计算机视觉算法——目标检测网络总结
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉算法——目标检测网络总结相关的知识,希望对你有一定的参考价值。
计算机视觉算法——目标检测网络总结
- 计算机视觉算法——目标检测网络总结
计算机视觉算法——目标检测网络总结
由于后面工作方向的需要,也是自己的兴趣,我决定补习下计算机视觉算法相关的知识点,参考的学习资料主要是B站Up主霹雳吧啦Wz,强推一下,Up主的分享非常的细致认真,从他这里入门是个不错的选择,Up主也有自己的CSDN博客,我这里主要是作为课程的笔记,也会加入一些自己的理解,我也只是个入门的小白,如果有错误还请读者指正。
目标检测网络是计算机视觉一个重要的应用领域,主要分为One-Stage和Two-Stage两类方法,下面开始逐个总结各个图像分类网络的特点。
1. RCNN系列
RCNN系列是由RCNN->Fast RCNN->Faster RCNN组成,三个网络的框架分别如下图所示:
RCNN网络框架:
Fast RCNN网络框架:

Faster RCNN网络框架:

下面分别介绍这三个网络细节
1.1 RCNN
RCNN是2014年提出的,一经提出就将目标检测准确率提升了30%
1.1.1 关键知识点——网络结构及特点
RCNN网络结构如下图所示: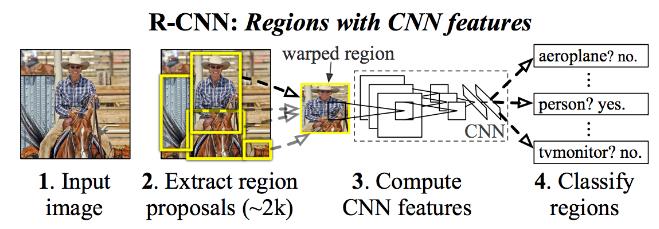
该算法主要分为四个步骤:
- 使用Selective Search方法在图像上生成1000至2000个候选区域;
Selective Search算法是通过图像分割的方法得到一些原始区域,然后使用合并策略将区域合并从而得到一个层次化的区域结构,而这些结构中就包含着可能需要检测的物体。 - 对每个候选区域使用深度网络(图像分类网络)提取特征;
将2000个候选区域缩放到 227 × 227 227\\times227 227×227个像素大小,然后将候选区域输入实现训练好的AlexNet CNN网络获得4096维的特征,即 2000 × 4096 2000 \\times 4096 2000×4096维的矩阵。 - 将特征送入每一类的SVM分类器,判断该区域是否属于该类;
将 2000 × 4096 2000 \\times 4096 2000×4096维特征与20个SVM分类器组成的 4096 × 20 4096 \\times 20 4096×20维权重矩阵相乘,获得 2000 × 20 2000 \\times 20 2000×20维矩阵,该矩阵表示每个建议框是某个目标分类的得分,如下图所示: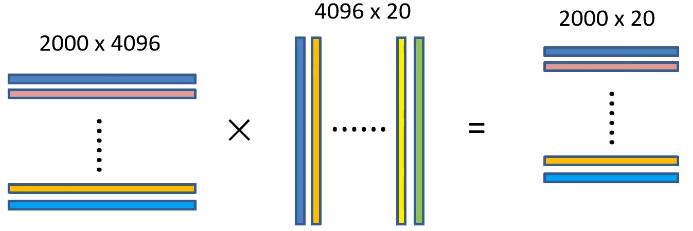
分别对上述 2000 × 20 2000 \\times 20 2000×20维矩阵中每一列即每一列进行非极大值抑制剔除重叠建议框,得到该类中得分最好的建议框。非极大值抑制算法在后文介绍。 - 使用回归器精细修正候选框位置;
对通过非极大值抑制处理后的剩余边界框进行进一步筛选,接着分别用20个回归器对上述20个类别的建议框进行回归操作,最终得到每个类别修正后得分最高的边界框,这个回归操作在后面的Fast RCNN进行详解。
