammar/27_pprof
cpu: AMD Ryzen 7 4700U with Radeon Graphics
BenchmarkAdd-8 runtime: VirtualAlloc of 3765600256 bytes failed with errno=1455
fatal error: out of memory
上面的命令会在当前目录下产生cpu.profile、mem.profile性能数据文件,以及v1.test二进制文件。接下来,我们基于cpu.profile、mem.profile、v1.test文件来分析代码的 CPU 和内存性能。为了获取足够的采样数据,我们将 benchmark 时间设置为30s。
在做性能分析时,我们可以采取不同的手段来分析性能,比如分析采样图、分析火焰图,还可以使用go tool pprof交互模式,查看函数 CPU 和内存消耗数据。下面我会运用这些方法,来分析 CPU 性能和内存性能。
3.2 CPU 性能分析
在默认情况下,Go 语言的运行时系统会以 100 Hz 的的频率对 CPU 使用情况进行采样,也就是说每秒采样 100 次,每 10 毫秒采样一次。每次采样时,会记录正在运行的函数,并统计其运行时间,从而生成 CPU 性能数据。
上面我们已经生成了 CPU 性能数据文件cpu.profile,接下来会运用上面提到的三种方法来分析该性能文件,优化性能。
3.2.1 方法一:分析采样图
要分析性能,最直观的方式当然是看图,所以首先我们需要生成采样图,生成过程可以分为两个步骤。
# 第一步,确保系统安装了graphviz:
$ sudo yum -y install graphviz.x86_64
# 第二步,执行go tool pprof生成调用图:
$ go tool pprof -svg cpu.profile > cpu.svg # svg 格式
$ go tool pprof -pdf cpu.profile > cpu.pdf # pdf 格式
$ go tool pprof -png cpu.profile > cpu.png # png 格式
以上命令会生成cpu.pdf、cpu.svg和cpu.png文件,文件中绘制了函数调用关系以及其他采样数据。如下图所示:
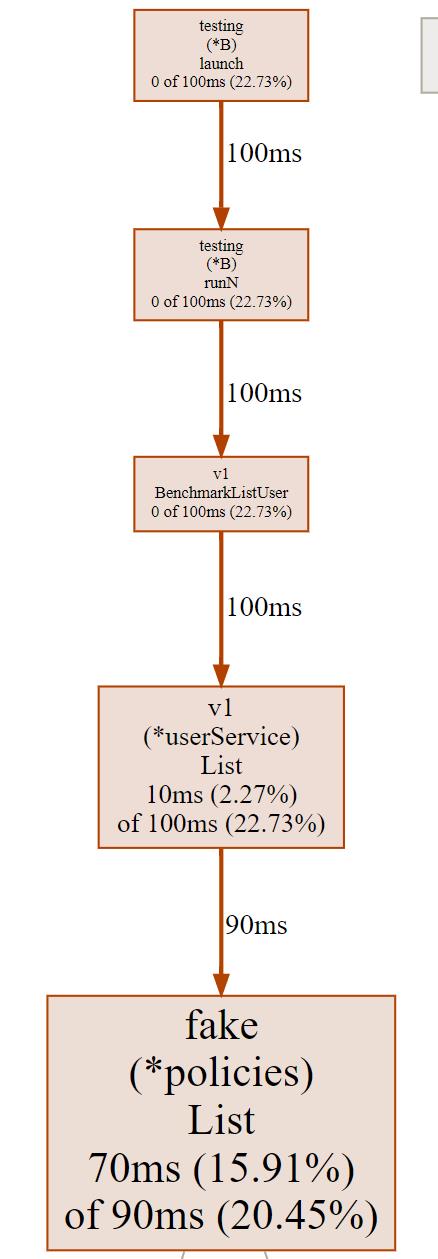
这张图片由有向线段和矩形组成。我们先来看有向线段的含义。
有向线段描述了函数的调用关系,矩形包含了 CPU 采样数据。从图中,我们看到没箭头的一端调用了有箭头的一端,可以知道v1.(*userService).List函数调用了fake.(*policies).List。
线段旁边的数字90ms则说明,v1.(*userService).List调用fake.(*policies).List函数,在采样周期内,一共耗用了90ms。通过函数调用关系,我们可以知道某个函数调用了哪些函数,并且调用这些函数耗时多久。
这里,我们再次解读下图中调用关系中的重要信息: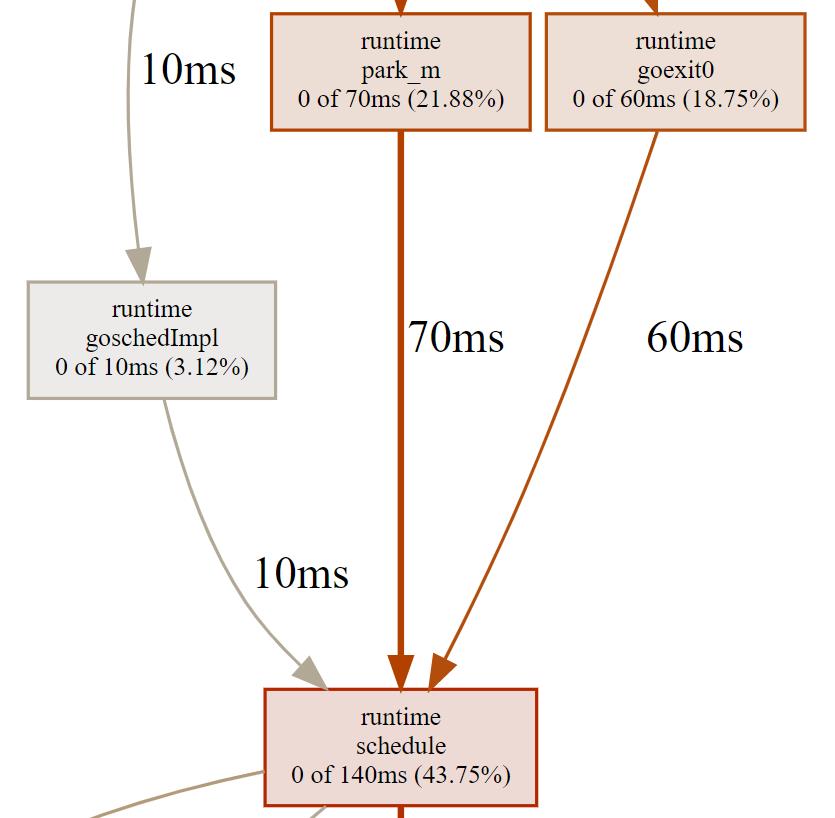
runtime.schedule的累积采样时间(140ms)中,有 10ms 来自于runtime.goschedImpl函数的直接调用,有 70ms 来自于runtime.park_m函数的直接调用。这些数据可以说明runtime.schedule函数分别被哪些函数调用,并且调用频率有多大。也因为这个原因,函数runtime.goschedImpl对函数runtime.schedule的调用时间必定小于等于函数runtime.schedule的累积采样时间。
