cpu设计和实现(pc跳转和延迟槽)
Posted 嵌入式-老费
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cpu设计和实现(pc跳转和延迟槽)相关的知识,希望对你有一定的参考价值。
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
cpu按部就班地去取指执行是理想情况。很多时候,cpu的pc寄存器会跳来跳去的。跳转的情况很多,一般可以分成三种。第一,绝对跳转;第二,条件跳转;第三,异常跳转。绝对跳转,很容易理解,就是不得不做的跳转,比如在主函数里面调用子函数这种就属于绝对跳转。当然,函数调用的时候还需要把返回的地址保存一下。条件跳转,这种也很常见,就是对数据进行判断后,根据结果来分析下是否需要跳转。而异常跳转,就是发生异常情况不得不做的跳转,比如指令错误,数据除0,访存地址不对齐等等。这些都算是异常跳转。
今天我们分析的是绝对跳转和条件跳转。根据cpu五级流水线的理论,跳转的地址判断需要在ex阶段才能给出来。但是这个时候pc已经连续给出了两个地址了。也就是说,如果关于跳转的地址计算只能在ex阶段给出,那么cpu还必须要执行跳转指令后面的两条指令。否则的话,cpu就要采取flush流水线的方法来进行解决,这对整个cpu的性能来说,其实是很伤的。
那mips是怎么做的呢?目前来说,针对跳转问题,mips采取了两个方法。第一,引入延迟槽的概念,也就是说跳转指令后面的指令也会被强制执行;第二,就是把地址的判断和输入提前到译码阶段来进行。当然,既然跳转指令后面的延迟槽指令也会被强制执行,这部分要么用nop代替,要么就要编译器帮忙,引入一些有用的指令了。
1、绝对跳转
`EXE_J: begin
wreg_o <= `WriteDisable; aluop_o <= `EXE_J_OP;
alusel_o <= `EXE_RES_JUMP_BRANCH; reg1_read_o <= 1'b0; reg2_read_o <= 1'b0;
link_addr_o <= `ZeroWord;
branch_target_address_o <= pc_plus_4[31:28], inst_i[25:0], 2'b00;
branch_flag_o <= `Branch;
next_inst_in_delayslot_o <= `InDelaySlot;
instvalid <= `InstValid;
end这是译码阶段的verilog代码。从代码可以看出,这个时候其实已经把给pc的jump地址准备好了,也就是branch_target_address_o。同时,branch_flag_o也置为真。
2、条件跳转
`EXE_BEQ: begin
wreg_o <= `WriteDisable; aluop_o <= `EXE_BEQ_OP;
alusel_o <= `EXE_RES_JUMP_BRANCH; reg1_read_o <= 1'b1; reg2_read_o <= 1'b1;
instvalid <= `InstValid;
if(reg1_o == reg2_o) begin
branch_target_address_o <= pc_plus_4 + imm_sll2_signedext;
