大数据用户画像实战之业务数据调研及ETL
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据用户画像实战之业务数据调研及ETL相关的知识,希望对你有一定的参考价值。
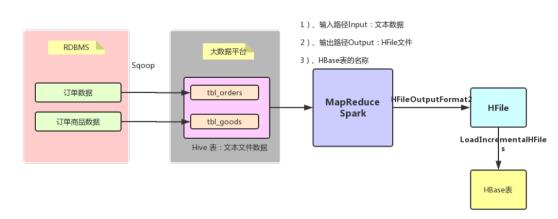
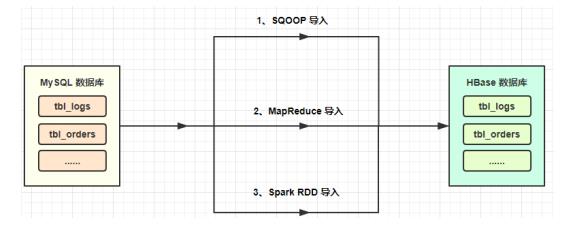
整个用户画像(UserProfile)项目中,数据、业务及技术流程图如下所示:

其中数据源存储在业务系统数据库:mysql 数据库中,采用SQOOP全量/增量将数据抽取到
HDFS(Hive表中),通过转换为HFile文件加载到HBase表。
1)、编写MapReduce程序
2)、编写Spark程序(推荐使用Spark编程)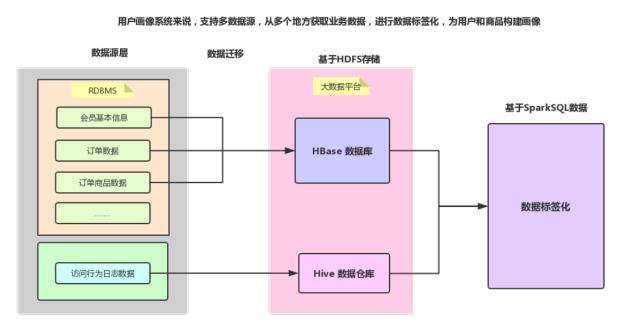
1)、为什么将【订单相关数据:订单数据和订单商品数据】存储到HBase表中????
特点:数据量比较大
存储HBase:存储海量数据、查询检索
2)、实际项目来说【访问行为日志】数据存储到Hive表中
数据仓库分层:
ODS层、DW层和APP层
3)、特殊:模拟的所有业务数据存储在RDBMs表中,为了简化整个项目开发,重点在于标签开发,将所
有数据迁移到HBase表中。1、电商数据(数据源)
所有的业务数据,都是编写程序模拟产生的,直接保存到MySQL数据库的表中。
1.1、MySQL 数据库
在数据库【 tags_dat 】中包含四张表:
1)、用户表:tbl_users
2)、订单数据表:tbl_orders
3)、订单商品表:tbl_goods
4)、行为日志表:tbl_logs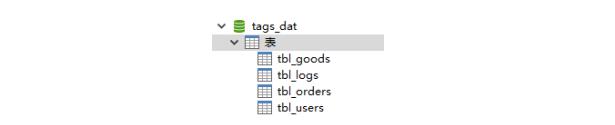
1.2、表的结构
电商系统中四张表的结构如下,数据存储在MySQL数据库中( 为了方便模拟业务数据,存
储MySQL表 )。
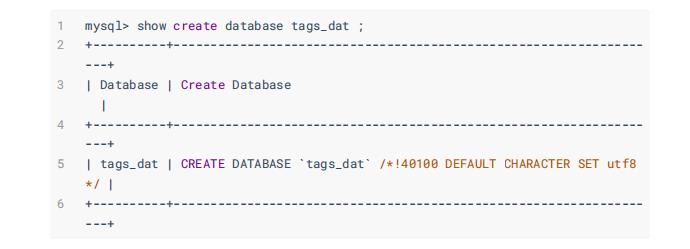
1.2.1、数据库: tags_dat
数据库 tags_dat ,构建语句如下:
1.2.2、会员信息表: tbl_users
电商网站中用户基本信息表,总共38个字段,除去主键ID外共37个字段信息。