我们再来看下矩形里的采样数据。这些矩形基本都包含了 3 类信息:
- 函数名 / 方法名,该类信息包含了包名、结构体名、函数名 / 方法名,方便我们快速定位到函数 / 方法,例如fake(*policies)List说明是 fake 包,policies 结构体的 List 方法。
- 本地采样时间,以及它在采样总数中所占的比例。本地采样时间是指采样点落在该函数中的总时间。累积采样时间,以及它在采样总数中所占的比例。
- 累积采样时间是指采样点落在该函数,以及被它直接或者间接调用的函数中的总时间。
我们可以通过OutDir函数来解释本地采样时间和累积采样时间这两个概念。OutDir函数如下图所示:

整个函数的执行耗时,我们可以认为是累积采样时间,包含了白色部分的代码耗时和红色部分的函数调用耗时。白色部分的代码耗时,可以认为是本地采样时间。
通过累积采样时间,我们可以知道函数的总调用时间,累积采样时间越大,说明调用它所花费的 CPU 时间越多。但你要注意,这并不一定说明这个函数本身是有问题的,也有可能是函数所调用的函数性能有瓶颈,这时候我们应该根据函数调用关系顺藤摸瓜,去寻找这个函数直接或间接调用的函数中最耗费 CPU 时间的那些。
如果函数的本地采样时间很大,就说明这个函数自身耗时(除去调用其他函数的耗时)很大,这时候需要我们分析这个函数自身的代码,而不是这个函数直接或者间接调用函数的代码。
采样图中,矩形框面积越大,说明这个函数的累积采样时间越大。那么,如果一个函数分析采样图中的矩形框面积很大,这时候我们就要认真分析了,因为很可能这个函数就有需要优化性能的地方。
3.2.2 方法二:分析火焰图
上面介绍的采样图,其实在分析性能的时候还不太直观,这里我们可以通过生成火焰图,来更直观地查看性能瓶颈。火焰图是由 Brendan Gregg 大师发明的专门用来把采样到的堆栈轨迹(Stack Trace)转化为直观图片显示的工具,因整张图看起来像一团跳动的火焰而得名。
go tool pprof提供了-http参数,可以使我们通过浏览器浏览采样图和火焰图。执行以下命令:
go tool pprof -http="0.0.0.0:8081" v1.test cpu.profile
然后访问http://x.x.x.x:8081/(x.x.x.x是执行go tool pprof命令所在服务器的 IP 地址),则会在浏览器显示各类采样视图数据,如下图所示:
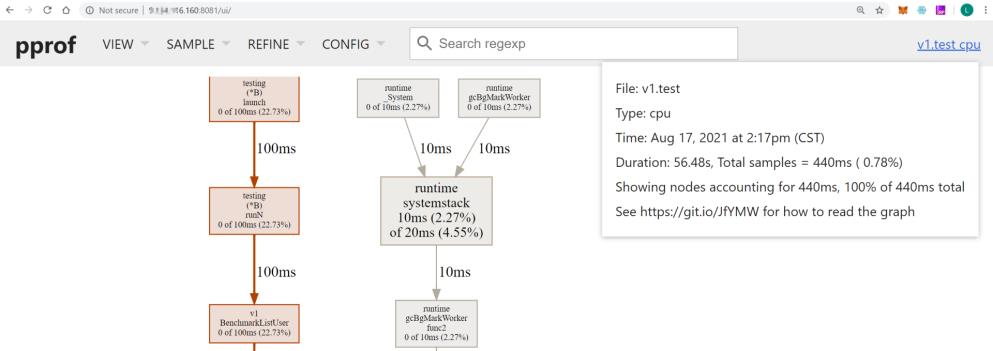
上面的 UI 页面提供了不同的采样数据视图:
- Top,类似于 linux top 的形式,从高到低排序。
- Graph,默认弹出来的就是该模式,也就是上一个图的那种带有调用关系的图。
- Flame Graph:pprof 火焰图。
- Peek:类似于 Top 也是从高到底的排序。
- Source:和交互命令式的那种一样,带有源码标注。
- Disassemble:显示所有的总量。
接下来,我们主要来分析火焰图。在 UI 界面选择 Flame Graph(VIEW -> Flame Graph),就会展示火焰图,如下图所示:
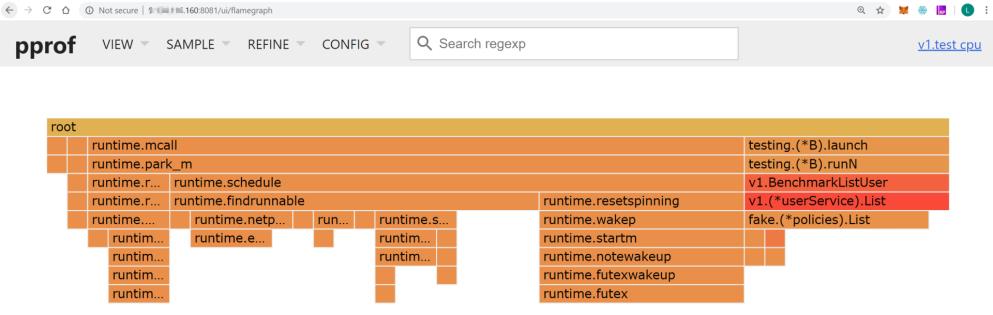
火焰图主要有下面这几个特征:
- 每一列代表一个调用栈,每一个格子代表一个函数。
- 纵轴展示了栈的深度,按照调用关系从上到下排列。最下面的格子代表采样时,正在占用 CPU 的函数。
- 调用栈在横向会按照字母排序,并且同样的调用栈会做合并,所以一个格子的宽度越大,说明这个函数越可能是瓶颈。
- 火焰图格子的颜色是随机的暖色调,方便区分各个调用信息。
查看火焰图时,格子越宽的函数,就越可能存在性能问题,这时候,我们就可以分析该函数的代码,找出问题所在。
3.2.3 方法三:用go tool pprof交互模式查看
我们可以执行go tool pprof命令,来查看 CPU 的性能数据文件:
$ go tool pprof v1.test cpu.profile
File: v1.test
Type: cpu
Time: Aug 17, 2021 at 2:17pm (CST)
Duration: 56.48s, Total samples = 440ms ( 0.78%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
go tool pprof输出了很多信息:
- File,二进制可执行文件名称。
- Type,采样文件的类型,例如 cpu、mem 等。
- Time,生成采样文件的时间。
- Duration,程序执行时间。上面的例子中,程序总执行时间为37.43s,采样时间为42.37s。采样程序在采样时,会自动分配采样任务给多个核心,所以总采样时间可能会大于总执行时间。
- (pprof),命令行提示,表示当前在go tool的pprof工具命令行中,go tool还包括cgo、doc、pprof、trace等多种命令。
执行go tool pprof命令后,会进入一个交互 shell。在这个交互 shell 中,我们可以执行多个命令,最常用的命令有三个,如下表所示:
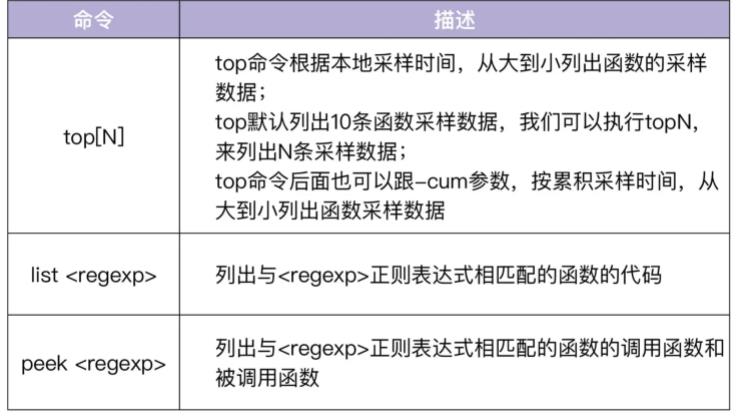
我们在交互界面中执行top命令,可以查看性能样本数据:
(pprof) top
Showing nodes accounting for 350ms, 79.55% of 440ms total
Showing top 10 nodes out of 47
flat flat% sum% cum cum%
110ms 25.00% 25.00% 110ms 25.00% runtime.futex
70ms 15.91% 40.91% 90ms 20.45% github.com/marmotedu/iam/internal/apiserver/store/fake.(*policies).List
40ms 9.09% 50.00% 40ms 9.09% runtime.epollwait
40ms 9.09% 59.09% 180ms 40.91% runtime.findrunnable
30ms 6.82% 65.91% 30ms 6.82% runtime.write1
20ms 4.55% 70.45% 30ms 6.82% runtime.notesleep
10ms 2.27% 72.73% 100ms 22.73% github.com/marmotedu/iam/internal/apiserver/service/v1.(*userService).List
