ChatGPT会取代搜索引擎吗
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT会取代搜索引擎吗相关的知识,希望对你有一定的参考价值。

作者 | 张俊林
本文经作者授权发布,原文地址:https://zhuanlan.zhihu.com/p/589533490
作为智能对话系统,ChatGPT最近两天爆火,都火出技术圈了,网上到处都在转ChatGPT相关的内容和测试例子,效果确实很震撼。我记得上一次能引起如此轰动的AI技术,NLP领域是GPT 3发布,那都是两年半前的事了,当时人工智能如日中天如火如荼的红火日子,今天看来恍如隔世;多模态领域则是以DaLL E2、Stable Diffusion为代表的Diffusion Model,这是最近大半年火起来的AIGC模型;而今天,AI的星火传递到了ChatGPT手上,它毫无疑问也属于AIGC范畴。所以说,在AI泡沫破裂后处于低谷期的今天,AIGC确实是给AI续命的良药,当然我们更期待估计很快会发布的GPT 4,愿OpenAI能继续撑起局面,给行业带来一丝暖意。
说回ChatGPT,例子就不举了,在网上漫山遍野都是,我们主要从技术角度来聊聊。那么,ChatGPT到底是采用了怎样的技术,才能做到如此超凡脱俗的效果?既然ChatGPT功能如此强大,那么它可以取代Google、百度等现有搜索引擎吗?如果能,那是为什么,如果不能,又是为什么?
本文试图从我个人理解的角度,来尝试回答上述问题,很多个人观点,偏颇难免,还请谨慎参考。我们首先来看看ChatGPT到底做了什么才获得如此好的效果。

ChatGPT的技术原理
整体技术路线上,ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据)来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
在“人工标注数据+强化学习”框架下,具体而言,ChatGPT的训练过程分为以下三个阶段:
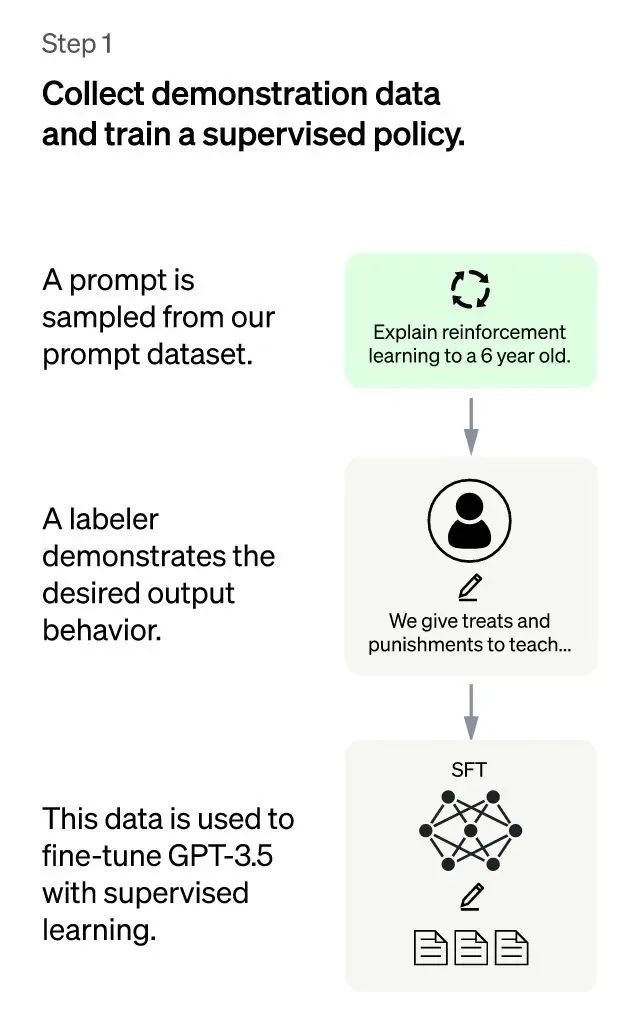
(ChatGPT:第一阶段)
第一阶段:冷启动阶段的监督策略模型。靠GPT 3.5本身,尽管它很强,但是它很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令中蕴含的意图,首先会从测试用户提交的prompt(就是指令或问题)中随机抽取一批,靠专业的标注人员,给出指定prompt的高质量答案,然后用这些人工标注好的<prompt,answer>数据来Fine-tune GPT 3.5模型。经过这个过程,我们可以认为GPT 3.5初步具备了理解人类prompt中所包含意图,并根据这个意图给出相对高质量回答的能力,但是很明显,仅仅这样做是不够的。
