Linux——MySQL高阶语句杂而精
Posted 孤岛上的笛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux——MySQL高阶语句杂而精相关的知识,希望对你有一定的参考价值。
目录标题
- 按关键字排序
- 按单字段排序
- 多字段排序
- 嵌套/多条件
- 查询不重复的记录
- 对结果进行分组
- 分组排序
- 限制结果条目=从第几行开始查询几条结果
- 设置别名
- 通配符
- 子查询
- 视图
- null值
- 正则表达式
- 运算符
- 比较运算符
- 逻辑运算符
- 位运算符
- 连接查询
按关键字排序
通过select查询出来的数据使用order by 语句来实现排序
order by 前面也可以使用where子句对查询结果进一步过滤
排序可针对一个或多个字段
ASC:升序,默认排序方式
DESC:降序
按单字段排序
降序
select id,name,level from player where level>=45 order by level desc;
查看player表的id,name,level字段where判断level值大于等于45。
且order by 对 level 字段进行排序 desc为降序从大到小。
升序
select id,name,level from player where level>=45 order by level ;
查看player表的id,name,level字段where判断level值大于等于45。
且order by 对 level 字段进行排序 为升序从小到大,默认值为ASC可以不写。
多字段排序
原则:
order by 之后的参数,使用 ,分割,优先级实按先后顺序而定,例
select id,name,hobby from info order by id asc,hobby desc;
查看info表的id,name,hobby字段先对id进行升序,再对hobby降序
select id,name,hobby from info order by hobby descid asc;
查看info表的id,name,hobby字段先对hobby进行降序,再对id升序
小结:order by 之后的第一个参数只有在出现相同的数值,第二个字段才有意义
- or/and
或/且
select * from info where score >70 and score <=90;
查看info表中score字段中大于79且小于等于90的数据
select * from info where score >70 or score <=90;
查看info表中score字段中大于70或小于等于90的数据
嵌套/多条件
select * from info where score >70 or (score >75 and score <=90);
查看info表中score字段中大于70或大于75且小于等于90的数据
括号内是一个集合
查询不重复的记录
select distinct 字段 from 表名;格式
select distinct hobby from info;
查看info表中hobby字段的内容且不重复
distinct 必须放在最开头
distinct只能使用需要去重的字段进行操作,即去重的字段才能操作排序不是去重的字段则不行
distinct去重多个字段时,含义是:几个字段同时重复时才会被过滤
对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 group by 语句来实现, group by 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(count)、求和(sum)、求平均数(avg)、最大值(max)、最小值(min), group by 分组的时候可以按一个或多个字段对结果进行分组处理
语法:
select 字段, 聚合函数 from 表名, (where 字段名 (匹配) 数值) group by 字段名;
例:
select count(name),level from player where level>=45 group by level;
对player进行分组,筛选范围/条件是level大于等于45的 ‘name’ ,level相同的会默认分在一个组
分组排序
select count(id),hobby from info group by hobby;
对info表中hobby相同的id进行数量统计,并按照相同hobby进行分组
select count(id),hobby from info group by hobby order by count(id) desc;
基于上一条操作,结合order by 把统计的id数量进行按降序排列
限制结果条目=从第几行开始查询几条结果
在使用 mysql select 语句进行查询时,结果集返回的是所有匹配的记录。有时候仅需要返回第一行或者前几行,这时候就需要用到limit子句
语法
select column1,column2,... from table_name limit [offset,] number
offset,number:
limit 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。
如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的位置偏移量是0,第二条是1,以此类推。第二个参数是设置返回记录行的最大数目。
offset:索引下标
number:索引下标之后的几位
结合 order by 排序:
select * from info order by id desc limit 3,4
查询info表中id字段从第三天条记录开始后的四条记录以升序的方式查看
设置别名
设置别名在 MySQL查询时,当表的名字比较长或者表内某些字段比较长是,为了方便书写或者多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简介明了,增强可读性
语法:
对于列的别名:select column_name as alias_name from table_name;
对于表的别名:select column_name from table_name as alias_name;