10ms 2.27% 75.00% 10ms 2.27% runtime.checkTimers
10ms 2.27% 77.27% 10ms 2.27% runtime.doaddtimer
10ms 2.27% 79.55% 10ms 2.27% runtime.mallocgc
上面的输出中,每一行表示一个函数的信息。pprof 程序中最重要的命令就是 topN,这个命令用来显示 profile 文件中最靠前的 N 个样本(sample),top 命令会输出多行信息,每一行代表一个函数的采样数据,默认按flat%排序。输出中,各列含义如下:
- flat:采样点落在该函数中的总时间。
- flat%:采样点落在该函数中时间的百分比。
- sum%:前面所有行的 flat% 的累加值,也就是上一项的累积百分比。
- cum:采样点落在该函数中的,以及被它调用的函数中的总时间。
- cum%:采样点落在该函数中的,以及被它调用的函数中的总次数百分比。
- 函数名。
上面这些信息,可以告诉我们函数执行的时间和耗时排名,我们可以根据这些信息,来判断哪些函数可能有性能问题,或者哪些函数的性能可以进一步优化。
这里想提示下,如果执行的是go tool pprof mem.profile,那么上面的各字段意义是类似的,只不过这次不是时间而是内存分配大小(字节)。
执行top命令默认是按flat%排序的,在做性能分析时,我们需要先按照cum来排序,通过cum,我们可以直观地看到哪个函数总耗时最多,然后再参考该函数的本地采样时间和调用关系,来判断是该函数性能耗时多,还是它调用的函数耗时多。
执行top -cum输出如下:
(pprof) top20 -cum
Showing nodes accounting for 280ms, 63.64% of 440ms total
Showing top 20 nodes out of 47
flat flat% sum% cum cum%
0 0% 0% 320ms 72.73% runtime.mcall
0 0% 0% 320ms 72.73% runtime.park_m
0 0% 0% 280ms 63.64% runtime.schedule
40ms 9.09% 9.09% 180ms 40.91% runtime.findrunnable
110ms 25.00% 34.09% 110ms 25.00% runtime.futex
10ms 2.27% 36.36% 100ms 22.73% github.com/marmotedu/iam/internal/apiserver/service/v1.(*userService).List
0 0% 36.36% 100ms 22.73% github.com/marmotedu/iam/internal/apiserver/service/v1.BenchmarkListUser
0 0% 36.36% 100ms 22.73% runtime.futexwakeup
0 0% 36.36% 100ms 22.73% runtime.notewakeup
0 0% 36.36% 100ms 22.73% runtime.resetspinning
0 0% 36.36% 100ms 22.73% runtime.startm
