mysql索引数据结构详解---mysql详解
Posted 如月之恒-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql索引数据结构详解---mysql详解相关的知识,希望对你有一定的参考价值。
文章目录
磁盘存取原理
mysql的数据最终是在磁盘的,读取数据也是从磁盘读取。
那么就有必要知道磁盘的工作原理。
如图所示磁盘的结构图。
磁盘是逆时针旋转的,而磁头只能左右移动。磁头通过左右移动来划定磁道,从磁道中获取数据,数据存储在各个磁道的扇区中。
如果一个数据表中的数据,存储在不同的磁道中,那么就需要多次寻道,耗时就会长。

数据结构
非常直观,很好用。
数据结构动态演示网站
mysql为什么采取BTREE、HASH的数据结构?而没有采取二叉树、红黑树的数据结构。可以去这样网站试一下上述数据结构就清楚了。
因为二叉树、红黑树当数据量大时,都会导致数据深度太大。
Hash我们也很少用,因为hash对范围查询不友好。
BTREE的优点是的mysql的索引基本都是用BTREE。不过mysql的底层用的是B+TREE,比BTREE更高效。
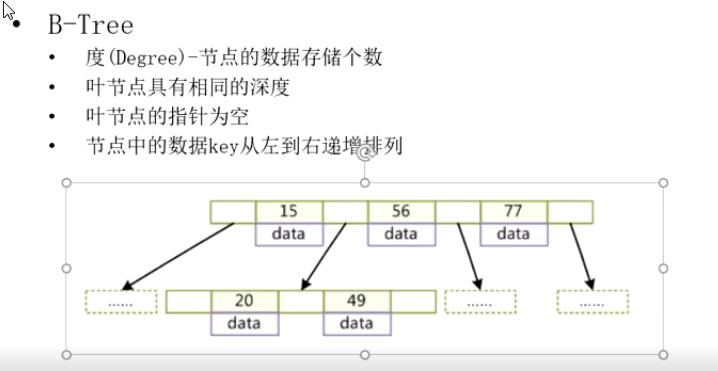
BTREE的度(Degree)-节点的数据存储个数。存储个数不能无限大,因为磁盘每次读取数据是有限的,比如磁盘每次读取20kb的数据,而节点存储了10M的数据,那么就需要读取10M/20kb次。一样会导致效率极低。
磁盘一页是4kb大小,而i你如果能保证每个B+TREE的节点是4kb大小。这样就提高了效率。
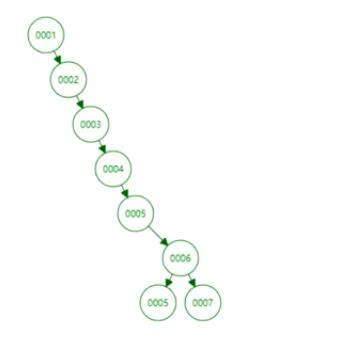
二叉树:
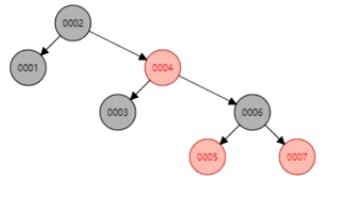
红黑树:
B-TREE:

我们提到的查询磁盘存取原理,我们找磁盘其实是找节点,节点数据会读取到内存,内存再读取,内存的速度可以忽略不计。所以BTREE我们查询0004的话,就是把包含0002、0004的节点读取到内存。
B+TREE
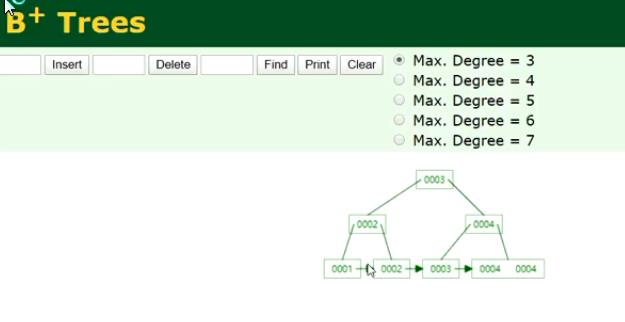
B-TREE数据存储方式:
mysql的B+TREE数据存储方式
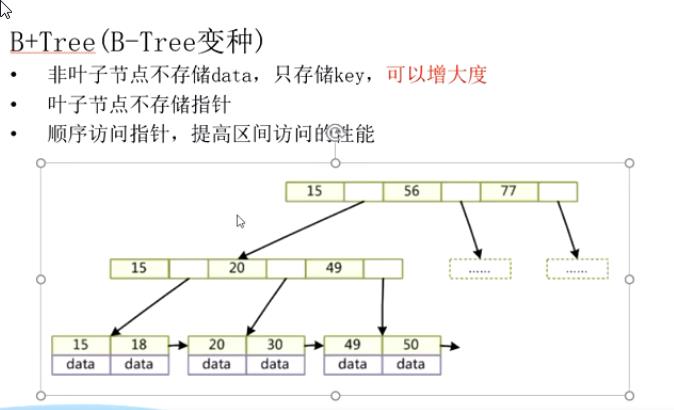
B+TREE的指针更方便mysql进行范围查询。
B+Tree索引的性能分析:
- 一 般 使 用 磁 盘 I/ O次 数 评 价 索 引 结 构 的 优 劣
- 预 读 : 磁 盘 一 般 会 顺 序 向 后 读 取 一 定 长度的数据(页的整数倍)放入内存
- 局 部 性 原 理 : 当 一 个 数 据 坫 用 到 时 , 其 附 近 的 数 据 也 通 常 会 马 上 被 使 用
- B+ Tree节 点 的 大小 设 为 等 于 一 个 页 , 每 次 新 建 节 点 直 接 中 访 一 个 页 的 空 间 , 这 样 就 保 证 一 个 节 点 物理上也 存 储 在 一 个 页 里 , 就 实 现了一 个 节 点 的 载入只需一 次 I/O
- B+ Tree的 度 d—般会超过100,因此h非常小(一般为3到5之间)
mysql存储引擎
MyISAM和InnoDB。这两个存储引擎都是表级别的。
MyISAM
MyISAM存储引擎存储方式:
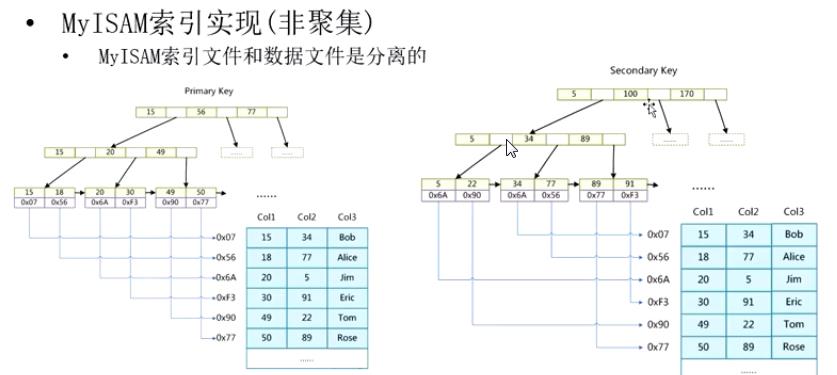
实际上MyISAM的B+TREE不存储data,而是存储data的指针。
MyISAM的主键索引和非主键索引一样。。
题外:如果用UUID作为表的主键,方便数据库做迁移。
InnoDB

实际上InnoDB的B+TREE存储了data
InnoDB的主键索引和非主键索引不一样。
联合索引的底层数据结构
字符串类型
如title、name两个字段均为字符串类型组成联合索引,那么联合索引的就是title+name这样加起来作为一个字符串索引。
多种数据类型组成的联合索引
如图所示:第一个为int类型,第二个为varchar,第三个为date。

那么联合索引会先用第一索引去比较,第一索引相同再用第二索引比较,第二索引相同再用第三索引去比较。
联合索引使用情况
注意: mysql的单个索引是联合索引的特殊情况
create table test(
a int ,
b int,
c int,
d int,
key index_abc(a,b,c)
)engine=InnoDB default charset=utf8;
查询语句
EXPLAIN
SELECT *
FROM `test` WHERE a='a';-- true
EXPLAIN
SELECT *
FROM `test` WHERE b='b'; -- false
EXPLAIN
SELECT *
FROM `test` WHERE c='c'; -- false
EXPLAIN
SELECT *
FROM `test` WHERE a='a' AND b='b'; -- true
EXPLAIN
SELECT *
FROM `test` WHERE b='b' AND a='a';-- true
EXPLAIN
SELECT *
FROM `test` WHERE a='a' AND c='c';-- true
EXPLAIN
SELECT *
FROM `test` WHERE c='c' AND a='a';-- true
EXPLAIN
SELECT *
FROM `test` WHERE c='c' AND b='b';-- false
EXPLAIN
SELECT *
FROM `test` WHERE b='b' AND c='c';-- false
EXPLAIN
SELECT *
FROM `test` WHERE a='a' AND b='b' AND c='c';-- true
EXPLAIN
SELECT *
FROM `test` WHERE a='a' AND c='c' AND b='b';-- true
EXPLAIN
SELECT *
FROM `test` WHERE b='b' AND c='c' AND a='a';-- true
EXPLAIN
SELECT *
FROM `test` WHERE b='b' AND a='a' AND c='c';-- true
EXPLAIN
SELECT *
FROM `test` WHERE c='c' AND b='b' AND a='a';-- true
EXPLAIN
SELECT *
FROM `test` WHERE c='c' AND a='a' AND b='b';-- true
EXPLAIN
select * from test where b<10 and c <10;-- false
EXPLAIN
select * from test where a<10 and c <10;-- ture
mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高,所以mysql查询优化器会最终以这种顺序进行查询执行。
所以当a字段不在最左时,mysql会自动调整到最左的位置然后再执行。
而根据联合索引数据结构图也可以看出,必须有a字段,联合索引才会生效。
另外的例子:

注
- 文章是个人知识点整理总结,如有错误和不足之处欢迎指正。
- 如有疑问、或希望与笔者探讨技术问题(包括但不限于本章内容),欢迎添加笔者微信(o815441)。请备注“探讨技术问题”。欢迎交流、一起进步。
以上是关于mysql索引数据结构详解---mysql详解的主要内容,如果未能解决你的问题,请参考以下文章