此表中目前的数据量为:950条

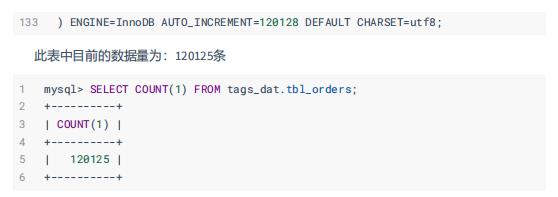
1.2.3、订单数据表: tbl_orders
电商网站中用户购买物品下单的订单数据,总共112个字段,记录每个订单详细信息。




1.2.4、订单商品信息表: tbl_goods
电商网站中订单商品goods基本信息表,总共97个字段,除去主键ID外96个字段。




此表中目前的数据量为:125463条
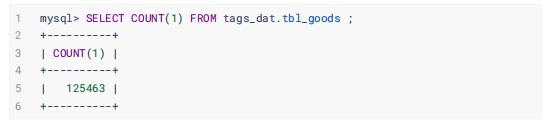
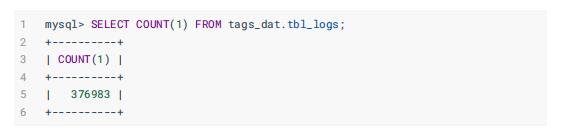
1.2.5、行为日志表:tbl_logs
电商网站中用户浏览网站访问行为日志数据(浏览数据),总共11个字段,此类数据属于最多

此表中目前的数据量为:376983条
1.3、Hive 数据仓库
将MySQL数据库中表的数据导入到Hive表中,以便加载到HBase表中。
启动HiveMetastore服务和HiveServer2服务,使用beeline命令行连接,相关命令如下:
1.3.1、创建表
创建Hive中数据库Database:

根据MySQL数据库表在Hive数据仓库中构建相应的表:
- 用户信息表: tbl_users
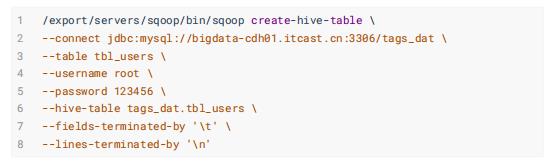
- 订单数据表: tbl_orders
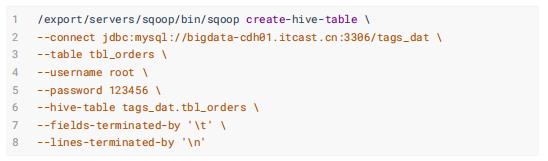
- 商品表: tbl_goods
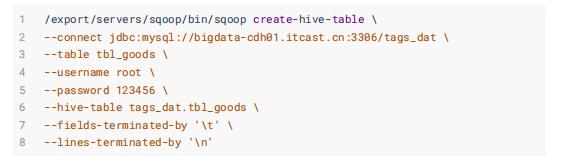
- 行为日志表: tbl_logs
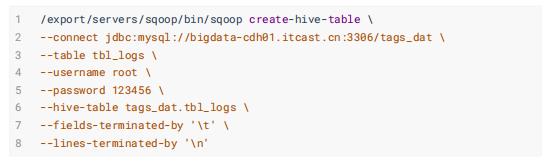
1.3.2、导入数据至Hive表
使用Sqoop将MySQL数据库表中的数据导入到Hive表中(本质就是存储在HDFS上),具体命
令如下:
用户信息表: tbl_users
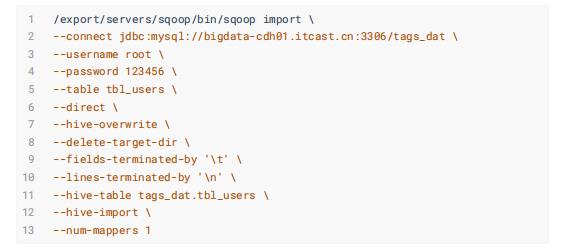
订单数据表: tbl_orders
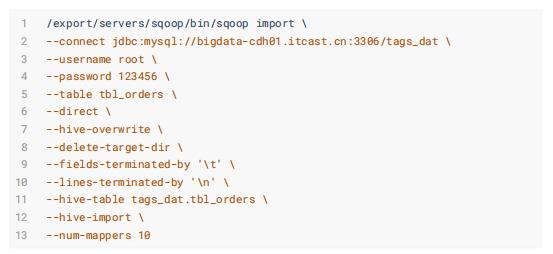
商品表: tbl_goods
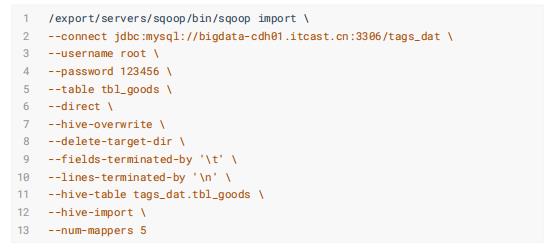
行为日志表: tbl_logs
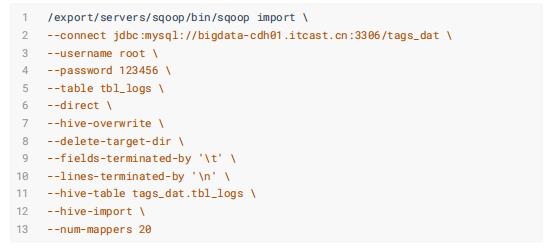
2、数据导入(Import)
将MySQL表中业务数据导入大数据平台中如HBase表,方案如下所示:
2.1、HBase 表设计
电商网站中各类数据(用户信息数据、用户访问日志数据及用户订单数据)存储到HBase表 中,便于检索和分析构建电商用户画像,有如下几张表:

用户基本信息: tbl_users

HBase表中有1个Region:

用户订单数据: tbl_orders ,共120125条


HBase 表中有两个Region:

订单商品数据: tbl_goods

行为日志数据: tbl_logs ,共376983条数据

HBase 表中有两个Region:

2.2、Sqoop直接导入
可以使用SQOOP将MySQL表的数据导入到HBase表中,指定 表的名称、列簇及RowKey ,范例如下所示:
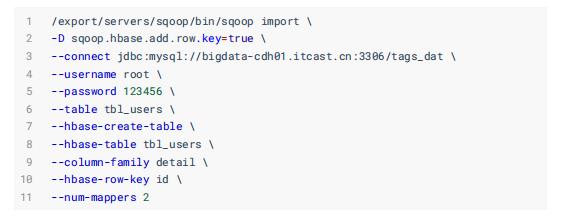
参数含义解释:

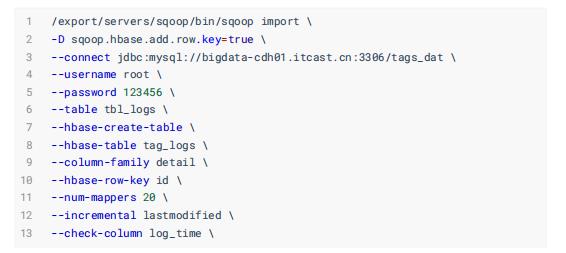
知识拓展:如何使用SQOOP进行增量导入数据至HBase表,范例命令如下:

2.3、HBase ImportTSV
ImportTSV功能描述:
将tsv(也可以是csv,每行数据中各个字段使用分隔符分割)格式文本数据,加载到HBase表中。
1)、采用Put方式加载导入
2)、采用BulkLoad方式批量加载导入使用如下命令,查看HBase官方自带工具类使用说明:

执行上述命令提示如下信息:

其中 importtsv 就是将文本文件(比如CSV、TSV等格式)数据导入HBase表工具类,使用说明如下:

分别演示采用直接Put方式和HFile文件方式将数据导入HBase表,命令如下:
其一、直接导入Put方式
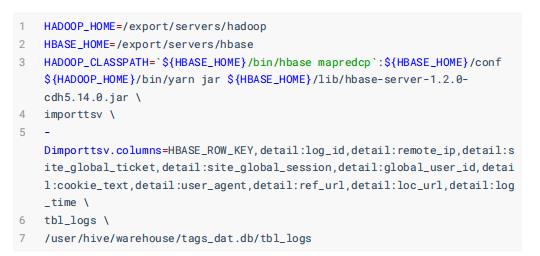
上述命令本质上运行一个MapReduce应用程序,将文本文件中每行数据转换封装到Put对象,然后插入到HBase表中。

其二、转换为HFile文件,再加载至表
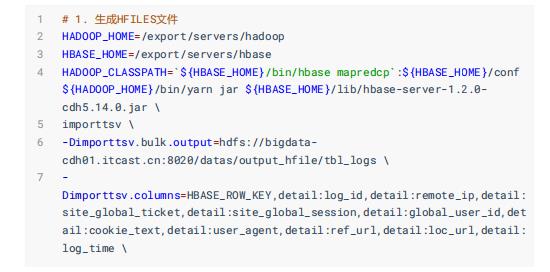
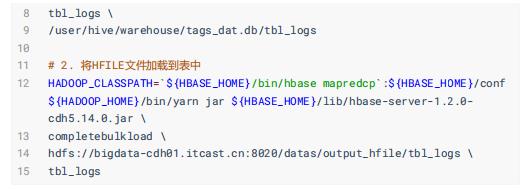
缺点:
1)、ROWKEY不能是组合主键
只能是某一个字段
2)、当表中列很多时,书写-Dimporttsv.columns值时很麻烦,容易出错2.4、HBase Bulkload
在大量数据需要写入HBase时,通常有 put方式和bulkLoad 两种方式。 1、put方式为单条插入,在put数据时会先将数据的更新操作信息和数据信息 写入WAL , 在写入到WAL后, 数据就会被放到MemStore中 ,当MemStore满后数据就会被 flush到磁盘 (即形成HFile文件) ,在这种写操作过程会涉及到flush、split、compaction等操作,容易造 成节点不稳定,数据导入慢,耗费资源等问题,在海量数据的导入过程极大的消耗了系统 性能,避免这些问题最好的方法就是使用BulkLoad的方式来加载数据到HBase中。
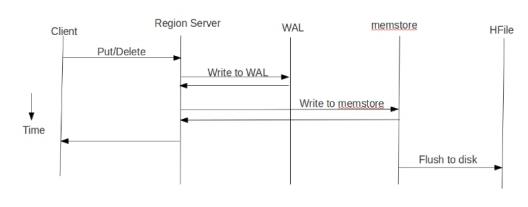
2、BulkLoader利用HBase数据按照HFile格式存储在HDFS的原理,使用MapReduce直接批量生成HFile格式文件后,RegionServers再将HFile文件移动到相应的Region目录下。
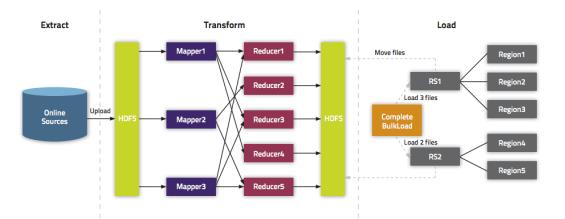
1)、Extract,异构数据源数据导入到 HDFS 之上。
2)、Transform,通过用户代码,可以是 MR 或者 Spark 任务将数据转化为 HFile。
3)、Load,HFile 通过 loadIncrementalHFiles 调用将 HFile 放置到 Region 对应的
HDFS 目录上,该过程可能涉及到文件切分。
1、不会触发WAL预写日志,当表还没有数据时进行数据导入不会产生Flush和Split。
2、减少接口调用的消耗,是一种快速写入的优化方式。
Spark读写HBase之使用Spark自带的API以及使用Bulk Load将大量数据导入HBase:
https://www.jianshu.com/p/b6c5a5ba30afBulkload过程主要包括三部分:
1、从数据源(通常是文本文件或其他的数据库)提取数据并上传到HDFS。
抽取数据到HDFS和Hbase并没有关系,所以大家可以选用自己擅长的方式进行。
2、利用MapReduce作业处理事先准备的数据 。