branch_flag_o <= `Branch;
next_inst_in_delayslot_o <= `InDelaySlot;
end
end这是条件跳转,和绝对跳转不同的是,这里多了一个reg1_o和reg2_o的判断。也就是只有两个数据相等的时候,才会进行跳转处理。这个时候,细心的同学还会发现,除了设置branch_target_address_o和branch_flag_o之外,还有一个next_inst_in_delayslot_o的输出?这个数值是做什么用的。其实,这个数值是给异常处理用的。因为异常处理的时候,如果发现此时处理的指令是延迟槽的指令,那么就是做pc-4的处理,其中原因大家可以好好思考一下。
3、函数调用式跳转
`EXE_JALR: begin
wreg_o <= `WriteEnable; aluop_o <= `EXE_JALR_OP;
alusel_o <= `EXE_RES_JUMP_BRANCH; reg1_read_o <= 1'b1; reg2_read_o <= 1'b0;
wd_o <= inst_i[15:11];
link_addr_o <= pc_plus_8;
branch_target_address_o <= reg1_o;
branch_flag_o <= `Branch;
next_inst_in_delayslot_o <= `InDelaySlot;
instvalid <= `InstValid;
end 和前面的跳转一样,这里也对branch_target_address_o、branch_flag_o、next_inst_in_delayslot_o进行了输出。但是除此之外,还增加了一个link_addr_o输出。这主要是因为在函数调用的时候,cpu不光要跳转到指定的地址执行,还需要知道返回来的pc地址。而这个link_addr_o就是返回来的地址,它在wb阶段会写入指定的寄存器中。当然函数调用和异常返回,虽然都会回到之前的函数继续执行,但是函数调用不会flush流水线,而中断、异常发生的时候会对整个的流水线进行flush处理,这就是最大的区别。另外需要注意的是,因为延迟槽的关系,返回的pc地址是当前pc+8,而不是pc+4,这个和一般的cpu处理器不太一样。
4、修改pc_reg.v代码
always @ (posedge clk) begin
if (ce == `ChipDisable) begin
pc <= 32'h00000000;
end else if(stall[0] == `NoStop) begin
if(branch_flag_i == `Branch) begin
pc <= branch_target_address_i;
end else begin
pc <= pc + 4'h4;
end
end
end有了译码阶段给出的branch_target_address_i和branch_flag_i,这个时候pc就可以按照我们之前的设计跳转到合适的地方了。
5、准备汇编测试代码
.org 0x0
.set noat
.set noreorder
.set nomacro
.global _start
_start:
ori $1,$0,0x0001 # $1 = 0x1
j 0x20
