爬虫5年保更新专栏异步协程典型案例,一篇掌握~
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫5年保更新专栏异步协程典型案例,一篇掌握~相关的知识,希望对你有一定的参考价值。
最近收到 C 友反馈,说 《听说过 python 协程没?听说过 asyncio 库没?都在这一篇博客了》 这篇博客的目标图片站,已经不能使用了,橡皮擦查阅之后,发现是对方网站已经不运营了,所以更新一下案例。
感谢 C 友【彬】
如果你在订阅之后,发现其它站点出现类似情况,一定第一时间联系橡皮擦,每个爬虫都
质保 5 年
版权声明:本案例涉及所有内容仅供学习使用,请勿用于商业目的,如有侵权,请及时联系。
⚡⚡ 学习注意事项 ⚡⚡
- 文章会自动省略 http 和 https 协议,学习时请自行在地址中进行补充。
- 目标站点域名为
huanghelou.cc,在下文统一用橡皮擦代替,学习时请自行拼接。
文章目录
⛳️ asynico 复盘简介
原博客主要讲解的是异步 I/O 库 asynico,知识点可以继续通过原文学习,本篇博客对原文案例进行更新。
再补充一下 asynico 的简介
asynico 是一个 Python 库,它可以帮助用户使用 async/await 语法来编写非阻塞代码。async/await 语法是一种用于处理异步操作的新方法,它使得编写异步代码更加简单和直观。使用 asynico,用户可以在不改变现有代码结构的情况下将同步代码转换为异步代码,从而提高代码的效率和性能。
基本语法
async/await 语法是 Python 3.5 中引入的新特性。它用于在异步编程中处理异步操作。下面是一个基本的 async/await 示例:
async def do_something():
# Do some async operation here
result = await something()
return result
上面的示例中,do_something 是一个异步函数,它包含一个异步操作 something()。在这个例子中,something() 可能是一个异步 I/O 操作,例如读取文件或者发送 HTTP 请求。
在 do_something 函数中,我们使用 await 关键字来等待 something() 函数的执行结果。await 关键字会暂停当前函数的执行,等待 something() 函数的执行结果返回。
当 something() 函数返回结果后,await关键字会恢复 do_something 函数的执行,并将 something() 的执行结果赋值给 result 变量。最后,do_something 函数会返回 result 的值。
这就是 async/await 语法的基本用法。通过使用 async/await,我们可以编写更加简洁和优雅的异步代码,提高代码的可读性和可维护性。
了基本的使用方法,还有一些需要注意的点。
首先,如果要在 Python 程序中使用 async/await,需要确保运行环境支持 Python 3.5 或更高版本。async/await 语法在 Python 3.5 中才引入,如果运行环境版本低于 3.5,就无法使用 async/await。
其次,使用 async/await 时,需要注意代码的执行顺序。因为 async/await 会暂停函数的执行,等待异步操作的结果,所以在写 async/await 代码时需要注意函数的执行顺序。
例如,下面是一个异步函数的例子:
async def do_something():
result = await something()
print(result)
async def main():
await do_something()
main()
在上面的例子中,do_something 函数包含一个异步操作 something(),并在操作结束后打印结果。main 函数则调用 do_something 函数,并等待它的执行结果。
在这个例子中,由于 do_something 函数中包含一个异步操作,所以它会暂停执行,等待 something() 的执行结果。如果我们没有使用 await 关键字,那么 main 函数会继续执行,而不会等待 do_something 函数的结果。
所以,在使用 async/await 时,需要注意代码的执行顺序。