这一步需要一个MapReduce作业,并且大多数情况下还需要我们自己编写Map函数,而Reduce
函数不需要我们考虑,由HBase提供。
该作业需要使用rowkey(行键)作为输出Key;KeyValue、Put或者Delete作为输出Value。
MapReduce作业需要使用HFileOutputFormat2来生成HBase数据文件。
为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区
域中。为了达到这个目的,MapReduce作业会使用Hadoop的TotalOrderPartitioner类根据表的
key值将输出分割开来。
HFileOutputFormat2的方法configureIncrementalLoad()会自动的完成上面的工作。
3、告诉RegionServers数据的位置并导入数据。
这一步是最简单的,通常需要使用LoadIncrementalHFiles(更为人所熟知是
completebulkload工具),将文件在HDFS上的位置传递给它,它就会利用RegionServer将数据导
入到相应的区域。扩展资料:
HBase Bulkload 实践探讨:
https://mp.weixin.qq.com/s?
__biz=MzAxOTY5MDMxNA==&mid=2455760296&idx=1&sn=1b3a22e9408c8da56eceb1da6c82a
fd4&chksm=8c686b8dbb1fe29b93f58d68453d2912061090170d2aedf405bcc42085f613a500
a5961c705d&mpshare=1&scene=1&srcid=&sharer_sharetime=1576666741316&sharer_sh
areid=ff29a1f4969433ad06b0e97aed8610cb&key=1528f3467aaa6c49e329b76e6d972c07a
60af4486519558312dbee8ffd84970262b22b7bebb2a3f1e9973ea0be66f1da80ee5b243f87e
376e2f6716fb7b56283cd83605b3209f92b5fb1d9f8196ad5b8&ascene=1&uin=MjY2MDcwNTg
wNQ%3D%3D&devicetype=Windows+10&version=62070158&lang=zh_CN&exportkey=A2zIu%
2B6h%2BOWb63wHEGVfjNw%3D&pass_ticket=6qtjVsuzNFWXgqT9TeVtBEN4F7%2FE6CB5am02k
9rqTMvtTFDfGDildp92S%2BeO77jb2.4.1、编写MapReduce导入
将MySQL表的数据先导入到HDFS文件中(比如TSV格式),编写MapReduce将文本文件数据
转换为HFile文件,加载到HBase表中。
第一步、Hive中创建表