#as可以省略
在使用as后,可以用alias_name 代替 table_name,其中as 语句是可以选的。as之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名或字段时不会被改变的
列别名的设置示例:
select name as 姓名,score as 成绩 from info
表数据别名设置例:
select i.name as 姓名,i.score as 成绩 from info as i;
使用场景:
对复杂的表进行查询的时候,别名可以缩短查询语句
多表相连查询的时候(通俗易懂、减短SQL语句)
as作为连接语句
create table tmp as select * from info;
此处as起到的作用:
1、创建一个新表tmp 定义表结构,插入表数据(与info表相同)
2、但是“约束”没有被“复制”过来,但是如果原表设置了主键,那么附表的:default 字段默认设置一个0
相似:
克隆、复制表结构
create table tmp (select * from info);
#也可以加入where判断语句
create table test1 as select * from info where score >=60;
从info表“复制”要求score>=60的内容到新建的test1中
通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来
常用通配符都是跟like(模糊查询)一起使用的,并协同 where子句共同来完成查询任务,常用的通配符有两个,分别是:
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
查询名字是c开头的记录
模糊查询%示例:
select * from info where name like 'l%';
模糊查询_示例:
select * from info where name like 'l_s_';
结合使用
select * from info where name like 'l_%_';
子查询
定义、示例
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语句。
子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一步的查询过滤
子语句可以与主语句所查询的表相同,也可以是不同表
相同表(一条查询语句中查询的是相同的表):
select name,score from info where id in (select id from info where score>80);
以上主语句:select name,score from info where id
子语句(结果集):select id from info where score>80
in:将主表和子表关联/连接起来的语法
in 之后的子查询语句会给他提供的一个范围(集合),作为 in 之前 where 的判断条件
示例:
查询info表id 为1,3,5,7的数据(通过子查询的方式)
单表查询方式:
select * from info where id in (1,3,5,7)
子查询方式
create table num (id int(4));
insert into num values(1),(3),(5),(7);
select * from info where id in (select id from num);
子查询不仅可以在select 语句中使用,在inert、update、delete中也同样适用
支持多层嵌套
in 语句是用来判断某个值是否在给定的集合内(结果集),in 往往和select 搭配使用
可以使用not in 表示对结果集取反
子查询-别名as
先查询info表id,name字段
select id,name from info;
以上命令可查看到info表的内容(结果集)
将结果集作为一张表进行查询的时候,我们也需要用到别名,示例:
select id from (select id,name from info);此时会报错
ERROR 1248 (42000):Every derived table must have its own alias
原因:
select * from 表名,此为标准格式,而以上的查询语句,“表名”的位置其实是一个结果集,mysql并不能识别,而此时给与结果集设置一个别名,并且以select a.id,name from a;的方式查询,将此结果集视为一张表就可以正常查询出数据了
所以:
select a.id from (select id,name from info) a;
相当于:
select info.id,name from info;
select 表.字段,字段 from 表;
子查询-exists
select count(*) as number from tmp where exists (select id from tmp where name='zhangsan')
as number将count统计的结果作为number(列名)返回
exist:布尔值判断,后面的子查询语句是否成立的一个判断真或假
where:之后跟条件判断
加exists:只是为了判断exists之后的条件是否成立
成立,则正常执行主语句的匹配
不成立,则不会执行主语句查询
count 为计数,sum为求和,使用sum求和结合exists,如子查询结果集不成立的话,输出为null

视图
数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了映射
好比水中捞月的情景,动态保存结果集(数据)
视图我们可以定义展示的条件
示例:
需求:满足80分的学生展示在视图中
这个结果会动态变化,同时可以给与不同的人群(例如权限范围)展示不同的视图
创建视图
create view v_score as select * from info where score>=80;
查看视图
select * from v_score;
修改原表数据
update info set score='6' where name='wangwu;'
查看视图此时视图也随之改变
select * from v_score;
