Hadoop集群搭建
Posted 北北的乔安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群搭建相关的知识,希望对你有一定的参考价值。
Hadoop集群搭建
- 8.设置HDFS参数,关闭hadoop集群权限校验(安全配置),允许其他用户连接集群
- 9.设置YARN运行环境$JAVA_HOME参数(yarn-env.sh,使用绝对路径)
- 10.设置YARN核心参数,指定mapreduce 获取数据的方式为mapreduce_shuffle (yarn-site.xml)
- 11.设置计算框架参数,指定MR运行在yarn上 (mapred-site.xml)
- 12.设置节点文件slaves,要求slave1、slave2为子节点
- 13.对文件系统进行格式化
- 14.启动Hadoop集群查看各节点服务
- 15.查看集群运行状态是否正常
- (补充)设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141:
8.设置HDFS参数,关闭hadoop集群权限校验(安全配置),允许其他用户连接集群
在master、slave1、slave2上操作:
修改 hdfs-site.xml 文件以设置HDFS参数:
vim hdfs-site.xml
<property>
<!--备份文本数量为2-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--namenode节点数据存储目录-->
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<!--datanode节点数据存储目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
9.设置YARN运行环境$JAVA_HOME参数(yarn-env.sh,使用绝对路径)
在master、slave1、slave2上操作:
vim yarn-env.sh
修改yarn-env.sh中的第23行为JAVA_HOME路径:
export JAVA_HOME=/usr/java/jdk1.8.0_171

10.设置YARN核心参数,指定mapreduce 获取数据的方式为mapreduce_shuffle (yarn-site.xml)
- 在master、slave1、slave2上操作:
Hadoop完全分布式集群[环境]
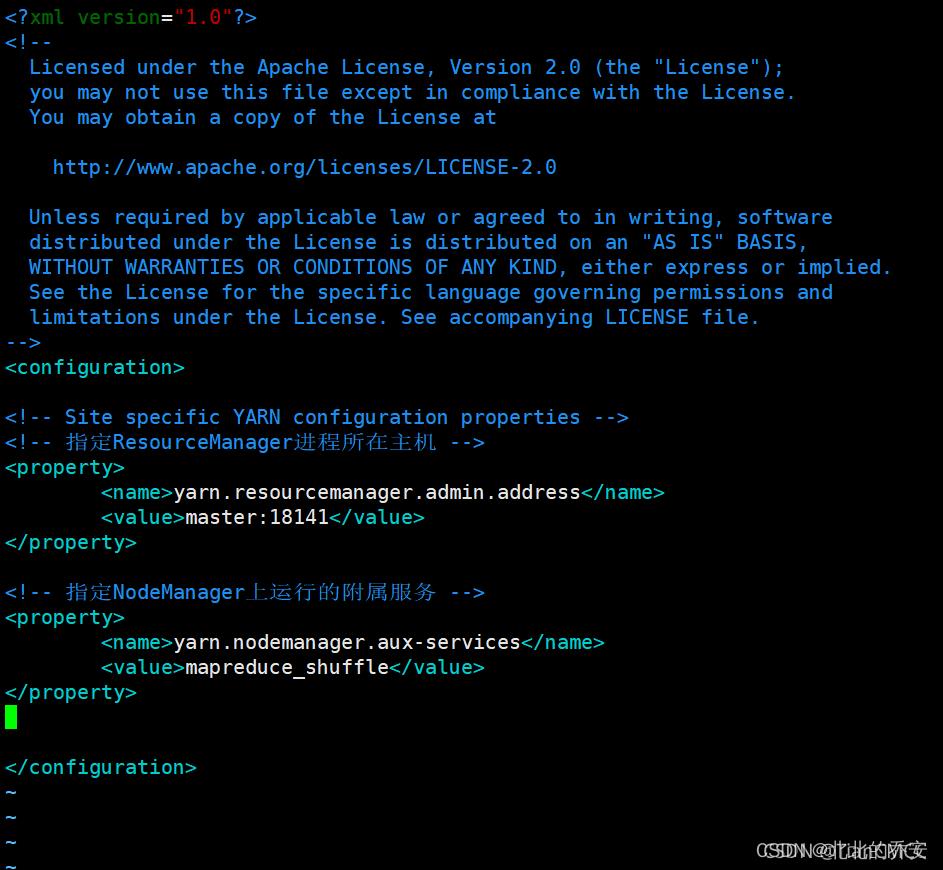
vim yarn-site.xml
在< configuration></ configuration>中添加如下内容 :
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
11.设置计算框架参数,指定MR运行在yarn上 (mapred-site.xml)
在master、slave1、slave2上操作:
Hadoop集群中没有mapred-site.xml这个文件,因此需要把mapred-site.xml.template复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
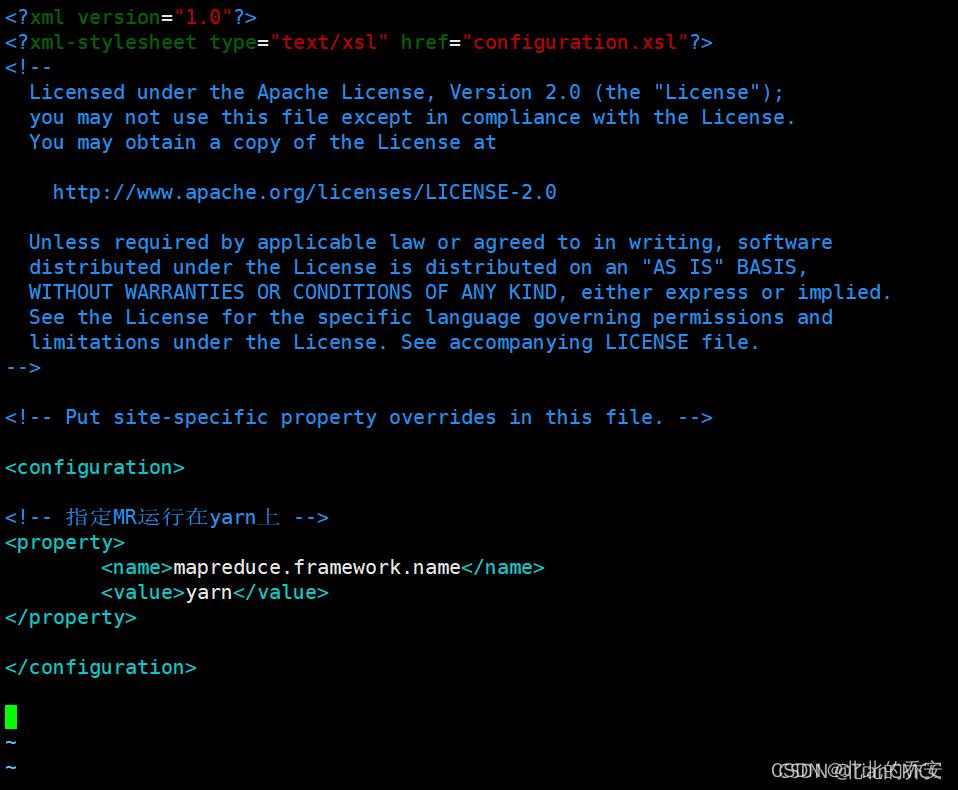
vim mapred-site.xml
在< configuration></ configuration>中添加如下内容 :
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
