量化交易因子数据处理-标准化和市值中性化
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了量化交易因子数据处理-标准化和市值中性化相关的知识,希望对你有一定的参考价值。
学习目标
- 目标
- 应用标准化对因子进行标准处理
- 实现标准化函数
去完极值之后,我们再去进行标准化,是否会更加准确些?
一、对pe_ratio标准化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
std.fit_transform(factor['pe_ratio2'])二、实现标准化
在调用fit_transform之后,数据的类型会变成array数组。不去修改原来的类型,我们可以简单的实现
def stand(factor):
"""自实现标准化
"""
mean = factor.mean()
std = factor.std()
return (factor - mean)/std调用
factor['pb_ratio'] = stand(factor['pb_ratio'])因子数据处理-市值中性化
学习目标
- 目标
- 说明中性化处理因子数据的原理
- 应用回归法对因子数据去中性化
- 应用市值中性化进行选股
一、为什么需要中性化处理
市值中性化是为了在因子选股回测的时候(不属于因子挖掘时候使用)防止选到的股票集中在固定的某些股票当中。
怎么理解?
1.1 市值影响
默认大部分因子当中都包含了市值的影响,所以当我们通过一些指标选择股票的时候,每个因子都会提供市值的因素,是的选择的股票比较集中,也就是选股的标准不太好。
比如:市净率会与市值有很高的相关性,这时如果我们使用未进行市值中性化的市净率,选股的结果会比较集中。
二、怎么去除市值影响
我们结合之前的算法或者知识点,那个方法可以去除一个因子对另一个因子的影响?

三、市场中性化处理-回归法
在每个时间截面上用所有股票的数据做横截面回归方程,x为市值因子,y为要去除市值影响的因子
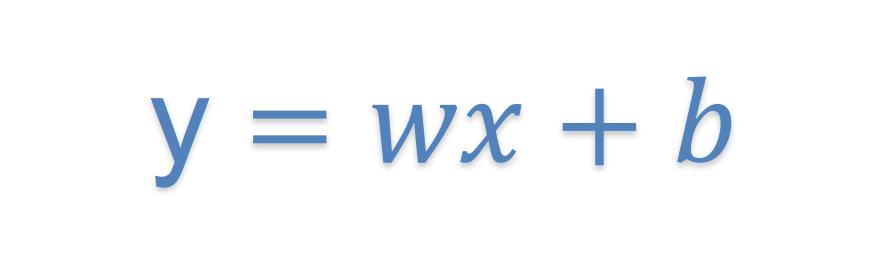
通过拟合找到x,y的关系公式,预测的时候会出现偏差?这个偏差是什么?
这个偏差即为保留下来的某因子除去市值影响的部分
四、回归法API
- from sklearn.linear_model import LinearRegression
- 把市值设置成特征,市值不进行任何处理
- 将其它因子设置成目标值
五、 案例:去除市净率 与市值之间的联系部分
5.1 分析
- 获取两个因子数据
- 对目标值因子-市净率进行去极值、标准化处理
- 建立市值与市净率回归方程
- 通过回归系数,预测新的因子结果y_predict
- 求出市净率与y_predict的偏差即为新的因子值
5.2 代码
# 1、获取这两个因子数据
q = query(fundamentals.eod_derivative_indicator.pb_ratio,
fundamentals.eod_derivative_indicator.market_cap)
# 获取的是某一天的横截面数据
factor = get_fundamentals(q, entry_date="2018-01-03")[:, 0, :]
# 先对pb_ratio进行去极值标准化处理
factor['pb_ratio'] = mad(factor['pb_ratio'])
factor['pb_ratio'] = stand(factor['pb_ratio'])
# 确定回归的数据
# x:市值
# y : 因子数据
x = factor['market_cap'].reshape(-1, 1)
y = factor['pb_ratio']
# 建立回归方程并预测
lr = LinearRegression()
lr.fit(x, y)
y_predict = lr.predict(x)
# 去除线性的关系,留下误差作为该因子的值
factor['pb_ratio'] = y - y_predict以上是关于量化交易因子数据处理-标准化和市值中性化的主要内容,如果未能解决你的问题,请参考以下文章