⛳️ 原案例分析
首先对原文代码进行整理分析,使用的模块如下:
threading:多线程模块;asyncio:异步 I/O 模块;time:时间模块;requests:请求包;lxml和bs4:解析模块。
主函数部分代码说明如下图所示。
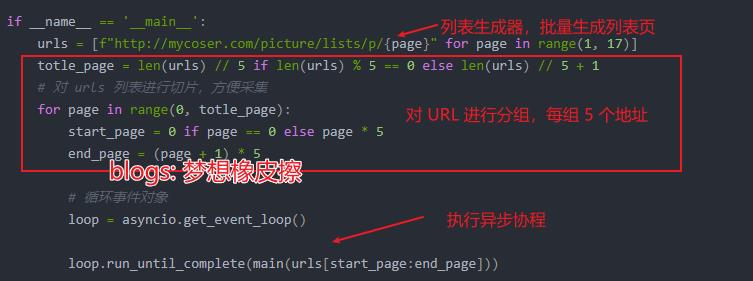
其中最主要的就是 main() 函数,其完成异步逻辑,原文代码及说明如下所示。
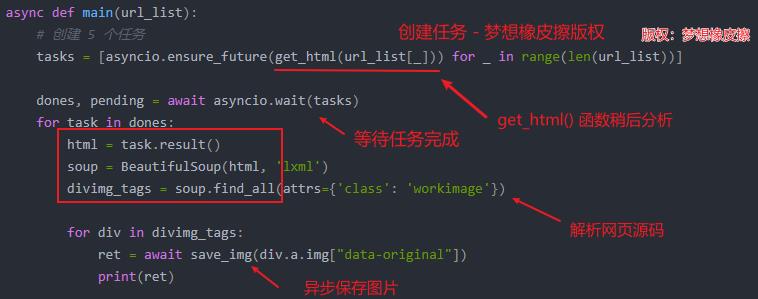
在 main() 函数内部实现了任务调度,其中调用了 2 个异步函数 get_html() 和 save_img(),这两个函数就是普通的采集函数,无学习难度,具体如下所示。
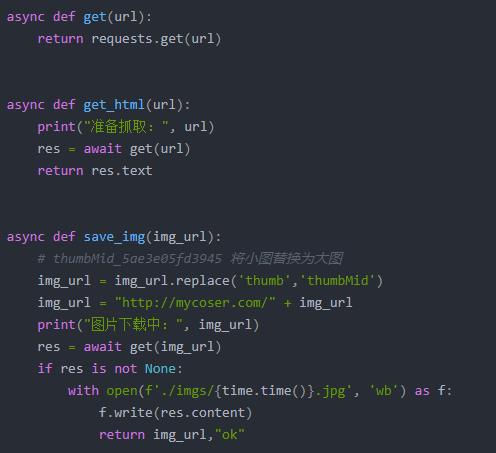
接下来,我们完成修复代码环节。
⛳️ 实战编码
基于黄鹤楼的代码修改如下。
import threading
import asyncio
import time
import requests
import lxml
from bs4 import BeautifulSoup
async def get(url):
return requests.get(url)
async def get_html(url):
print("准备抓取:", url)
res = await get(url)
return res.text
async def save_img(img_url):
print("图片下载中:", img_url)
res = await get(img_url)
if res is not None:
with open(f'./imgs/time.time().jpg', 'wb') as f:
f.write(res.content)
return img_url,"ok"
async def main(url_list):
# 创建 5 个任务
tasks = [asyncio.ensure_future(get_html(url_list[_])) for _ in range(len(url_list))]
dones, pending = await asyncio.wait(tasks)
for task in dones:
html = task.result()
soup = BeautifulSoup(html, 'lxml')
div_tag = soup.find(attrs='class': 'lbox')
imgs = div_tag.find_all('img')
for img in imgs:
ret = await save_img(img["data-original"])
print(ret)
if __name__ == '__main__':
# 修改为黄鹤楼,测试方便,仅使用10页
urls = [f"https://www.huanghelou.cc/category-44_page.html" for page in range(1, 10)]
totle_page = len(urls) // 5 if len(urls) % 5 == 0 else len(urls) // 5 + 1
# 对 urls 列表进行切片,方便采集
for page in range(0, totle_page):
start_page = 0 if page == 0 else page * 5
end_page = (page + 1) * 5
# 循环事件对象
loop = asyncio.get_event_loop()
loop.run_until_complete(main(urls[start_page:end_page]))
简单操作即可获得大量图片。
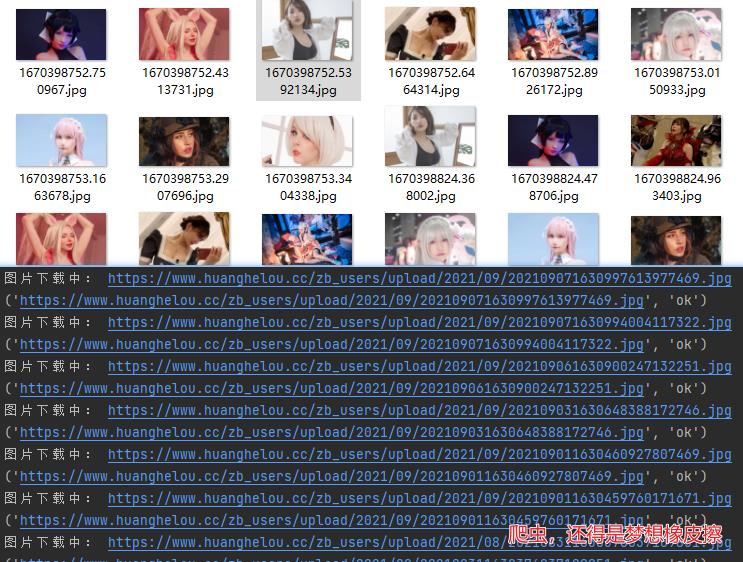
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 790 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于爬虫5年保更新专栏异步协程典型案例,一篇掌握~的主要内容,如果未能解决你的问题,请参考以下文章