0 0% 36.36% 100ms 22.73% runtime.wakep
0 0% 36.36% 100ms 22.73% testing.(*B).launch
0 0% 36.36% 100ms 22.73% testing.(*B).runN
70ms 15.91% 52.27% 90ms 20.45% github.com/marmotedu/iam/internal/apiserver/store/fake.(*policies).List
10ms 2.27% 54.55% 50ms 11.36% runtime.netpoll
40ms 9.09% 63.64% 40ms 9.09% runtime.epollwait
0 0% 63.64% 40ms 9.09% runtime.modtimer
0 0% 63.64% 40ms 9.09% runtime.resetForSleep
0 0% 63.64% 40ms 9.09% runtime.resettimer (inline)
从上面的输出可知,v1.BenchmarkListUser、testing.(*B).launch、testing.(*B).runN的本地采样时间占比分别为0%、0%、0%,但是三者的累积采样时间占比却比较高,分别为22.73%、22.73%、22.73%。
本地采样时间占比很小,但是累积采样时间占比很高,说明这 3 个函数耗时多是因为调用了其他函数,它们自身几乎没有耗时。
从采样图中,可以知道最终v1.BenchmarkListUser调用了v1.(*userService).List函数。v1.(*userService).List函数是我们编写的函数,该函数的本地采样时间占比为2.27%,但是累积采样时间占比却高达22.73%,说明v1.(*userService).List调用其他函数耗用了大量的 CPU 时间。
再观察采样图,可以看出v1.(*userService).List耗时久是因为调用了fake.(*policies).List函数。我们也可以通过list命令查看函数内部的耗时情况:
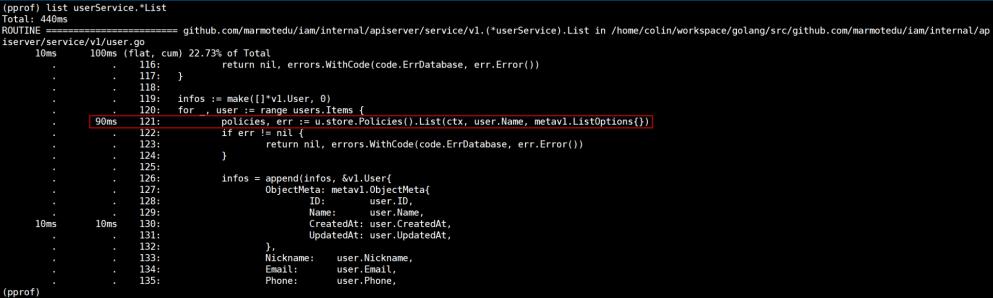
list userService.*List会列出userService结构体List方法内部代码的耗时情况,从上图也可以看到,u.store.Policies().List耗时最多。fake.(*policies).List的本地采样时间占比为15.91%,说明fake.(*policies).List函数本身可能存在瓶颈。走读fake.(*policies).List代码可知,该函数是查询数据库的函数,查询数据库会有延时。继续查看v1.(*userService).List代码,我们可以发现以下调用逻辑:
func (u *userService) ListWithBadPerformance(ctx context.Context, opts metav1.ListOptions) (*v1.UserList, error)
...
for _, user := range users.Items
policies, err := u.store.Policies().List(ctx, user.Name, metav1.ListOptions)
...