12.设置节点文件slaves,要求slave1、slave2为子节点
在master、slave1、slave2上操作:
还是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路径下,修改master、slaves文件:
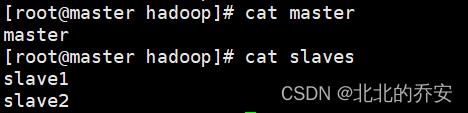
vim master
=== 写入 ===
master
vim slaves
=== 写入 ===
slave1
slave2
13.对文件系统进行格式化
在master上操作:
hadoop namenode -format

14.启动Hadoop集群查看各节点服务
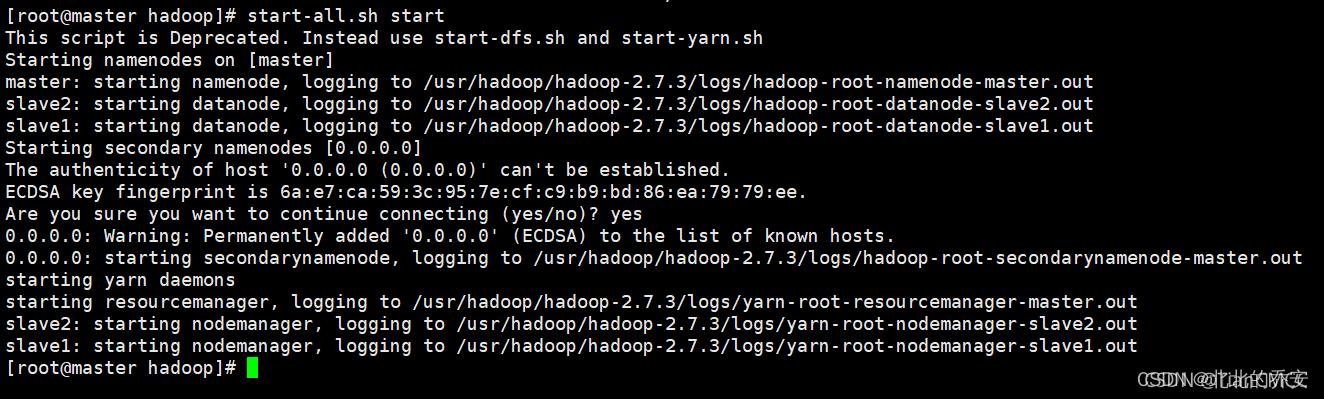
在master上操作:
start-all.sh start
然后输入 yes 即可启动:
15.查看集群运行状态是否正常
hadoop dfsadmin -report
也可以查看java进程中的namenode和datanode是否启动jps
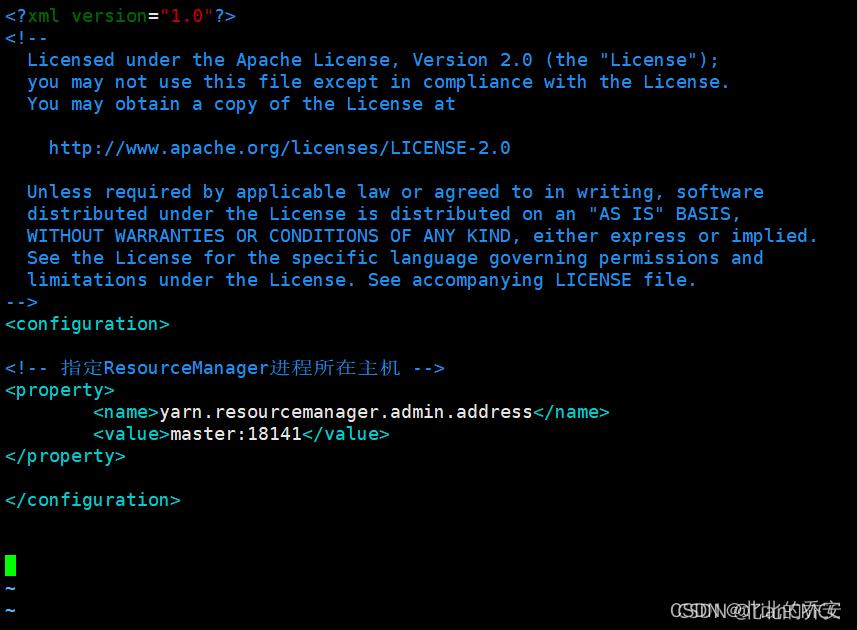
(补充)设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141:
在master、slave1、slave2上操作:
vim yarn-site.xml
在< configuration></ configuration>中添加如下内容 :
<!-- 指定ResourceManager进程所在主机 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
以上是关于Hadoop集群搭建的主要内容,如果未能解决你的问题,请参考以下文章