2.4 Tensor的存储
Posted 王小小小草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.4 Tensor的存储相关的知识,希望对你有一定的参考价值。
欢迎订阅本专栏:《PyTorch深度学习实践》
订阅地址:https://blog.csdn.net/sinat_33761963/category_9720080.html
- 第二章:认识Tensor的类型、创建、存储、api等,打好Tensor的基础,是进行PyTorch深度学习实践的重中之重的基础。
- 第三章:学习PyTorch如何读入各种外部数据
- 第四章:利用PyTorch从头到尾创建、训练、评估一个模型,理解与熟悉PyTorch实现模型的每个步骤,用到的模块与方法。
- 第五章:学习如何利用PyTorch提供的3种方法去创建各种模型结构。
- 第六章:利用PyTorch实现简单与经典的模型全过程:简单二分类、手写字体识别、词向量的实现、自编码器实现。
- 第七章利用PyTorch实现复杂模型:翻译机(nlp领域)、生成对抗网络(GAN)、强化学习(RL)、风格迁移(cv领域)。
- 第八章:PyTorch的其他高级用法:模型在不同框架之间的迁移、可视化、多个GPU并行计算。
2.4.1 Storage
tensor中的值是存储在连续的内存块中的,由torch.Storage实例管理着。一个storage即是一个一维的向量。
多个不同的tensor可以存储在同一个storage中,只是对数据的索引不同,入下图,一个2行3列的tensor和3行2列的tensor的值都存储在同一个storage中,其中storage中索引为0位置存储着两个tensor的第一行第一列的值4。正因如此,当从一个已有的Tensor创建一个新的tensor时总能很快,因为其在内存中只会创建一次。
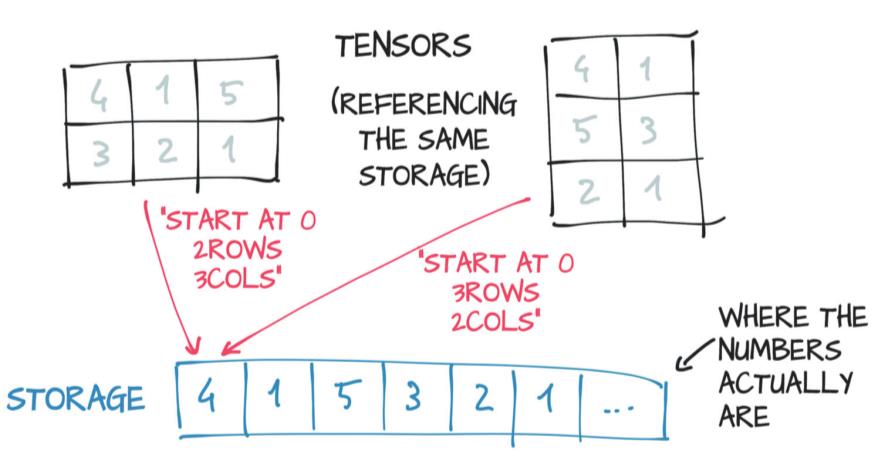
现在来看看可以用哪些api来操作storage:
获取tensor的storage:
import torch
# 3*2的tensor
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
points.storage()
1.0
4.0
2.0
1.0
3.0
5.0
[torch.FloatStorage of size 6]
对storage进行索引:
points_storage = points.storage()
points_storage[0]
1.0
注意:storage永远是一维的数组,任何维度的tensor都存储在一维的storage中。
更改storage的值:
tensor的值存储在storage中,若改变了storage的值,势必会改变tensor的值。
points_storage = points.storage()
points_storage[0] = 2.0
print(points)
tensor([[2., 4.],
[2., 1.],
[3., 5.]])
可见,改变了points的storage中索引为0的值,同时也改变了points中第一行第一列的值。
现在,你知道了tensor的值时存储在storage中,但你肯定会疑惑,我们如何知道在tensor中的某个值,存储在storage的什么位置,也就是说如何知道storage时如何存储tensor的。Pytorch中提供了3个信息来连接tensor与storage: size, storage offset, strides。下面三小节会依次介绍它们。
2.4.2 size
size(在numpy中叫shape) 是一个元组,显示tensor中每个维度的元素数量。这个大家自然是不陌生,如:
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
print(points.size()) # 打印size
torch.Size([3, 2])
2.4.3 storage offset
storage offset是指tensor的第一个元素在storage中的位置,再来看之前的例子
# 3*2的tensor
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
points.storage()
1.0
4.0
2.0
1.0
3.0
5.0
[torch.FloatStorage of size 6]
现在我们取出points中的一维,生成一个新的tensor, 注意新的tensor与points仍然是同一个storage.