第二步、导入MySQL表数据到Hive表
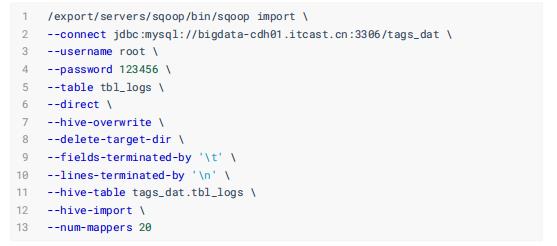
第三步、编写MapReduce导入数据至HBase表
其一、创建HBase 表,设置预分区
create 'tbl_logs', 'detail', SPLITS => ['49394']其二、工具类Constants,定义常量值

其三、MapReduce程序(本地运行) 使用Java语言,编写MapReduce程序,读取Hive表中数据文件,使用
HFileOutputFormat2输出格式,保存数据至HFile文件,再加载到HBase表中。





2.4.2、编写Spark 程序导入
企业中大规模数据存储于HBase背景:
项目中有需求,要频繁地、快速地向一个表中初始化数据。因此如何加载数据,如何提高速度是需要解
决的问题。
一般来说,作为数据存储系统会分为检索和存储两部分。检索是对外暴露数据查询接口。存储一是要实
现数据按固定规则存储到存储介质中(如磁盘、内存等),另一方面还需要向外暴露批量装载的工具。
如DB2的 db2load 工具,在关闭掉日志的前提下,写入速度能有显著提高。HBase数据库提供批量导入数据至表功能,相关知识点如下:
1、Hbase 中LoadIncrementalHFiles 支持向Hbase 写入HFile 文件
2、写入的HFile 文件要求是排序的(rowKey,列簇,列)
3、关键是绕过Hbase regionServer,直接写入Hbase文件
4、Spark RDD的repartitionAndSortWithinPartitions 方法可以高效地实现分区并排序
5、JAVA util.TreeMap 是红黑树的实现,能很好的实现排序的要求编写应用开发流程如下:
1、对待写入的数据按Key值构造util.TreeMap 树结构。目的是按Key值构造匹配Hbase 的排序结构
2、转换成RDD,使用repartitionAndSortWithinPartitions算子 对Key值分区并排序
3、调用RDD的saveAsNewAPIHadoopFile 算子,生成HFile文件
4、调用Hbase: LoadIncrementalHFiles 将HFile文件Load 到Hbase 表中1)、批量加载数据类:HBaseBulkLoader,代码如下:




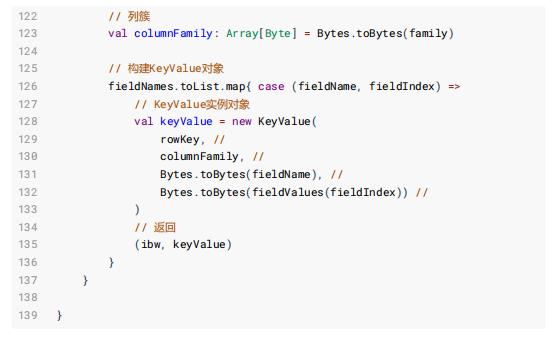
2)、将HBase数据库中不同表的字段信息封装object对象中,代码如下:








运行此应用程序时,需传递相关参数:

Spark Bulkload常见错误解析:

3、用户画像数据
基于电商数据,构建各个用户画像信息,开发项目时,设计的数据库和表(简易版本)如下:

3.1、标签模型表
用户画像平台将标签基本信息数据存储至MySQL数据库中,其中每个标签Tag的构建对应一个模型Model,模型数据同样存储至MySQL数据库中。
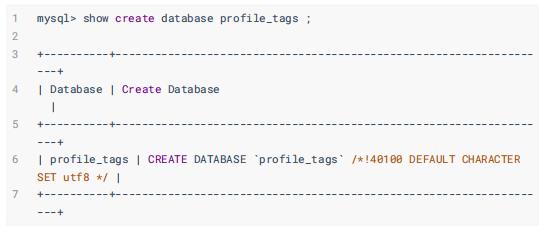
数据库: profile_tags
标签表: tbl_basic_tag

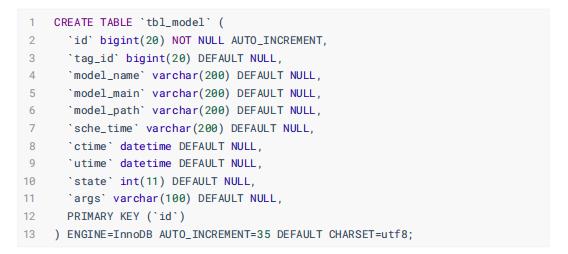
模型表: tbl_model
3.2、画像标签表
用户画像平台中用户的每个标签数据存储至HBase表中,此外在Solr中建立标签索引数据, 方便依据标签进行检索查询。
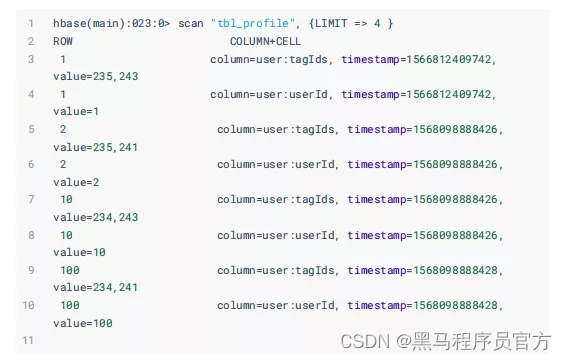
构建用户表: "tbl_profile" ,存储在HBase表中

样例数据:
以上是关于大数据用户画像实战之业务数据调研及ETL的主要内容,如果未能解决你的问题,请参考以下文章