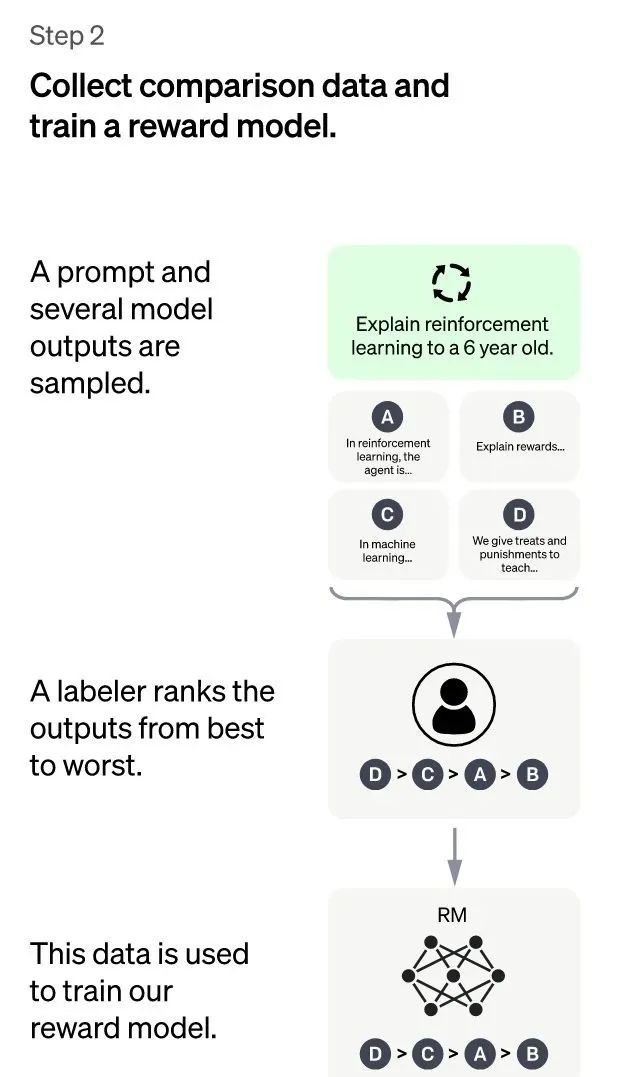
(ChatGPT:第二阶段)
第二阶段:训练回报模型(Reward Model,RM)。这个阶段的主要目的是通过人工标注训练数据,来训练回报模型。具体而言,随机抽样一批用户提交的prompt(大部分和第一阶段的相同),使用第一阶段Fine-tune好的冷启动模型,对于每个prompt,由冷启动模型生成K个不同的回答,于是模型产生出了<prompt,answer1>,<prompt,answer2>….<prompt,answerK>数据。之后,标注人员对K个结果按照很多标准(上面提到的相关性、富含信息性、有害信息等诸多标准)综合考虑进行排序,给出K个结果的排名顺序,这就是此阶段人工标注的数据。
接下来,我们准备利用这个排序结果数据来训练回报模型,采取的训练模式其实就是平常经常用到的pair-wise learning to rank。对于K个排序结果,两两组合,形成 (k2) 个训练数据对,ChatGPT采取pair-wise loss来训练Reward Model。RM模型接受一个输入<prompt,answer>,给出评价回答质量高低的回报分数Score。对于一对训练数据<answer1,answer2>,我们假设人工排序中answer1排在answer2前面,那么Loss函数则鼓励RM模型对<prompt,answer1>的打分要比<prompt,answer2>的打分要高。
归纳下:在这个阶段里,首先由冷启动后的监督策略模型为每个prompt产生K个结果,人工根据结果质量由高到低排序,以此作为训练数据,通过pair-wise learning to rank模式来训练回报模型。对于学好的RM模型来说,输入<prompt,answer>,输出结果的质量得分,得分越高说明产生的回答质量越高。
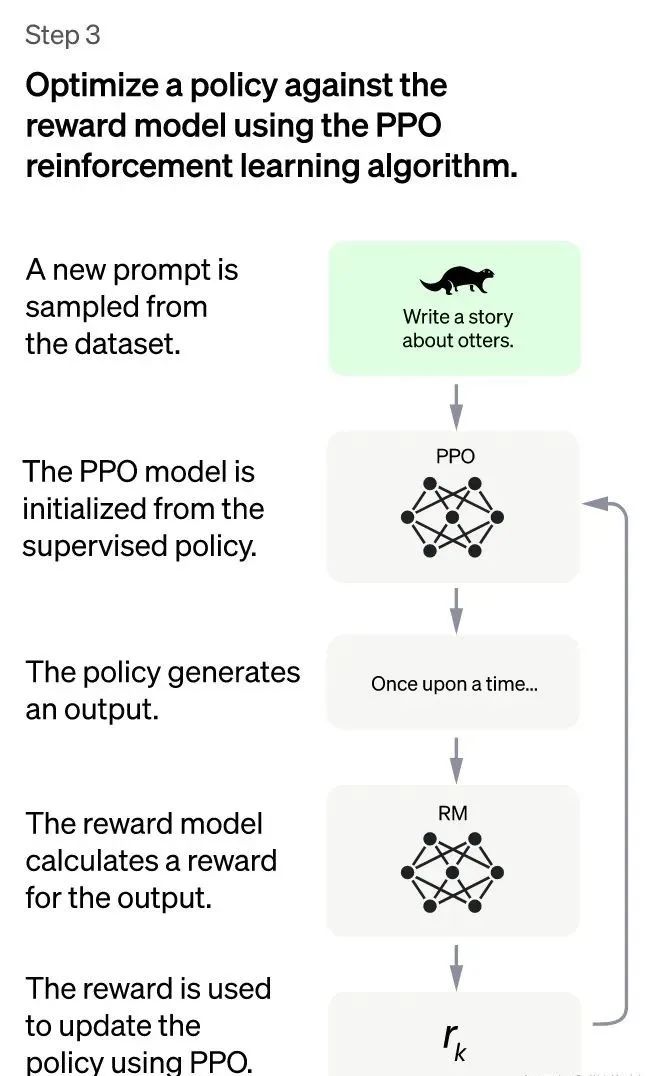
(ChatGPT:第三阶段)
第三阶段:采用强化学习来增强预训练模型的能力。本阶段无需人工标注数据,而是利用上一阶段学好的RM模型,靠RM打分结果来更新预训练模型参数。具体而言,首先,从用户提交的prompt里随机采样一批新的命令(指的是和第一第二阶段不同的新的prompt,这个其实是很重要的,对于提升LLM模型理解instruct指令的泛化能力很有帮助),且由冷启动模型来初始化PPO模型的参数。然后,对于随机抽取的prompt,使用PPO模型生成回答answer, 并用上一阶段训练好的RM模型给出answer质量评估的回报分数score,这个回报分数就是RM赋予给整个回答(由单词序列构成)的整体reward。有了单词序列的最终回报,就可以把每个单词看作一个时间步,把reward由后往前依次传递,由此产生的策略梯度可以更新PPO模型参数。这是标准的强化学习过程,目的是训练LLM产生高reward的答案,也即是产生符合RM标准的高质量回答。
