全排列的实现方法--递归&字典序
Posted LaoJiu_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全排列的实现方法--递归&字典序相关的知识,希望对你有一定的参考价值。
一:背景
全排列在很多笔试都有应用,是一个很常见的算法,关于这类的题目变化很多。这种算法的得到基于以下的分析思路。 给定一个具有n个元素的集合(n>=1),要求输出这个集合中元素的所有可能的排列。
例如:给定1,2,3,全排列为3!个,即:
1,2,3,1,3,2
2,1,3,2,3,1
3,1,2,3,2,1
下来分别说下递归法,字典序算法来实现全排列。
二:实现算法
1.递归法
递归的话就很简单了,以1,2,3为例,它的排列是:
以1开头,后面接着2,3的全排列,
以2开头,后面接着1,3的全排列,
以3开头,后面接着1,2的全排列。
代码如下:
#include<iostream>
#include<algorithm>
using namespace std;
int arry[3] = 1,2,3 ;
void Recursion(int s, int t)
if (s == t)
for_each(arry, arry + 3, [](int i) printf("%d", i); ), printf("\\n");
else
for (int i = s; i <= t; i++)
swap(arry[i], arry[s]);
Recursion(s + 1, t);
swap(arry[i], arry[s]);
int main()
Recursion(0, 2);
return 0;
2.字典序算法
首先看什么叫字典序,顾名思义就是按照字典的顺序(a-z, 1-9)。以字典序为基础,我们可以得出任意两个数字串的大小。比如 "1" < "12"<"13"。 就是按每个数字位逐个比较的结果。对于一个数字串,“123456789”, 可以知道最小的串是 从小到大的有序串“123456789”,而最大的串是从大到小的有序串“*987654321”。这样对于“123456789”的所有排列,将他们排序,即可以得到按照字典序排序的所有排列的有序集合。
如此,当我们知道当前的排列时,要获取下一个排列时,就可以范围有序集合中的下一个数(恰好比他大的)。比如,当前的排列时“123456879”, 那么恰好比他大的下一个排列就是“123456897”。 当当前的排列时最大的时候,说明所有的排列都找完了。
于是可以有下面计算下一个排列的算法:
设P是1~n的一个全排列:p=p1p2......pn=p1p2......pj-1pjpj+1......pk-1pkpk+1......pn
1)从排列的右端开始,找出第一个比右边数字小的数字的序号j(j从左端开始计算),即 j=maxi|pi<pi+1
2)在pj的右边的数字中,找出所有比pj大的数中最小的数字pk,即 k=maxi|pi>pj(右边的数从右至左是递增的,因此k是所有大于pj的数字中序号最大者)
3)对换pi,pk
4)再将pj+1......pk-1pkpk+1......pn倒转得到排列p'=p1p2.....pj-1pjpn.....pk+1pkpk-1.....pj+1,这就是排列p的下一个排列。
证明:
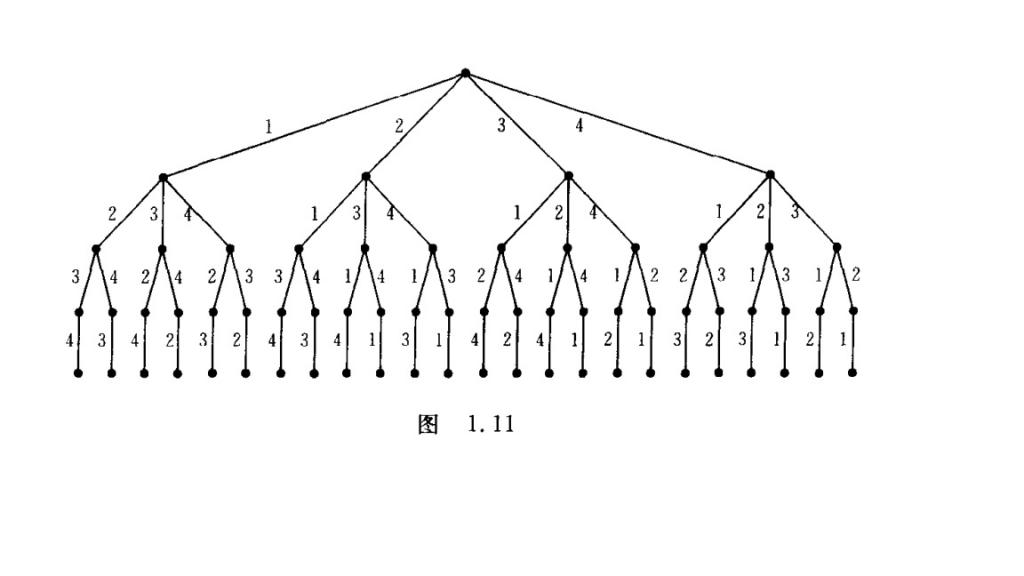
要证明这个算法的正确性,我们只要证明生成的下一个排序是恰好比当前排列大的一个序列即可。图1.11是从卢开澄老师的《组合数学》中截取的一个有1234生成所有排序的字典序树。从左到右的每一个根到叶子几点的路径就是一个排列。下面我们将以这个图为基础,来证明上面算法的正确性。
算法步骤1,得到的子串 s = pj+1,.....,pn, 是按照从大到小进行排列的。即有 pj+1 > pj+2 > ... > pn, 因为 j=maxi|pi<pi+1。
算法步骤2,得到了最小的比pj大的pk,从n往j数,第一个比j大的数字。将pk和pj替换,保证了替换后的数字比当前的数字要大。于是得到的序列为p1p2...pj-1pkpj+1...pk-1pjpk-1...pn.注意这里已经将pk替换成了pk。这时候我们注意到比p1..pj-1pk.....,恰好比p1....pj.....pn大的数字集合。我们在这个集合中挑选出最小的一个即时所要求的下一个排列。
算法步骤3,即是将pk后面的数字逆转一下(从从大到小,变成了从小到大。)
由此经过上面3个步骤得到的下个排列时恰好比当前排列大的排列。
同时我们注意到,当所有排列都找完时,此时数字串从大到小排列。步骤1得到的j < 0,算法结束。
代码如下:
#include<iostream>
#include<algorithm>
using namespace std;
int arry[3] = 1,2,3 ;//len==3;
void Permutation()
int len = 3;
int j, k;
while (true)
printf("%d%d%d\\n", arry[0], arry[1], arry[2]);
for (j = len - 2; j >= 0 && arry[j] > arry[j + 1]; j--);//注意此处 j >= 0 判断条件在前
if (j < 0) return;//结束