小结:
为什么说视图好比水中捞月,如果月亮(原表数据)发生改变倒影(视图)也会随之晃动改变,但是只对水中的倒影用石头打进行改变但月亮还是那个月亮不会改变,所以只是单方面的对应,起到了一定安全性的效果
null值
定义:
通常使用NULL来表示缺失的值,也就是在表中该字段时没有值的
如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL关键字,不使用则默认可以为空
在向表内插入记录或者更新记录时,如果该字段没有NOT NULL并且没有值,这时候新记录的该字段将被保存为NULL。需要注意的是,NULL值与数字 0 或者空白(spaces)的字段是不同的,值为NULL的字段时没有值的。
在SQL语句中,使用IS NULL可以判断表内的某个字段是不是NULL值,相反的勇IS NOT NULL可以判断不是NULL值
查询info表结构,id和name字段是不允许空值的
null值和控制的区别类似于空气和真空的区别
空值长度为0,不占空间,NULL值的长度为null,占用空间
is null无法判断空值
空值使用"=“或者”<>"来处理(!=)
count()计算时,NULL会忽略,空值会加入计算
验证
alter table info add column address varchar(50);
update info set address='nj' where score >=70;
统计数量:检测null是否会被加入统计中
select count(address) from info;
将info表中其中一条数据修改为空值
update info set address=' ' where name='wangwu';
统计数量检测空值是否会被添加到系统中
select count(address) from info;
查询null值
select * from info where is null;
查询不为空的值
select * from info where is not null;
正则表达式
MySQL正则表达通常是在检索数据库记录的时候,根据指定的匹配模式匹配记录中符合要求的特殊字符串。
MySQL的正则表达式使用 REGEXP 这个关键字来指定正则表达式的匹配模式
REGEXP 操作符所支持的匹配模式如下:
^匹配文本的开始字符
$匹配文本的结束字符
.匹配任何单个字符
*匹配零个或多个在它面前的字符
+匹配前面的字符1次或多次
字符串匹配包含指定的字符串
p1|p2匹配 p1 或 p2
[...]匹配字符集合中的任意一个字符
[^...]匹配不在括号中的任何字符
n匹配前面的字符串n次
n,m匹配前面的字符串至少 n 次,至多 m 次
^表示匹配开始字符,但需要看 ^所处的位置例如:[^]表示不包含^[],则表示以…为开头
示例^
select id,name from info where name regexp '^li'查询name字段li开头的数据
示例$
select * from info where address regexp 'j$';查询address字段j结尾的数据
示例.
select * from info where name regexp 'l..i';查询name字段 l 后有两个任意字符后有个i的数据
示例*
select * from info where name regexp 'g*';查询name字段匹配g零次或者多次
示例+
select * from info where name regexp 'b+';查询name字段中b匹配至少一次或多次的数据
示例字符串
select * from info where name regexp 'iu';查询name中指定的字符串
示例p1|p2
select * from info where name regexp 'wu|is';查询name字段中包含wu或者is的数据
示例[...]
select * from info where name regexp '[g,1]';匹配集合中任意一个字符
示例[^...]
select * from info where name regexp '[^lisi]';匹配除了lisi的任何字符
示例n
select * from info where name regexp 'o2';匹配前面字符串2次
select * from info where name regexp 'o1,2';匹配前面字符串至少一次至多2次
运算符
MySQL的运算符用于对记录中的字段值进行运算。MySQL的运算符共有四种,分别是算术运算符、比较运算符、逻辑运算符和位运算符
算术运算符
+ 加法
-减法
*乘法
/除法
%取余
在除法运算和求余运算中,除数不能为0,若除数是 0,返回的结果则为 NULL。如果有多个运算符,按照先乘除后加减的优先级进行运算,相同优先级的运算符没有先后顺序
例
select 1+2,2-1,2*3,5/3,6%2,4/2;
create table js select 1+2,5-1,2*3,5/3,6%3,4/2;创建名为js的表把运算结果作为表内容
desc js;查看表结构除法默认为最多小数后四位
比较运算符
字符串的比较默认不区分大小写,可使用binary来区分
常用比较运算符(比较对象:数字,字符)
= 等于
!=或<>不等于
LIKE通配符匹配
>大于
>=大于等于
<小于
<=小于等于
IS NULL判断一个值是否为NULL
IS NOT NULL判断一个值是否不为NULL
BETWEEN AND两者之间
GREATEST两个或多个参数时返回最大值
LEAST两个或多个参数时返回最小值
IN在集合中
等于(=)
用来判断数字、字符串和表达式是否相等的,如果相等则返回1,|如果不相等则返回0。如果比较的两者有一个值是NULL,则比较的结果就是NULL。
其中字符的比较是根据ASCII码来判断的,如果ASCII码相等,则表示两个字符相同;如果ASCII码不相等,则表示两个字符不相同。例如字符串(字母)比较: (‘a’ > ‘b’)其实比较的是底层ascll码
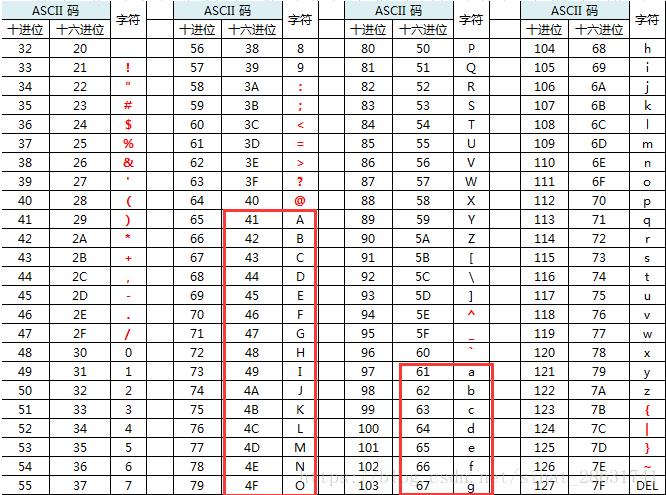
如果比较的是多字符,例如’abc’=‘acb’,是这么比较的?(字符顺序进行比较第一位比完比第二位一旦比对出结果则返回)
如果比较的是多字符,例如:‘abc’<'baa’是如何比较的?