如果我们不断重复第二和第三阶段,很明显,每一轮迭代都使得LLM模型能力越来越强。因为第二阶段通过人工标注数据来增强RM模型的能力,而第三阶段,经过增强的RM模型对新prompt产生的回答打分会更准,并利用强化学习来鼓励LLM模型学习新的高质量内容,这起到了类似利用伪标签扩充高质量训练数据的作用,于是LLM模型进一步得到增强。显然,第二阶段和第三阶段有相互促进的作用,这是为何不断迭代会有持续增强效果的原因。
尽管如此,我觉得第三阶段采用强化学习策略,未必是ChatGPT模型效果特别好的主要原因。假设第三阶段不采用强化学习,换成如下方法:类似第二阶段的做法,对于一个新的prompt,冷启动模型可以产生k个回答,由RM模型分别打分,我们选择得分最高的回答,构成新的训练数据<prompt,answer>,去fine-tune LLM模型。假设换成这种模式,我相信起到的作用可能跟强化学习比,虽然没那么精巧,但是效果也未必一定就差很多。第三阶段无论采取哪种技术模式,本质上很可能都是利用第二阶段学会的RM,起到了扩充LLM模型高质量训练数据的作用。
以上是ChatGPT的训练流程,主要参考自instructGPT的论文,ChatGPT是改进的instructGPT,改进点主要在收集标注数据方法上有些区别,在其它方面,包括在模型结构和训练流程等方面基本遵循instructGPT。可以预见的是,这种Reinforcement Learning from Human Feedback技术会快速蔓延到其它内容生成方向,比如一个很容易想到的,类似“A machine translation model based on Reinforcement Learning from Human Feedback”这种,其它还有很多。但是,我个人认为,在NLP的某个具体的内容生成领域再采用这个技术意义应该已经不大了,因为ChatGPT本身能处理的任务类型非常多样化,基本涵盖了NLP生成的很多子领域,所以某个NLP子领域如果再单独采用这个技术其实已经不具备太大价值,因为它的可行性可以认为已经被ChatGPT验证了。如果把这个技术应用在比如图片、音频、视频等其它模态的生成领域,可能是更值得探索的方向,也许不久后我们就会看到类似“A XXX diffusion model based on Reinforcement Learning from Human Feedback”,诸如此类,这类工作应该还是很有意义的。
另外一个值得关注的采取类似技术的工作是DeepMind的sparrow,这个工作发表时间稍晚于instructGPT,如果你仔细分析的话,大的技术思路和框架与instructGPT的三阶段基本类似,不过明显sparrow在人工标注方面的质量和工作量是不如instructGPT的。反过来,我觉得sparrow里把回报模型分为两个不同RM的思路,是优于instructGPT的,至于原因在下面小节里会讲。