1.1.2 关键知识点——RCNN存在的问题
- 测试速度慢,测试一张图片在CPU上需要53S,使用Selective Search算法提取候选框需要2S,一张图像内候选框之间存在大量重叠,提取特征操作存在大量冗余;
- 训练速度慢,过程极其繁琐,不仅需要训练图像分类网络,还需要训练SVM分类器、Bounding Box回归器,训练过程都是相互独立的;
- 训练所需空间大,对于SVM和Bounding Box回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘,对于非常深的网络,训练集上5K图像上提取的特征需要数百GB的存储空间。
1.1.3 关键知识点——非极大值抑制算法(NMS)
RCNN中应用的非极大值抑制算法的步骤如下:
- 在当前类别的候选边界框中寻找得分最高的边界框;
- 计算其他边界框与该边界框的IOU值;
- 删除所有IOU值大于给定阈值的目边界框;
经过上述步骤后就将最高得分的目标保存下来,再在剩下的边界框中寻找得分最高的边界框重复上述步骤。其中IOU值的计算即两个边界框交集的区域面积除以两个边界框并集区域面积,越大说明两个边界框重合区域越大,两个边界框越有可能检测到同一物体。
1.2 Fast RCNN
Fast RCNN使用VGG16作为网络的Backbone,与RCNN相比训练时间快了9倍,推理测试时间快了213倍,准确率从62%提高到66%
1.2.1 关键知识点——网络结构及特点
Fast RCNN网络结构如下图所示:
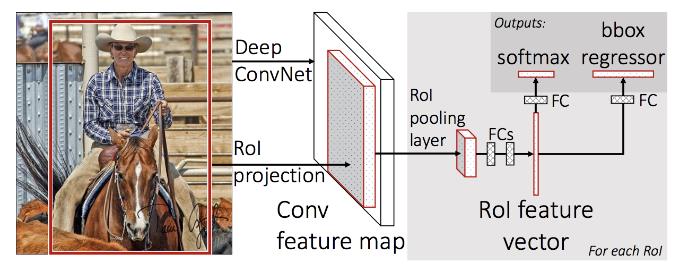
该算法主要有如下几个步骤:
- 使用Selective Search方法在图像上生成1000至2000个候选区域
该步骤与RCNN相同,在此不进行赘述。 - 将图像输入网络得到相应的特征图,将Selective Search生成的候选框投影到特征图上得到相应的特征矩阵
在RCNN中是将第一步获得的2000个候选区域缩放到同一大小后如数到特征提取网络中,而FastRCNN是将整张图像送入网络,紧接着从特征图上提取相应的候选区域,这样做的好处是避免了候选区域的特征重复计算。下面这张图就说明了RCNN和FastRCNN在这一关键步骤的不同之处
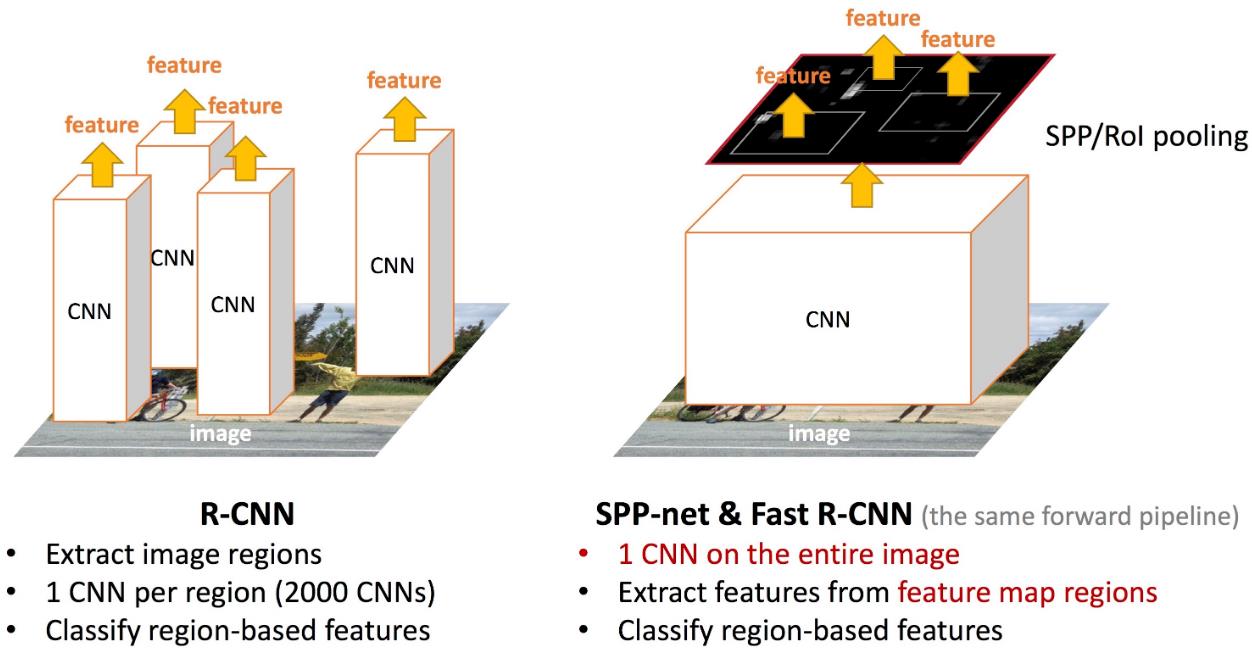
- 将每个特征矩阵通过ROI Pooling层缩放到
7
×
7
7 \\times 7
7×7大小的特征图,接着将特征图展平通过一系列全连接成得到预测结果
所谓ROI pooling就是将输出特征划分为 7 × 7 7 \\times 7 7×7的网格,每个网络输出该网格数值最大的特征值,最后无论原特征矩阵多大最终都得到一个 7 × 7 7 \\times 7 7×7大小的特征图,接下来我们看一下最后全连接层的结构,如下图所示:
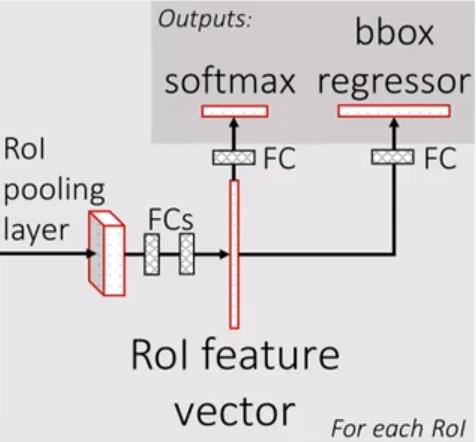
将 7 × 7 7 \\times 7 7×7大小的特征图进行展平处理后通过两个全连接层后得到ROI feature vector,接下来并联了两个全连接层,最后就进行损失计算。