for (k = len - 1; k > j&&arry[k] < arry[j]; k--);
swap(arry[k], arry[j]);
for (int l = j + 1, r = len - 1; l < r; l++, r--)
swap(arry[l], arry[r]);
int main()
Permutation();
return 0;
不知道大家是否记得STL---《algorithm》中的两个函数next_permutation和prev_permutation。链接分别是next_permutation,prev_permutation。
next_permutation:对于当前的排列,如果在字典序中还存在下一个排列,返回真,并且将下一个排列赋予当前排列,如果不存在,就把当前排列进行递增排序。
prev_permutation对于当前的排列,如果在字典序中还存在前一个排列,返回真,并且将前一个排列赋予当前排列,如果不存在,就把当前排列进行递减排序。
那么利用next_permutation可以很轻松的实现全排列。
代码如下:
#include<iostream>
#include<algorithm>
using namespace std;
int arry[3] = 1,2,3 ;//len==3;
void Permutation()
do
printf("%d%d%d\\n", arry[0], arry[1], arry[2]);
while (next_permutation(arry, arry + 3));
int main()
Permutation();
return 0;
三:改进
上面我们讲了两种方法来求解全排列,但是上面的问题是不可重复全排列,给出的初始序列各个元素互不相同,但是如果其中有相同的呢?结果会是如何?这个问题就是可重复全排列了。
我们知道对于一个n个元素的序列(分别是n1,n2,n3,,,,nn),如果其中有k个元素相等,那么这个序列的全排列个数就是 n!/k!。这是数学内容了,不做细讲。
假如给出序列1,2,2,用上述的递归和字典树法求全排列:
对于递归:

明显不对,有多个重复的排列。如何解决?
其实只要在交换元素之前判断是否相等即可,改进代码如下:
#include<iostream>
#include<algorithm>
using namespace std;
int arry[3] = 1,2,2 ;
bool IsEqual(int s, int t)
for (int i = s; i < t; i++)
if (arry[i] == arry[t])
return true;
return false;
void Recursion(int s, int t)
if (s == t)
for_each(arry, arry + 3, [](int i) printf("%d", i); ), printf("\\n");
else
for (int i = s; i <= t; i++)
if (!IsEqual(s, i))//不相等才能交换
swap(arry[i], arry[s]);
Recursion(s + 1, t);
swap(arry[i], arry[s]);
int main()
Recursion(0, 2);
return 0;
输出如下:

为什么那样判断?举个例子:对于 1abc2xyz2 这样的排列,我们交换1与第一个2,变成2abc1xyz2,按照递归的顺序,接下来对abc1xyz2进行全排列;但是1是不能和第二个2交换的,如果交换了,变成了2abc2xyz1,按照递归的顺序,接下来对abc2xyz1进行全排列,那么问题来了,注意我红色突出的两个地方,这两个全排列进行的都是同样的工作,也就是如果1和第二个2交换必然会和前面重复。
同样的对于字典序法,改进如下:
#include<iostream>
#include<algorithm>
using namespace std;
int arry[3] = 1,2,2 ;//len==3;
void Permutation()
int len = 3;
int j, k;
while (true)
printf("%d%d%d\\n", arry[0], arry[1], arry[2]);
for (j = len - 2; j >= 0 && arry[j] >= arry[j + 1]; j--);//注意此处 j >= 0 判断条件在前,加个等号即可
if (j < 0) return;//结束
for (k = len - 1; k > j&&arry[k] <= arry[j]; k--);//加个等号即可
swap(arry[k], arry[j]);
for (int l = j + 1, r = len - 1; l < r; l++, r--)
swap(arry[l], arry[r]);
int main()
Permutation();
return 0;
对于STL中的next_permutation呢?这就不需多虑了,STL里已经把相同元素的情况考虑进去了,代码不变。读者可以自己试试。
参考博客: http://blog.csdn.net/cpfeed/article/details/7376132
以上是关于全排列的实现方法--递归&字典序的主要内容,如果未能解决你的问题,请参考以下文章