)
...
我们在for循环中,串行调用了fake.(*policies).List函数,每一次循环都会调用有延时的fake.(*policies).List函数。多次调用,v1.(*userService).List函数的耗时自然会累加起来。
现在问题找到了,那我们怎么优化呢?你可以利用 CPU 多核特性,开启多个 goroutine,这样我们的查询耗时就不是串行累加的,而是取决于最慢一次的fake.(*policies).List调用。优化后的v1.(*userService).List函数代码见internal/apiserver/service/v1/user.go。用同样的性能测试用例,测试优化后的函数,结果如下:
$ go test -benchtime=30s -benchmem -bench=".*" -cpuprofile cpu.profile -memprofile mem.profile
goos: linux
goarch: amd64
pkg: github.com/...
cpu: AMD EPYC Processor
BenchmarkListUser-8 8330 4271131 ns/op 26390 B/op 484 allocs/op
PASS
上面的代码中,ns/op 为4271131 ns/op,可以看到和第一次的测试结果204523677 ns/op相比,性能提升了97.91%。这里注意下,
为了方便你对照,我将优化前的v1.(*userService).List函数重命名为v1.(*userService).ListWithBadPerformance。
3.3 内存性能分析
Go 语言运行时,系统会对程序运行期间的所有堆内存分配进行记录。不管在采样的哪一时刻,也不管堆内存已用字节数是否有增长,只要有字节被分配且数量足够,分析器就会对它进行采样。
内存性能分析方法和 CPU 性能分析方法比较类似,这里就不再重复介绍了。你可以借助前面生成的内存性能数据文件mem.profile自行分析。
接下来,给你展示下内存优化前和优化后的效果。在v1.(*userService).List函数(位于internal/apiserver/service/v1/user.go文件中)中,有以下代码:
infos := make([]*v1.User, 0)
for _, user := range users.Items
info, _ := m.Load(user.ID)
infos = append(infos, info.(*v1.User))
此时,我们运行go test命令,测试下内存性能,作为优化后的性能数据,进行对比:
$ go test -benchmem -bench=".*" -cpuprofile cpu.profile -memprofile mem.profile
goos: linux
goarch: amd64
pkg: github.com/marmotedu/iam/internal/apiserver/service/v1
cpu: AMD EPYC Processor
BenchmarkListUser-8 278 4284660 ns/op 27101 B/op 491 allocs/op
PASS
ok github.com/marmotedu/iam/internal/apiserver/service/v1 1.779s
B/op和allocs/op分别为27101 B/op和491 allocs/op。
我们通过分析代码,发现可以将infos := make([]*v1.User, 0)优化为infos := make([]*v1.User, 0, len(users.Items)),来减少 Go 切片的内存重新分配的次数。优化后的代码为:
//infos := make([]*v1.User, 0)
infos := make([]*v1.User, 0, len(users.Items))
for _, user := range users.Items
info, _ := m.Load(user.ID)
infos = append(infos, info.(*v1.User))
再执行go test测试下性能:
$ go test -benchmem -bench=".*" -cpuprofile cpu.profile -memprofile mem.profile
goos: linux
goarch: amd64
pkg: github.com/marmotedu/iam/internal/apiserver/service/v1
cpu: AMD EPYC Processor
BenchmarkListUser-8 276 4318472 ns/op 26457 B/op 484 allocs/op
PASS
ok github.com/marmotedu/iam/internal/apiserver/service/v1 1.856s
优化后的B/op和allocs/op分别为26457 B/op和484 allocs/op。跟第一次的27101 B/op和491 allocs/op相比,内存分配次数更少,每次分配的内存也更少。
我们可以执行go tool pprof命令,来查看 CPU 的性能数据文件:
$ go tool pprof v1.test mem.profile
File: v1.test
Type: alloc_space
Time: Aug 17, 2021 at 8:33pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
该命令会进入一个交互界面,在交互界面中执行 top 命令,可以查看性能样本数据,例如:
(pprof) top
Showing nodes accounting for 10347.32kB, 95.28% of 10859.34kB total
Showing top 10 nodes out of 52
flat flat% sum% cum cum%
