面试题Redis篇-常见面试题p1
Posted ΘLLΘ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试题Redis篇-常见面试题p1相关的知识,希望对你有一定的参考价值。
【面试题】Redis篇-常见面试题p1
备战实习,会定期的总结常考的面试题,大家一起加油! 🎯 🎯 🎯
往期文章:
参考文章:
- https://xppll.blog.csdn.net/article/details/121245615
- https://xppll.blog.csdn.net/article/details/121758265
- https://csp1999.blog.csdn.net/article/details/117849419
- https://javaguide.cn/database/redis/redis%E7%9F%A5%E8%AF%86%E7%82%B9&%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/
- https://pdai.tech/md/interview/x-interview.html#83-redis
注意:如果本文中有错误的地方,欢迎评论区指正!
文章目录
1.说一下什么是redis?
redis是一个高性能的key-value数据库,它是完全开源免费的,同时redis是一个NOSQL类型数据库,是为了解决高并发、高扩展,大数据存储等一系列的问题而产生的数据库解决方案,是一个非关系型的数据库。
与传统数据库不同的是 Redis 的数据是存在内存中的 ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
2.Redis 是单线程还是多线程的?
- redis 4.0 之前,redis 是完全单线程的。
- redis 4.0 时,redis 引入了多线程,但是额外的线程只是用于后台处理,例如:删除对象,核心流程还是完全单线程的。(核心流程指的是 redis 正常处理客户端请求的流程,通常包括:接收命令、解析命令、执行命令、返回结果等。)
- redis 6.0 中,多线程主要用于网络 I/O 阶段,也就是接收命令和写回结果阶段,而在执行命令阶段,还是由单线程串行执行。
👨💻面试官追问:Redis 为什么使用单线程、单线程也很快?
Redis使用单线程是因为:
- 在 redis 6.0 之前,redis 的核心操作是单线程的。因为 redis 是完全基于内存操作的,通常情况下CPU不会是redis的瓶颈,redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
- 既然CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了,因为如果使用多线程的话会更复杂,同时需要引入上下文切换、加锁等等,会带来额外的性能消耗。
单线程很快主要是:
- Redis 基于内存的操作
- Redis 使用了
I/O多路复用模型,select、epoll等,基于reactor模式开发了自己的网络事件处理器 - 单线程可以避免不必要的上下文切换和竞争条件,减少了这方面的性能消耗
3.Redis数据类型有哪些?
基本数据类型有五种:
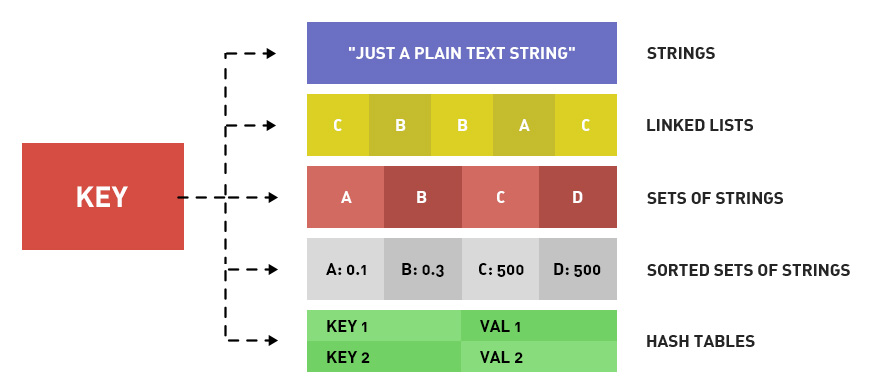
-
String
String是redis中最基本的数据类型,一个key对应一个value
-
List
Redis中的List其实就是链表(Redis用双端链表实现List)
-
Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象
-
Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
-
Sorted Set:
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
还有三种特殊的数据类型: 分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)
👨💻面试官追问:分别说说各个数据类型常用的使用场景?
-
String
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源
- session:常见方案spring session + redis实现session共享
-
List
- 阻塞队列:Redis的
lpush + brpop命令组合即可实现阻塞队列,生产者客户端是用lpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式的“抢"列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
- 阻塞队列:Redis的
-
Hash
- 缓存:哈希结构相对于字符串序列化缓存信息更加直观,而且更节省空间,并且在更新操作上更加便捷,所以常常用于缓存用户信息等。
-
Set
- 标签(tag):给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等:可以放到set中实现
-
zset
- 排行榜:有序集合经典使用场景。例如小说,视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
4.说一下Redis常见的功能有哪些?
- 数据缓存功能
- 分布式锁的功能
- 支持数据持久化
- 支持事务
- 支持消息队列
5.说一下Redis的常用的使用场景?
-
缓存
减轻MySQL的查询压力,提升系统性能
-
排行榜
利用Redis的
SortSet(有序集合)实现 -
计算器/限速器
- 利用Redis 中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等。
- 限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力
-
好友关系
利用集合的一些命令,比如求交集、并集、差集等。可以方便解决一些共同好友、共同爱好之类的功能
-
消息队列
除了Redis自身的
发布/订阅模式,我们也可以利用List来实现一个队列机制,比如︰到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List 来完成异步解耦 -
Session共享
Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆。采用Redis 保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息
6.说说Redis为什么这么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速
- 数据结构简单,对数据操作也简单
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 使用多路I/O复用模型,非阻塞IO
7.聊聊Redis为什么需要持久化?
Redis是个基于内存的数据库。那服务一旦宕机,内存中的数据将全部丢失。通常的解决方案是从后端数据库恢复这些数据,但后端数据库有性能瓶颈,如果是大数据量的恢复会有几个问题:
- 会对数据库带来巨大的压力
- 数据库的性能不如Redis。导致程序响应慢。
所以对Redis来说,实现数据的持久化,避免从后端数据库中恢复数据,是至关重要的。
8.说说Redis持久化的方式有哪些?