与Linux返回值表达相反,Linux中运行正常返回的是0,运行异常返回的是非0值
不等于(!=或<>)
用于针对数字、字符串和表达式不相等的比较,如果不相等则返回1,如果相等则返回0,与等于(=)的返回值相反,同时不等于(!=,<>)无法用于判断是否为null
大于、大于等于、小于、小于等于运算符
大于(>)运算符用来判断左侧的操作数是否大于右侧的操作数,若大于返回1,否则返回0,同样不能用于判断NULL
小于(<)运算符用来判断左侧的操作数是否小于右侧的操作数,若小于返回1,否则返回0,同样不能用于判断NULL
大于等于(>=)判断左侧的操作数是否大于等于右侧的操作数,若大于等于返回1,否则返回0,不能用于判断NULL
小于等于(<=)判断左侧的操作数是否小于等于右侧的操作数,若小子等于返回1,否则返回0,不能用于判断NULL
两者之间(between…and…)
此较运算通常用于判断一个值是否落在某两个值之间。例如,判断某数字是否在另外两个数字之间,也可以判断某英文字,母是否在另外两个字母之间,具体操作,条件符合返回1,否则返回0
示例:
select 4 between 2 and 6,5 between 6 and 8,'c' between 'a' and 'f';
比较过程中是包含两边参数的值
当有两个或多个参数时,返回其中最大/最小值,如果一个为null,则返回null(least greatest)
示例:
select least(1,2,3),least('a','b','c'),greatest(1,2,3),greatest('a','b','c');

数字比较、按大小排列
字母比较,a-b顺序,字母越前越"小"
在/不在集合中(in ,not in )
IN判断已告知是否在对于的列表中,如果是返回1,否则返回0
NOT IN判断一个值是否不在对应的列表中,如果不在则返回1,否则返回
示例:
select 2 in (1,2,3,4,5),'c' not in ('a','b','c');

通配符匹配
LIKE用来匹配字符串,如果匹配成功则返回1,反之返回0.LIKE支持两种通配符:’%‘
用于匹配任意数目的字符,而’_‘只能匹配一个字符。NOT LIKE正好跟LIKE相反,如果没有匹配成功则返回1,反之返回0
判断某字符串能否匹配成功,分单字符匹配和多字符匹配,也可以判断不匹配,具体操作如下所示
select 'bdgn' LIKE 'bdq_ ','kge' LIKE '%c', 'etc' NOT LIKE ' %th';

逻辑运算符
逻辑运算符又被称为布尔运算符,通常用来判断表达式的真假,如果为真返回1,否则返回0,真和假也可以用TRUE和FALSE表示。MysQL中支持使用的逻辑运算符有四种
not 或 ! 逻辑非
and 或 && 逻辑与
or逻辑或
xor逻辑异或
逻辑非(not 或 !)
