hadoop hdfs运行机制
Posted node2017
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop hdfs运行机制相关的知识,希望对你有一定的参考价值。
hdfs特点
hdfs是hadoop的分布式文件系统,用于存储大数据,它的特点是:
1.分布式部署,利用廉价的机器存储大数据
2.提供副本机制,容错机制,在机器宕机或副本丢失,自动恢复,默认副本保存3份

关注三个主要节点:
1.NameNode:整个文件系统的管理节点,接收用户的请求,保存着文件/目录的元数据信息和每个文件对应的block的映射列表。在linux系统上,它保存着三个重要文件
a.fsimage,元数据镜像文件,存储某一段时间内的namenode的元数据信息
b.edits,保存操作日志文件
c.fstime,保存最近一次checkpoint的时间
2.DataNode:提供真实文件的数据存储服务,它文件的多个块(Block),block是最基础的存储单位,hdfs默认的块大小的是128M。
3.SecondaryNameNode:冷热备,合并fsimage和fsedits生成新的fsimage,然后再发给namenode,替换旧的fsimage
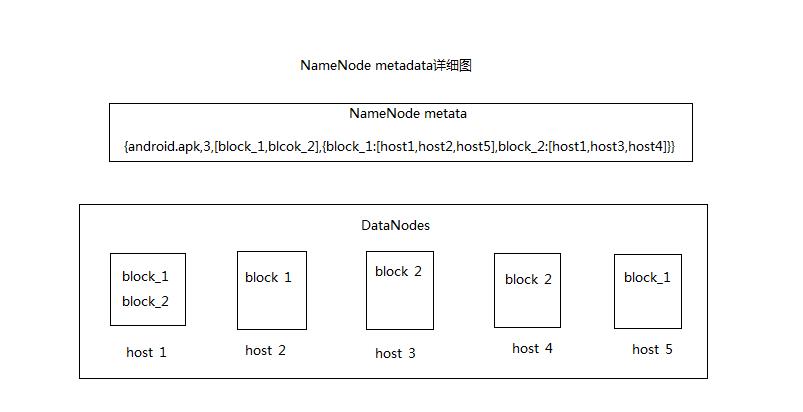
NameNode元数据详细
NameNode metadata主要存放FileName,replications,block-ids,还有blockid到host的映射,例如,有一个文件名为android.apk写到hdfs系统中,那medata将会保存如下信息
客户端向hdfs读数据的过程
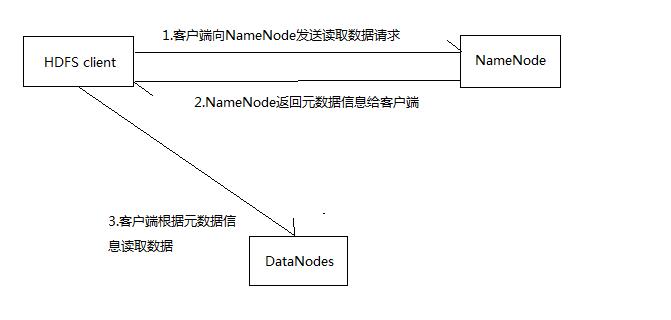
文件读取的过程如下:
1.客户端向Namenode发起RPC请求;
2.Namenode返回该文件的元数据信息,包括,文件名称,分块的id已经和分块id和主机的映射等等
3.客户端根据元数据信息向最近的DataNode读取block,如果客户端本身是DataNode,那么将直接从本地获取数据,block的读取是同步的,即读完一块block,才可以读另外一块block。
4.读取完一个block都会进行checksum验证,如果发现该block错误,那么客户端会通知NameNode,NameNode将会从其他拷贝副本选择一份让客户端继续读取
客户端向hdfs写数据的过程
1.客户端通过RPC向NameNode提交写数据请求
2.NameNode检查该文件是否存在,客户端是否有权限写数据,如果可以写入,则为该文件创建一条记录,如果不可以,则向客户端抛出异常。
3.客户端接收到NameNode允许写操作之后,将文件进行切分成多个packets,并向NameNode申请blocks,NameNode返回blocks列表给客户端
4.客户端接收到blocks列表之后,开始将packets写到blocks列表中,当将packet写到第一个DataNode完成时,该DataNode会把该分块的数据复制到其他DataNode中,默认是复制3份。
5.最后一个datanode成功存储之后通过客户端,客户端接收到消息之后,将会移除相应的packet,并通知NameNode,NameNode就会在内存中的Metadata中添加一条该文件信息的描述,并在edits日志文件中写入一条记录
6.如果写数据的过程中,发生异常,都会在edits日志文件中记录操作。
NameNode和SecondaryNameNode协助过程
SecondaryNameNode的作用是协作NameNode完成fsimage的保存和更新,协作过程如下。
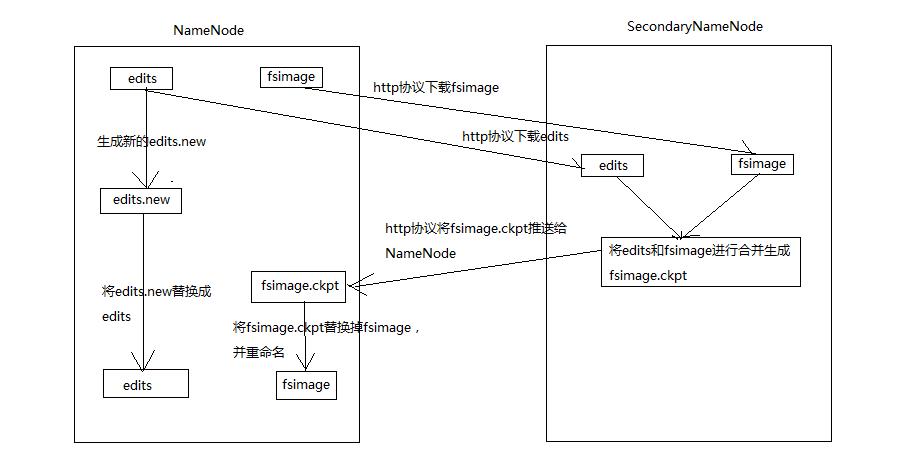
1.SecondaryNameNode根据checkpoint的设置,将NameNode的edits和fsimage下载到本地,并进行合并生成fsimage.ckpt
2.在下载edits和fsimage的时候,不允许删除edits和fsimage,防止下载和合并过程中出现错误,造成文件不能恢复,另外,在卸载edits的过程中,NameNode会生成新的edits.new,让客户端操作NameNode的时候,不会出现异常和数据不一致问题
3.fsimage生成之后,将fsimage.ckpt推送给NameNode,NameNode将把旧的fsimage替换掉,并把edits.new切换成edits
4.将旧的fsimage和edits删除
什么时候checkpoint
1.设置fs.checkpoint.period指定俩次checkpoint的最大时间,默认是3600秒
2.设置fs.checkpoint.size规定edits文件的最大值,默认是64m
只要满足这俩个条件,SecondaryNameNode就会下载edits和fsimage生成新的fsimage镜像
以上是关于hadoop hdfs运行机制的主要内容,如果未能解决你的问题,请参考以下文章