1.2.1 关键知识点——目标检测多任务损失
前文提到ROI Feature Vector后面并联了两个全连接层,其中左侧全连接层对接分类器,右侧全连接层对接边界框回归器,两个不同功能的模块组成目标检测中的多任务损失,在目标检测网络中这是通用的一种损失构建方式,下面具体介绍:
- 分类器:分类器输出
N
+
1
N+1
N+1个类别的概率(其中
N
N
N为检测目标的种类,1为背景的概率),因此其对应的全连接层共
N
+
1
N+1
N+1个节点,其中
N
N
N个种类概率是通过softmax输出的,因此这
N
N
N个种类的概率和为1,因此

- 边界框回归器:边界框回归器输出对应
N
+
1
N+1
N+1个类别的候选边界框回归参数
d
x
,
d
y
,
d
w
,
d
h
d_x,d_y,d_w,d_h
dx,dy,dw,dh,因此其对应的全连接层共
(
N
+
1
)
×
4
(N+1)\\times 4
(N+1)×4个节点
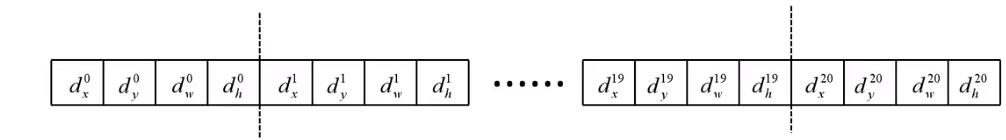
候选框相关的计算公式如下: G ^ x = P w d x ( P ) + P x \\hatG_x=P_w d_x(P)+P_x G^x=Pwdx(P)+Px G ^ y = P h d y ( P ) + P y \\hatG_y=P_h d_y(P)+P_y G^y=Phdy(P)+Py G ^ w = P w exp ( d w ( P ) ) \\hatG_w=P_w \\exp \\left(d_w(P)\\right) G^w=Pwexp(dw(P)) G ^ h = P h exp ( d h ( P ) ) \\hatG_h=P_h \\exp \\left(d_h(P)\\right) G^h=Phexp(dh(P))其中 P x , P y , P w , P h P_x, P_y, P_w, P_h Px,Py,Pw,Ph分别为候选框的中心 x , y x,y x,y坐标以及宽高, G ^ x , G ^ y , G ^ w , G ^ h \\hatG_x, \\hatG_y, \\hatG_w, \\hatG_h G^x,G^y,G^w,G^h分别为最终预测的边界框中心 x , y x,y x,y坐标以及宽高,那么 d x , d y , d w , d h d_x,d_y,d_w,d_h dx,dy,dw,dh就分别是对候选框的中心和宽高调整的参数。 - 基于以上分类器和回归器计算的多任务损失如下: L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L\\left(p, u, t^u, v\\right)= L_c l s(p, u)+ \\lambda[u \\geq 1] L_l o c\\left(t^u, v\\right) L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(t以上是关于计算机视觉算法——目标检测网络总结的主要内容,如果未能解决你的问题,请参考以下文章