数据库多条记录抽取共性,特性以自定义符号分隔形成一条记录
Posted Fire king
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库多条记录抽取共性,特性以自定义符号分隔形成一条记录相关的知识,希望对你有一定的参考价值。
具体解决方案
推荐持久层解决方案,更快,代码量更小。
业务层解决方案:
方案1:
实体类:
@Data
public class UserTab implements Serializable
private String userId;
private String sysId;
private String username;
private String sysName;
private static final long serialVersionUID = 1L;
//关键点:重写hashCode和equals
@Override
public boolean equals(Object o)
if(!(o instanceof UserTab))
return false;
if (o instanceof UserTab)
UserTab userTab = (userTab)o;
return userTab.userId.equals(userId);
return false;
@Override
public int hashCode()
return -1;
持久层:
<resultMap id="BaseResultMap3" type="*.model.UserTab">
<result column="USER_ID" jdbcType="VARCHAR" property="userId" />
<result column="USERNAME" jdbcType="VARCHAR" property="username" />
<result column="SYS_NAME" jdbcType="VARCHAR" property="sysName" />
</resultMap>
<select id="userTabList" parameterType="*.model.UserTab" resultMap="BaseResultMap3">
select
u.USER_ID, u.USERNAME, e.SYS_NAME
from USER u, USER_TAB t, TAB e
<trim prefix="WHERE" prefixOverrides="AND |OR ">
<if test="username != null and username != ''">
AND u.USERNAME like concat(concat('%',#username),'%')
</if>
<if test="userId != null and userId != ''">
AND u.USER_ID like concat(concat('%',#userId),'%')
</if>
AND u.USER_ID = t.USER_ID(+)
AND t.SYS_ID = e.SYS_ID(+)
</trim>
</select>
业务层(重要):
知识点必备:
HashMap的getOrDefault方法、hashMap对key相同的认定范畴、重写hashCode和equals方法降低对象相同的认定门槛以应和hashMap对key相同的认定范畴。
List<UserTab> userTabList = userTabMapper.userTabList(user);
Map<UserTab, String> userTabStringMap = new HashMap<>();
for (UserTab userTab: userTabStringMap)
userTabStringMap.put(userTab, userTabStringMap.getOrDefault(userTab, "") + userTab.getSysName() + ",");
List<JSONObject> jsonObjectList = new ArrayList<>();
//方案1:
for (Map.Entry<UserTab , String> userTabStringEntry : userTabStringMap.entrySet())
JSONObject jsonObject = new JSONObject();
UserTab userTab= userTabStringEntry.getKey();
User user1 = new User();
BeanUtils.copyProperties(user, user1);
jsonObject.put("userInfo" , user1);
String sysNames = userTabStringEntry.getValue().substring(0 , userTabStringEntry.getValue().lastIndexOf(","));
jsonObject.put("tabs" , sysNames);
jsonObjectList.add(jsonObject);
方案2:
利用java8的新特性-Stream之groupingBy:
同样的持久层,业务层代码如下:
List<UserTab> userTabList = userTabMapper.userTabList(user);
Map<String, List<UserTab>> map = userTabList.stream().collect(Collectors.groupingBy(UserTab::getUserId));
map.entrySet().forEach(new Consumer<Map.Entry<String, List<UserTab>>>()
@Override
public void accept(Map.Entry<String, List<UserTab>> stringListEntry)
JSONObject jsonObject = new JSONObject();
List<UserTab> list = stringListEntry.getValue();
UserTab userTab = list.get(0);
User user1 = new User();
BeanUtils.copyProperties(userTab , user1);
jsonObject.put("userInfo" , user1);
StringBuilder sysNameStringBuilder = new StringBuilder();
list.stream().forEach(new Consumer<UserTab>()
@Override
public void accept(UserTab userTab)
sysNameStringBuilder.append("," + userTab.getSysName());
);
String sysNameString = sysNameStringBuilder.substring(1);
jsonObject.put("tabs" , sysNameString);
jsonObjectList.add(jsonObject);
);
持久层解决方案:
方案1:
持久层(listagg、wm_concat、group_concat):
此处使用listagg函数
listagg函数,一句sql,打遍天下无敌手,
select
u.USER_ID, u.USERNAME, listagg(e.SYS_NAME , ',') within group (order by e.SYS_NAME ) SYS_NAME
from USER u, USER_TAB t, TAB e
WHERE u.USER_ID = t.USER_ID AND t.SYS_ID = e.SYS_ID
GROUP BY u.USER_ID, u.USERNAME
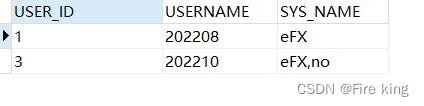
相比之前:
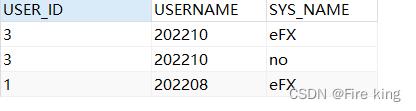
SELECT
u.USER_ID,
u.USERNAME,
e.SYS_NAME
FROM
USER u,
USER_TAB t,
TAB e
WHERE
u.USER_ID = t.USER_ID
AND t.SYS_ID = e.SYS_ID
帅不帅,SYS_NAME直接封装到实体类的sysName字段。
以上是关于数据库多条记录抽取共性,特性以自定义符号分隔形成一条记录的主要内容,如果未能解决你的问题,请参考以下文章