ori $1,$0,0x0002 # $1 = 0x2
ori $1,$0,0x1111
ori $1,$0,0x1100
.org 0x20
ori $1,$0,0x0003 # $1 = 0x3
jal 0x40
div $zero,$31,$1 # $31 = 0x2c, $1 = 0x3
# HI = 0x2, LO = 0xe
ori $1,$0,0x0005 # r1 = 0x5
ori $1,$0,0x0006 # r1 = 0x6
j 0x60
nop
.org 0x40
jalr $2,$31
or $1,$2,$0 # $1 = 0x48
ori $1,$0,0x0009 # $1 = 0x9
ori $1,$0,0x000a # $1 = 0xa
j 0x80
nop
.org 0x60
ori $1,$0,0x0007 # $1 = 0x7
jr $2
ori $1,$0,0x0008 # $1 = 0x8
ori $1,$0,0x1111
ori $1,$0,0x1100
.org 0x80
nop
_loop:
j _loop
nop
6、翻译成指令文件
34010001
08000008
34010002
34011111
34011100
00000000
00000000
00000000
34010003
0c000010
03e1001a
34010005
34010006
08000018
00000000
00000000
03e01009
00400825
34010009
3401000a
08000020
00000000
00000000
00000000
34010007
00400008
34010008
34011111
34011100
00000000
00000000
00000000
00000000
08000021
00000000
8、开始波形仿真和测试
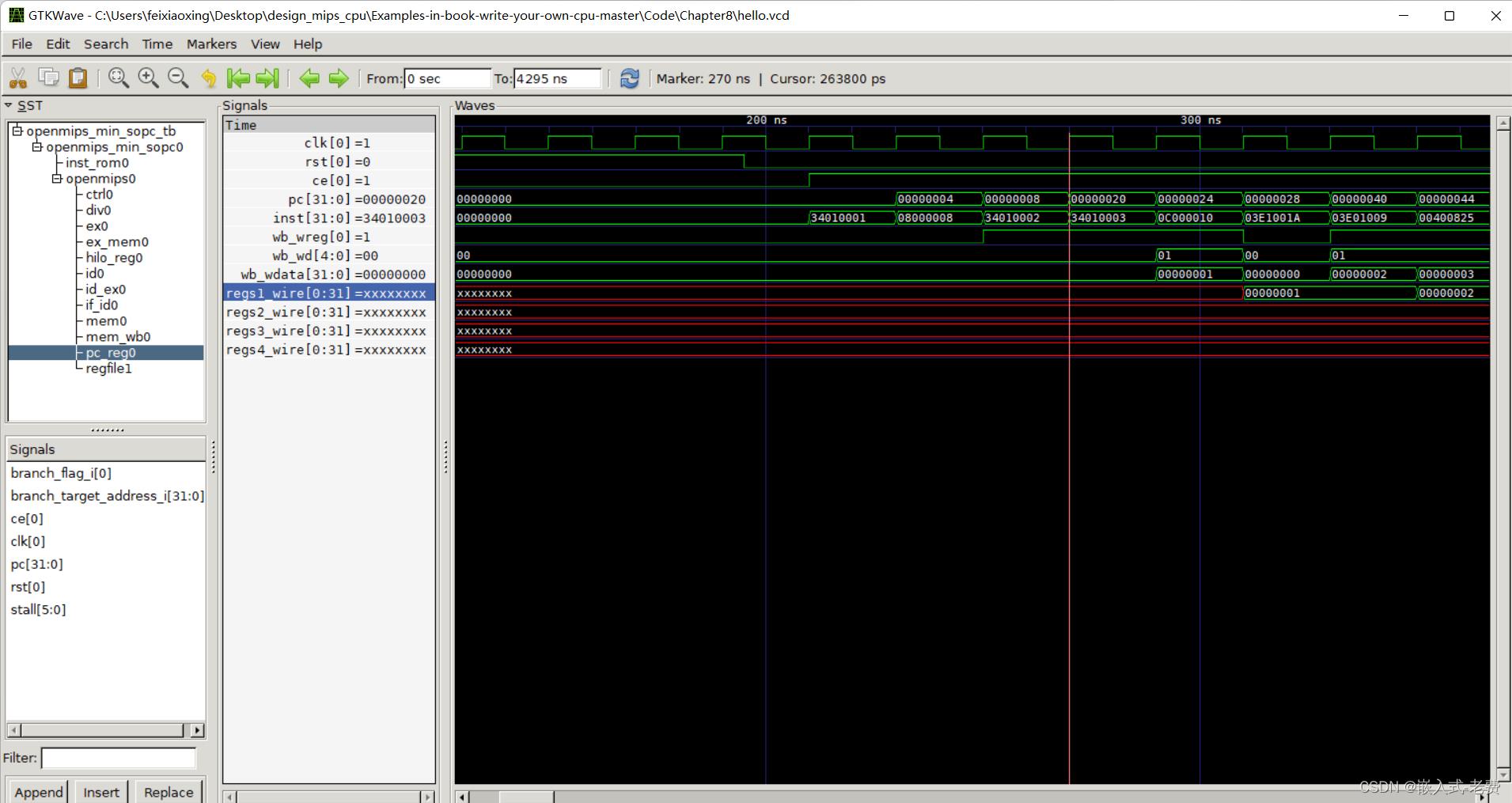
利用iverilog、vvp、gtkwave工具进行编译、运行和显示之后,就可以判断一下跳转的功能有没有实现了。整个波形当中最关键的指标非pc寄存器莫属。当然,我们分析的时候还是一步一步来。
首先查看rst结束,接着就是ce置位,然后就是pc寄存器数值的更替。通过观察,我们发现pc的地址依次是0x0、0x4、0x8、0x20这样的。这个时候可以看一下测试的汇编代码。第一条汇编代码是ori $1,$0,0x0001 ,第二条指令是j 0x20,第三条指令是ori $1,$0,0x0002。而此时,0x20出的代码是,
.org 0x20
ori $1,$0,0x0003这说明两点。第一,pc跳转到0x20是完全正确的,获取的指令也是正确的。第二,在pc发生跳转的时候,当前指令的下一条指令,也就是延迟槽的指令也是被执行的。从上面的图形看,0x4是j 0x20,按照道理来说,下一条指令pc应该修改成了0x20。但是,我们发现pc在递增到0x8之后,才会真正修改为0x20,这说明延迟槽起了作用。
在实际应用中,延迟槽发挥了很大的作用,但是也给我们后续处理带来了一些麻烦,比如在发生异常中断的时候就要对延迟槽做特别的处理,而且要非常小心才行。
以上是关于cpu设计和实现(pc跳转和延迟槽)的主要内容,如果未能解决你的问题,请参考以下文章