逻辑非将跟在他后面的值取反,如果not后面的操作数为0时,所得值为1:
如果操作数为非0时,所得值为0;
如果操作数为NULL时,所得值为NULL
小结;返回值为0, 1, null值(根据匹配条件判断为何值)
select not 2,!3,not 0,!(4-4);

逻辑与(AND或&)
AND 和 &&都是逻辑与运算符,具体语法规则为:
当所有操作数都为非零值并且不为NULL时,返回值为1
当一个或多个操作数为0时,返回值为0;操作数中有任何一个为NULL时,返回值为NULL
select 2 and 1,2 && 0 , 0 && null,2 and null;

and 和 && 作用相同
AND -1中没有0 或者NULL,所以返回值为1
AND 0中有操作数0,所以返回值为0;
AND NULL虽然有NULL,所以返回值为NULL
null 和 0 返回值为0
逻辑或(OR)
OR是逻辑或运算符,具体语法规则为:
当两个操作数都为非NULL值时,如果有任意一个操作数为非零值,则返回值为1,否则结果为0:
当有一个操作数为NULL时,如果另一个操作数为非零值,则返回值为1,否则结果为NULL
假如两个操作数均为NUL时,则返回值为NULL
select 2 or 3 ,0 or null,1 or 1,0 or 0;

逻辑异或
XOR表示逻辑异或,具体语法规则为:
当任意一个操作数为NULL时,返回值为NULL;
对于非NULL的操作数,如果两个操作数都是非 0值或者都是0值,则返回值为1;
如果一个为0值,另一个为非0值,返回值为1
select 2 xor 3, 0 xor 1,1 xor 0,1 xor null,null xor 0;

位运算符
位运算符是在二进制数上进行计算的运算符。
位运算会先将操作数变成二进制制数进行位运算。
然后再将计算结果从二进制数变回十进制数。
& 按位与
| 按位或
^ 按位异或
! 取反
<< 左移
>> 右移
按位与运算(&) ,是对应的二进制位都是1的,它们的运算结果为1,否则为0,所以10 & 15的结果为10.
select 10 & 15;
按位或运算(|) ,是对应的二进制位有一个或两个为1的,运算结果为1,否则为0, 所以101 15的结果为15
select 10 | 15;
按位异或运算(^) ,是对应的二进制位不相同时,运算结果1,否则为0,所以10^ 15的结果为5
select 10 ^ 15 ;
按位取反(~) ,是对应的二进制数逐位反转,即1取反后变为0,0取反后变为1,数字1的二进制是0001,取反后变为1110,数字5的二进制是0101,将1110和0101进行求与操作,其结果是二进制的0100,转换为十进制就是4;
select 10 &~1;
以上运算符优先级
1:!
2:~
3:^
4:*,/,%
5:+,-
6:>>,<<
7:&
8:|
9:=,<=>,>=,<=,<>,!=,IS,LIKE,REGEXP,IN
10:BETWEEN,CASE,WHEN,THEN,ELSE
11:NOT
12:&&,AND
13:OR,XOR
14::=
15:
16:
连接查询
MySQL的连接查询,通常都是将来自两个或多个表的行结合起来,基于这些表之间的共同字段,进行数据的拼接。首先,要确定一个主表作为结果集,然后将其他表的行有选择性的连接到选定的主表结果集上。使用较多的连接查询包括:内连接、左连接和右连接
模板
create table test1 (a_id int(11) default null,a_name varchar(32) default null,a_level int(11) default null);
create table test2 (b_id int(11) default null,b_name varchar(32) default null,b_level int(11) defauult null);
insert into test1(a_id, a_name, a_level) values(1, 'aaaa', 10);
insert into test1(a_id, a_name, a_level) values(2, 'bbbb', 20);
insert into test1(a_id, a_name, a_level) values(3, 'cccc', 30);
insert into test1(a_id, a_name, a_level) values(4, 'dddd', 40);
insert into test2(b_id, b_name, b_level) values(2, 'bbbb', 20);
insert into test2(b_id, b_name, b_level) values(3, 'cccc', 30);
insert into test2(b_id, b_name, b_level) values(5, 'eeee', 50);
insert into test2(b_id, b_name, b_level) values(6, 'ffff', 60);
内连接
MySQL中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在FROM子句中使用关键字INNER JOIN来连接多张表,并使用 on 字句设置连接条件,内连接是系统默认的表连接,所有在from 字句后可以省略inner 关键字,只使用 关键字 jion 同时有多个表时,也可以连续使用 inner join 来实现多表的内连接,不过为了更好 性能,建议最好不要超过三个表
select a.a_id,a.a_name,a.a_level from test1 as a inner join test2 b on a_id=b_id;
select a_id,a_name,a_level from test1 inner join test2 on a_id = b_id;
左连接
左连接也可以被称为左外连接,在FROM子句中使用LEFT JOIN或者LEFT OUTER JOIN关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
select * from test1 left join test2 on test1.name=test2.name
左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为NULL
右连接
右连接也被称为 右外连接,在 from 字句中 使用 right join 或者 right outer join关键字来表示,右连接跟左连接正好相反,他是以右表为基础表,用于接受右表中的所有行,并用这些记录与记录左表中的行进行匹配
select * from test1 right join test2 on a.name=b.name;
在右表连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹配的行,这些记录在左表中以null 补足
以上是关于Linux——MySQL高阶语句杂而精的主要内容,如果未能解决你的问题,请参考以下文章