points_second = points[1]
print(points_second.storage_offset())
2
points_second应为:tensor([2., 1.]), 它的第一个元素在storage中位置为索引为2的地方。
2.4.4 stride
首先明确strides是一个N元组。它表示步长,即Tensor中的某个元素,需要在storage中跳过多少数量的元素才能到达tensor中每个维度中的下一个元素。说起来太拗口,来看下面这个例子吧:
左边是一个tensor, 3行3列,size=(3,3), 总共由两个维度,每个维度中的元素数目都是3个;
下面的蓝色一维数组是它的storage;
该tensor的第一个元素5在storage中的索引是1,因此offset=1;
先在来看strides, 以tensor中的其中一个元素(第一行第一列的5)为例,它的索引维(0,0),在第1维中,它的下一个元素(0,1)为1,在storage中就存在5的后面一个位置,因此它在第1维中到达下一个元素的步长为1;在第0维中,5的下一个元素(1,0)是1,在storage中存储在离5有3个步长的地方;因此该tensor的strides为(1,3)
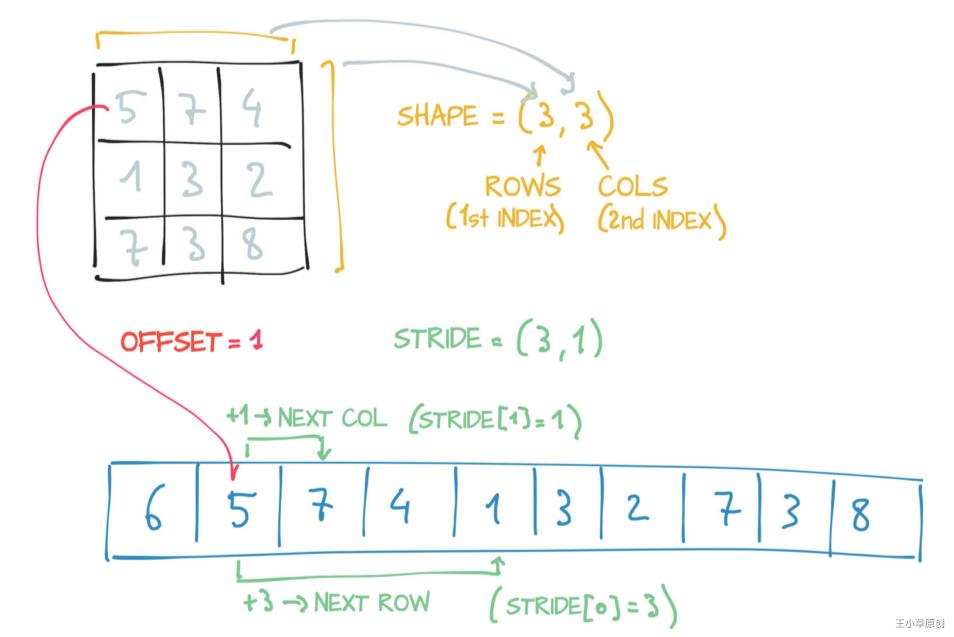
将上述例子用代码表示:
points = torch.Tensor([[5,7,4],[1,3,2],[7,3,8]])
points.stride()
(3, 1)
综上所述,可以根据offset和stride来从storage的元素中获取tensor中的元素,其公式如下:
storage_offset + stride[0] * i + stride[1] * j
2.4.5 获取子tensor
因为tensor和storage的关系,使得一些操作变得轻而易举,因为不需要再重新分配内存。像这样的操作典型的如“获取子tensor”和“转置Tensor”,分别在这节和下一节来详细讲一讲,并看看stride, offset等的变化。
如下例子, 创建一个tensor名为points, 再以该points创建出其的子tensor,此时,这两个tensor是同一个storage, 只是stride, offset, size不同, 请品味:
# 创建一个3*2的tensor
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
print(points.size()) # (3,2)
print(points.stride()) # (1,2)
print(points.storage_offset()) # 0
# 创建Points的子tensor
points_second = points[1]
print(points_second.size()) # 2
print(points_second.stride()) # (1,)
print(points_second.storage_offset()) # 2
torch.Size([3, 2])
(2, 1)
0
torch.Size([2])
(1,)
2
若更改子tensor的值,则原tensor的值也会随之改变
# 更改子tensor的值
points_second[0] = 10.0
print(points) # 原tensor的值也会随之改变
tensor([[ 1., 4.],
[10., 1.],
[ 3., 5.]])