ChatGPT能否取代Google、百度等传统搜索引擎
既然看上去ChatGPT几乎无所不能地回答各种类型的prompt,那么一个很自然的问题就是:ChatGPT或者未来即将面世的GPT4,能否取代Google、百度这些传统搜索引擎呢?我个人觉得目前应该还不行,但是如果从技术角度稍微改造一下,理论上是可以取代传统搜索引擎的。

为什么说目前形态的ChatGPT还不能取代搜索引擎呢?主要有三点原因:首先,对于不少知识类型的问题,ChatGPT会给出看上去很有道理,但是事实上是错误答案的内容(参考上图的例子(from @Gordon Lee),ChatGPT的回答看着胸有成竹,像我这么没文化的基本看了就信了它,回头查了下这首词里竟然没这两句),考虑到对于很多问题它又能回答得很好,这将会给用户造成困扰:如果我对我提的问题确实不知道正确答案,那我是该相信ChatGPT的结果还是不该相信呢?此时你是无法作出判断的。这个问题可能是比较要命的。其次,ChatGPT目前这种基于GPT大模型基础上进一步增加标注数据训练的模式,对于LLM模型吸纳新知识是非常不友好的。新知识总是在不断出现,而出现一些新知识就去重新预训练GPT模型是不现实的,无论是训练时间成本还是金钱成本,都不可接受。如果对于新知识采取Fine-tune的模式,看上去可行且成本相对较低,但是很容易产生新数据的引入导致对原有知识的灾难遗忘问题,尤其是短周期的频繁fine-tune,会使这个问题更为严重。所以如何近乎实时地将新知识融入LLM是个非常有挑战性的问题。其三,ChatGPT或GPT4的训练成本以及在线推理成本太高,导致如果面向真实搜索引擎的以亿记的用户请求,假设继续采取免费策略,OpenAI无法承受,但是如果采取收费策略,又会极大减少用户基数,是否收费是个两难决策,当然如果训练成本能够大幅下降,则两难自解。以上这三个原因,导致目前ChatGPT应该还无法取代传统搜索引擎。
那么这几个问题,是否可以解决呢?其实,如果我们以ChatGPT的技术路线为主体框架,再吸纳其它对话系统采用的一些现成的技术手段,来对ChatGPT进行改造,从技术角度来看,除了成本问题外的前两个技术问题,目前看是可以得到很好地解决。我们只需要在ChatGPT的基础上,引入sparrow系统以下能力:基于retrieval结果的生成结果证据展示,以及引入LaMDA系统的对于新知识采取retrieval模式,那么前面提到的新知识的及时引入,以及生成内容可信性验证,基本就不是什么大问题。
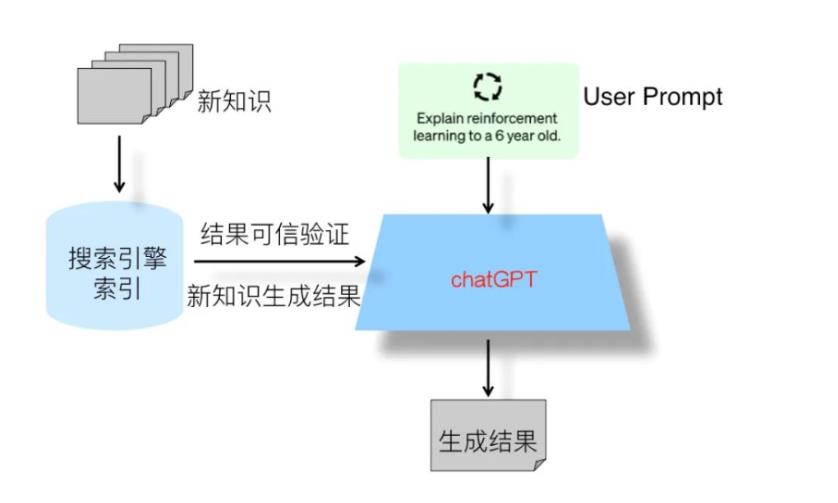