-
RDB
以快照的形式在指定的时间间隔内将内存中的数据集快照写入磁盘,可以指定时间归档数据,但不能做到实时持久化,RDB 持久化功能生成的 RDB 文件是经过压缩的二进制文件。
-
AOF
以日志的形式记录服务器所处理的每一个写、删除操作(查询操作不会记录),以文本的方式记录,并在服务器启动时,通过重新执行这些命令来还原数据集。
-
混合持久化
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。混合持久化只发生于 AOF 重写过程。使用了混合持久化,重写后的新 AOF 文件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。
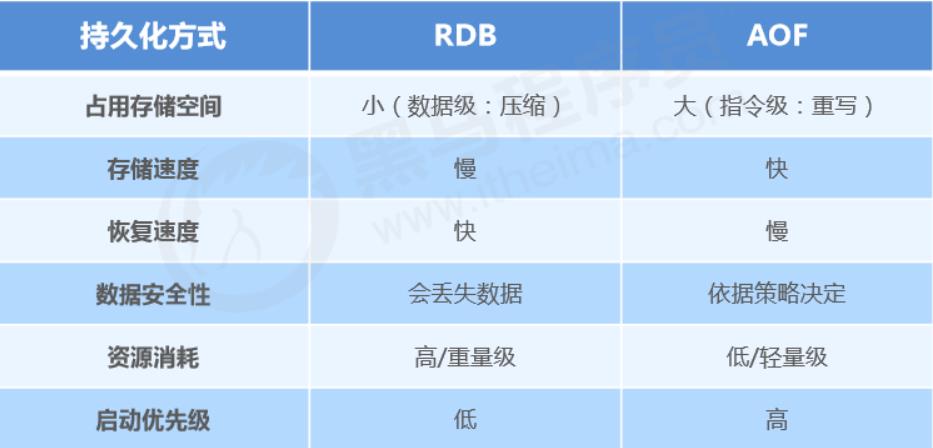
9.RDB和AOF两种持久化方式有什么优缺点?
- RDB优点
- RDB是一个紧凑压缩的二进制文件,存储效率较高
- RDB内部存储的是redis在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景
- RDB恢复数据的速度要比AOF快很多
- RDB缺点
- RDB方式实时性不够,无法做到秒级的持久化
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全
- Redis的众多版本中未进行RDB文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象
- AOF优点
- AOF 比 RDB可靠,支持秒级持久化,就算发生故障停机,也最多只会丢失一秒钟的数据
- 当 AOF文件太大时,Redis 会自动在后台进行重写。重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。当新文件重写完毕,Redis 会把新旧文件进行切换,然后开始把数据写到新文件上
- AOF缺点
- 对于相同的数据集,AOF 文件的大小一般会比 RDB 文件大
- RDB 存储的是压缩二进制格式记录数据命令,AOF 是通过文本日志形式记录数据命令,所以采用 AOF 数据恢复比 RDB 慢
两者对比图:
10.触发RDB持久化的方式有哪些?
触发RDB持久化的方式有2种,分别是手动触发和自动触发。
手动触发
手动触发分别对应save和bgsave命令
-
save命令
阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用
-
bgsave命令
Redis进程执行
fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短

自动触发
redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件- 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点
- 执行
debug reload命令重新加载redis时也会触发bgsave操作 - 默认情况下执行
shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作
11.AOF写数据有哪些策略?
一共有三种:
-
always
每次写入操作均同步到AOF文件中,数据零误差,性能较低,不建议使用
-
everysec
每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高 ,建议使用,也是默认配置。在系统突然宕机的情况下丢失1秒内的数据
-
no
由操作系统控制每次同步到AOF文件的周期,整体过程不可控
12.说说什么是AOF重写?
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制压缩文件体积。AOF文件重写是将Redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是减少冗余指令。
👨💻面试官追问:AOF重写有什么好处?
- 降低磁盘占用量,提高磁盘利用率
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高数据恢复效率
👨💻面试官继续问:AOF重写有哪些规则?
- 进程内已超时的数据不再写入文件
- 忽略无效指令。重写时使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令
- 如del key1、 hdel key2、srem key3、set key4 111、set key4 222等
- 对同一数据的多条写命令合并为一条命令
- 如lpush list1 a、lpush list1 b、 lpush list1 c 可以转化为:lpush list1 a b c
- 为防止数据量过大造成客户端缓冲区溢出,对list、set、hash、zset等类型,每条指令最多写入64个元素
13.什么是缓存穿透?
缓存穿透
是指缓存和数据库中都没有的数据。此时请求会直接打到数据库上,并且数据库查不到数据,也没办法写入缓存,所以下一次请求同样会打到数据库上。此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用!
举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
👨💻面试官追问:缓存穿透怎么解决?
- 接口层增加校验。如用户鉴权校验,id做基础校验,id<=0的直接拦截。
- 缓存无效key。从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
- 布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小。
14.什么是缓存击穿?
缓存击穿
是指某一个热点数据缓存中没有但数据库中有数据(一般是缓存时间到期)。这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
👨💻面试官追问:缓存击穿你会怎么解决?
- 设置热点数据永远不过期。
- 接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
- 设置互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。(可以使用 Redis 分布式锁)
15.什么是缓存雪崩?
缓存雪崩
是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
👨💻面试官追问:缓存雪崩有什么解决方法?
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 采用 Redis 集群。如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中,避免单机出现问题整个缓存服务都没办法使用。
- 设置热点数据永远不过期。

以上是关于面试题Redis篇-常见面试题p1的主要内容,如果未能解决你的问题,请参考以下文章