但现实中,我们往往不希望原tensor跟着子tensor变动,此时可以使用.clone()
second_points = points[1].clone()
2.4.6 转置tensor
转置前后的Tensor元素的值没有变化,只是变化了元素的位置,因此其stride, offset, size也随之而变。
# 创建一个3*2的tensor
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
print(points.size()) # (3,2)
print(points.stride()) # (1,2)
print(points.storage_offset()) # 0
# 创建Points的子tensor
points_t = points.t()
id(points.storage()) == id(points_t.storage()) # True, 转置后storage同一个
print(points_t.size()) # (2,3)
print(points_t.stride()) # (2,1)
print(points_t.storage_offset()) # 0
torch.Size([3, 2])
(2, 1)
0
torch.Size([2, 3])
(1, 2)
0
下图可帮助理解:
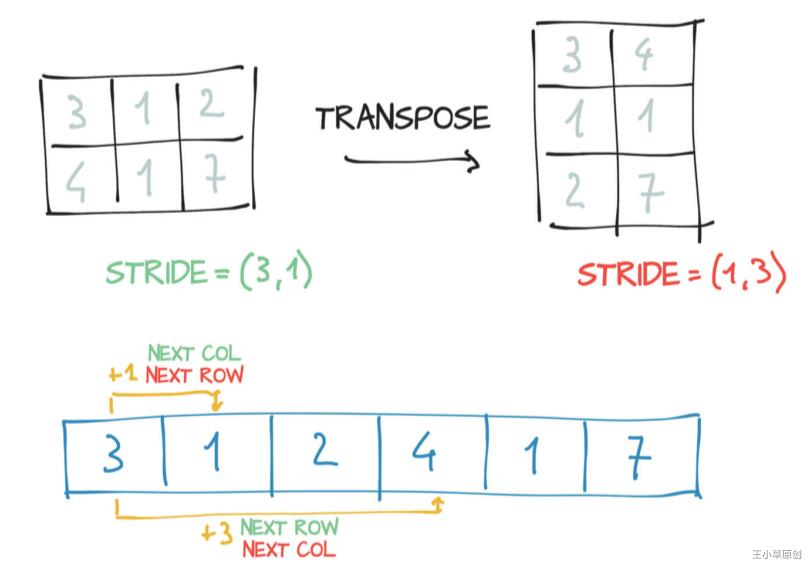
上面是对于二维矩阵的转置操作,对于多维数组,同样也是这个例,请看以下例子:
some_tensor = torch.ones(3,4,5) # 创建3*4*5的tensor
print(some_tensor.size()) # (3,4,5)
print(some_tensor.stride()) # (20, 5, 1)
some_tensor_t = some_tensor.transpose(0,2) # 将第0维于第2维互换
print(some_tensor_t.size()) # (5,4,3)
print(some_tensor_t.stride()) # (1, 5, 20)
torch.Size([3, 4, 5])
(20, 5, 1)
torch.Size([5, 4, 3])
(1, 5, 20)
2.4.7 连续型Tensor
如果一个Tensor在storage中的存储顺序是从左倒右地存储它的元素,比如二位矩阵,是从左到右从上到下一行一行存储的,就称该Tensor为contiguous tensor。contiguous tensor使得有序高效访问元素,而无需根据太大的步长进行跳跃获取。
这么说,如果对一个tensor进行转置后,那么对于转置后的tensor就不是contiguous tensor了, 可以通过.is_contiguous()来判断。
如果想要tensor变得contiguous, 可以使用.contiguous()来创建一个新的内容没有改变的contiguous tensor:
# 创建一个3*2的tensor
points = torch.tensor([[1.0, 4.0],[2.0, 1.0],[3.0, 5.0]])
print(points.size()) # (3,2)
print(points.stride()) # (1,2)
print(points.storage_offset()) # 0
# 创建Points的子tensor
points_t_c = points.t().contiguous()
torch.Size([3, 2])
(2, 1)
0
2.4.8 总结
本章讲了tensor的存储,处了本节的总结,总共有7个小节,可以分成3部分去学习:
第1节–讲了tensor是存储在storage中的
第2、3、4节–讲述了tensor和storage之间的联系,分别是通过3个信息size, stride, offset来对接两者的关系
第5、6、7节–讲述了由于tensor和storage这个的关系而让一些操作变得简单,如获取子tensor, 转置tensor, 并叙述可以通过.contiguous()来创建连续tensor。
这一节的内容在实际工作中不会太多用到,但掌握tensor的存储可以有助于大家理解tensor的运作原理,并更好地撰写高效的代码。
以上是关于2.4 Tensor的存储的主要内容,如果未能解决你的问题,请参考以下文章