基于以上考虑,在上图中展示出了我心目中下一代搜索引擎的整体结构:它其实是目前的传统搜索引擎+ChatGPT的双引擎结构,ChatGPT模型是主引擎,传统搜索引擎是辅引擎。传统搜索引擎的主要辅助功能有两个:一个是对于ChatGPT产生的知识类问题的回答,进行结果可信性验证与展示,就是说在ChatGPT给出答案的同时,从搜索引擎里找到相关内容片段及url链接,同时把这些内容展示给用户,使得用户可以从额外提供的内容里验证答案是否真实可信,这样就可以解决ChatGPT产生的回答可信与否的问题,避免用户对于产生结果无所适从的局面。当然,只有知识类问题才有必要寻找可信信息进行验证,很多其他自由生成类型的问题,比如让ChatGPT写一个满足某个主题的小作文这种完全自由发挥的内容,则无此必要。所以这里还有一个什么情况下会调用传统搜索引擎的问题,具体技术细节完全可仿照sparrow的做法,里面有详细的技术方案。传统搜索引擎的第二个辅助功能是及时补充新知识。既然我们不可能随时把新知识快速引入LLM,那么可以把它存到搜索引擎的索引里,ChatGPT如果发现具备时效性的问题,它自己又回答不了,则可以转向搜索引擎抽取对应的答案,或者根据返回相关片段再加上用户输入问题通过ChatGPT产生答案。关于这方面的具体技术手段,可以参考LaMDA,其中有关于新知识处理的具体方法。
除了上面的几种技术手段,我觉得相对ChatGPT只有一个综合的Reward Model,sparrow里把答案helpful相关的标准(比如是否富含信息量、是否合乎逻辑等)采用一个RM,其它类型toxic/harmful相关标准(比如是否有bias、是否有害信息等)另外单独采用一个RM,各司其职,这种模式要更清晰合理一些。因为单一类型的标准,更便于标注人员进行判断,而如果一个Reward Model融合多种判断标准,相互打架在所难免,判断起来就很复杂效率也低,所以感觉可以引入到ChatGPT里来,得到进一步的模型改进。
通过吸取各种现有技术所长,我相信大致可以解决ChatGPT目前所面临的问题,技术都是现成的,从产生内容效果质量上取代现有搜索引擎问题不大。当然,至于模型训练成本和推理成本问题,可能短时期内无法获得快速大幅降低,这可能是决定LLM是否能够取代现有搜索引擎的关键技术瓶颈。从形式上来看,未来的搜索引擎大概率是以用户智能助手APP的形式存在的,但是,从短期可行性上来说,在走到最终形态之前,过渡阶段大概率两个引擎的作用是反过来的,就是传统搜索引擎是主引擎,ChatGPT是辅引擎,形式上还是目前搜索引擎的形态,只是部分搜索内容Top 1的搜索结果是由ChatGPT产生的,大多数用户请求,可能在用户看到Top 1结果就能满足需求,对于少数满足不了的需求,用户可以采用目前搜索引擎翻页搜寻的模式。我猜搜索引擎未来大概率会以这种过渡阶段以传统搜索引擎为主,ChatGPT这种instruct-based生成模型为辅,慢慢切换到以ChatGPT生成内容为主,而这个切换节点,很可能取决于大模型训练成本的大幅下降的时间,以此作为转换节点。

以上是关于ChatGPT会取代搜索引擎吗的主要内容,如果未能解决你的问题,请参考以下文章