3072.56kB 28.29% 28.29% 4096.64kB 37.72% github.com/marmotedu/iam/internal/apiserver/service/v1.(*userService).List.func1
1762.94kB 16.23% 44.53% 1762.94kB 16.23% runtime/pprof.StartCPUProfile
1024.52kB 9.43% 53.96% 1024.52kB 9.43% go.uber.org/zap/buffer.NewPool.func1
1024.08kB 9.43% 63.39% 1024.08kB 9.43% time.Sleep
902.59kB 8.31% 71.70% 902.59kB 8.31% compress/flate.NewWriter
512.20kB 4.72% 76.42% 1536.72kB 14.15% github.com/marmotedu/iam/internal/apiserver/service/v1.(*userService).List
512.19kB 4.72% 81.14% 512.19kB 4.72% runtime.malg
512.12kB 4.72% 85.85% 512.12kB 4.72% regexp.makeOnePass
512.09kB 4.72% 90.57% 512.09kB 4.72% github.com/marmotedu/iam/internal/apiserver/store/fake.FakeUsers
512.04kB 4.72% 95.28% 512.04kB 4.72% runtime/pprof.allFrames
上面的内存性能数据,各字段的含义依次是:
- flat,采样点落在该函数中的总内存消耗。
- flat% ,采样点落在该函数中的百分比。
- sum% ,上一项的累积百分比。
- cum ,采样点落在该函数,以及被它调用的函数中的总内存消耗。
- cum%,采样点落在该函数,以及被它调用的函数中的总次数百分比。
- 函数名。
四、简例入门
我们将编写一个简单且有点问题的例子,用于基本的程序初步分析
4.1 编写 demo 文件
demo.go,文件内容:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
)
var datas []string
func Add(str string) string
data := []byte(str)
sData := string(data)
datas = append(datas, sData)
return sData
// localhost:6060
func main()
go func()
for
log.Println(Add("https://github.com/iswxw"))
()
http.ListenAndServe("0.0.0.0:6060", nil)
运行这个文件,你的 HTTP 服务会多出 /debug/pprof 的 endpoint 可用于观察应用程序的情况
4.2 分析方式
4.2.1 通过 Web 界面
查看当前总览:访问 http://127.0.0.1:6060/debug/pprof/
/debug/pprof/
profiles:
0 block
5 goroutine
3 heap
0 mutex
9 threadcreate
full goroutine stack dump
这个页面中有许多子页面,咱们继续深究下去,看看可以得到什么?
- cpu(CPU Profiling): $HOST/debug/pprof/profile,默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件
- block(Block Profiling):$HOST/debug/pprof/block,查看导致阻塞同步的堆栈跟踪
- goroutine:$HOST/debug/pprof/goroutine,查看当前所有运行的 goroutines 堆栈跟踪
- heap(Memory Profiling): $HOST/debug/pprof/heap,查看活动对象的内存分配情况
- mutex(Mutex Profiling):$HOST/debug/pprof/mutex,查看导致互斥锁的竞争持有者的堆栈跟踪
- threadcreate:$HOST/debug/pprof/threadcreate,查看创建新 OS 线程的堆栈跟踪
4.2.2 通过交互式终端使用
(1)CPU 性能分析
进入终端界面:go tool pprof http://localhost:6060/debug/pprof/profile?seconds=60
$ go tool pprof http://localhost:6060/debug/pprof/profile\\?seconds\\=60
Fetching profile over HTTP from http://localhost:6060/debug/pprof/profile?seconds=60
Saved profile in /Users/eddycjy/pprof/pprof.samples.cpu.007.pb.gz
Type: cpu
Duration: 1mins, Total samples = 26.55s (44.15%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
执行该命令后,需等待 60 秒(可调整 seconds 的值),pprof 会进行 CPU Profiling。结束后将默认进入 pprof 的交互式命令模式,可以对分析的结果进行查看或导出。具体可执行 pprof help 查看命令说明
(pprof) top10
Showing nodes accounting for 25.92s, 97.63% of 26.55s total
Dropped 85 nodes (cum <= 0.13s以上是关于Go 性能优化之pprof 实战的主要内容,如果未能解决你的问题,请参考以下文章