python K-Means聚类算法的实现
Posted 阳光玻璃杯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python K-Means聚类算法的实现相关的知识,希望对你有一定的参考价值。
K-Means 简介
聚类算法有很多种(几十种),K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是一定要在聚类前需要手工指定要分成几类。
具体实现步骤如下:
给定n个训练样本x1,x2,x3,…,xn
kmeans算法过程描述如下所示:
1.创建k个点作为起始质心点,c1,c2,…,ck
2.重复以下过程直到收敛
遍历所有样本xi,根据距离确定每一个样本的类别。
确定类别后,计算每一个样本到各自质心的距离,然后求和。和用来和前一次计算出来的距离和比较,已确定是否收敛。
对每一个类,计算所有样本的均值并将其作为新的质心(对于点而言,就是所有x坐标的平均值作为质心的x坐标,所有y坐标的平均值作为y坐标的均值)
根据以上步骤,实现的具体效果如下:
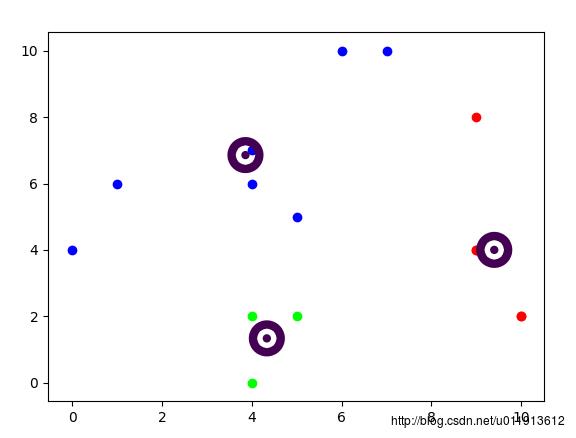
完整代码如下:
from matplotlib import pyplot
import numpy as np
#随机生成K个质心
def randomCenter(pointers,k):
indexs = np.random.random_integers(0,len(pointers)-1,k)
centers = []
for index in indexs:
centers.append(pointers[index])
return centers
#绘制最终的结果
def drawPointersAndCenters(pointers,centers):
i = 0
for classs in pointers:
cs = np.zeros(4,dtype=np.int8)
cs[i]=1
cs[3]=1
#将list转为numpy中的array,方便切片
xy = np.array(classs)
if(len(xy)>0):
pyplot.scatter(xy[:,0],xy[:,1],c=cs)
i += 1
centers = np.array(centers)
pyplot.scatter(centers[:, 0], centers[:, 1], c=[0,0,0],linewidths = 20)
pyplot.show()
#计算两个向量的距离,用的是欧几里得距离
def distEclud(vecA, vecB):
return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
#求这一组数据坐标的平均值,也就是新的质心
def getMean(data):
xMean = np.mean(data[:,0])
yMean = np.mean(data[:,1])
return [xMean,yMean]
def KMeans(pointers,centers):
diffAllNew = 100
diffAllOld = 0
afterClassfy = []
while(abs(diffAllNew - diffAllOld)>1):
#更新diffAllOld为diffAllNEw
diffAllOld = diffAllNew
#先根据质心,对所有的数据进行分类
afterClassfy = [[] for a in range(len(centers))]
for pointer in pointers:
dis = []
for center in centers:
dis.append(distEclud(pointer,center))
minDis = min(dis)
i=0
for d in dis:
if(minDis == d):
break
else:
i += 1
afterClassfy[i].append(pointer)
afterClassfy = np.array(afterClassfy)
#计算所有点到其中心距离的总的和
diffAllNews = [[] for a in range(len(centers))]
i=0
for classs in afterClassfy:
for center in centers:
if len(classs) >0:
diffAllNews[i] += distEclud(classs,center)
i+=1
diffAllNew = sum(diffAllNews)
#更新质心的位置
i=0
for classs in afterClassfy:
classs = np.array(classs)
if len(classs) > 0 :
centers[i] = getMean(classs)
i += 1
drawPointersAndCenters(afterClassfy,centers)
print(afterClassfy)
def randonGenerate15Pointer():
ponters =[np.random.random_integers(0,10,2) for a in range(15)]
np.save("data",ponters)
print(ponters)
def loadData(fileName):
return np.load(fileName)
def test():
pointers = loadData("data.npy")
centers = randomCenter(pointers,3)
print(pointers)
print(centers)
KMeans(pointers, centers)
test()
loadData装载的数据是通过randonGenerate15Pointer()方法随机生成的15个点。
以上是关于python K-Means聚类算法的实现的主要内容,如果未能解决你的问题,请参考以下文章