整理:Redis中的lru算法实现
Posted 阿征new
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整理:Redis中的lru算法实现相关的知识,希望对你有一定的参考价值。
Redis中的lru算法实现
发布于 2019-02-18
目录
mysql innodb的buffer pool使用了一种改进的lru算法:

首发于 https://segmentfault.com/a/11...
LRU是什么
lru(least recently used)是一种缓存置换算法。即在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉。因为缓存是否可能被访问到没法做预测,所以基于如下假设实现该算法:
如果一个key经常被访问,那么该key的idle time应该是最小的。
(但这个假设也是基于概率,并不是充要条件,很明显,idle time最小的,甚至都不一定会被再次访问到)
这也就是lru的实现思路。首先实现一个双向链表,每次有一个key被访问之后,就把被访问的key放到链表的头部。当缓存不够时,直接从尾部逐个摘除。
在这种假设下的实现方法很明显会有一个问题,例如mysql中执行如下一条语句:
select * from table_a;如果table_a中有大量数据并且读取之后不会继续使用,则lru头部会被大量的table_a中的数据占据。这样会造成热点数据被逐出缓存从而导致大量的磁盘io
mysql innodb的buffer pool使用了一种改进的lru算法:
大意是将lru链表分成两部分,一部分为newlist,一部分为oldlist,
newlist是头部热点数据,oldlist是非热点数据,oldlist默认占整个list长度的3/8.
当初次加载一个page的时候,会首先放入oldlist的头部,再次访问时才会移动到newlist.
具体参考如下文章:MySQL官方文档:https://dev.mysql.com/doc/ref...
而Redis整体上是一个大的dict,如果实现一个双向链表需要在每个key上首先增加两个指针,需要16个字节,并且额外需要一个list结构体去存储该双向链表的头尾节点信息。Redis作者认为这样实现不仅内存占用太大,而且可能导致性能降低。他认为既然lru本来就是基于假设做出的算法,为什么不能模拟实现一个lru呢。
Redis中的实现
首先Redis并没有使用双向链表实现一个lru算法。具体实现方法接下来逐步介绍
redisObj结构体(保存lru时间戳)
首先看一下robj结构体(Redis整体上是一个大的dict,key是一个string,而value都会保存为一个robj)
typedef struct redisObject
...
unsigned lru:LRU_BITS; //LRU_BITS为24bit
...
robj;
我们看到每个robj中都有一个24bit长度的lru字段,lru字段里边保存的是一个时间戳。看下边的代码
robj *lookupKey(redisDb *db, robj *key, int flags)
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) //如果配置的是lfu方式,则更新lfu
updateLFU(val);
else
val->lru = LRU_CLOCK();//否则按lru方式更新
...
在Redis的dict中每次按key获取一个值的时候,都会调用lookupKey函数,如果配置使用了lru模式,该函数会更新value中的lru字段为当前秒级别的时间戳(lfu方式后文再描述)。
那么,虽然记录了每个value的时间戳,但是淘汰时总不能挨个遍历dict中的所有槽,逐个比较lru大小吧。
Redis2.8之前的简单版
Redis初始的实现算法很简单,随机从dict中取出五个key,淘汰一个lru字段值最小的。(随机选取的key是个可配置的参数maxmemory-samples,默认值为5).
Redis3.0 改进版(pool)
在3.0的时候,又改进了一版算法
首先第一次随机选取的key都会放入一个pool中(pool的大小为16),pool中的key是按lru大小顺序排列的。
接下来每次随机选取的keylru值必须小于pool中最小的lru才会继续放入,直到将pool放满。
放满之后,每次如果有新的key需要放入,需要将pool中lru最大的一个key取出。
淘汰的时候,直接从pool中选取一个lru最小的值然后将其淘汰。
总结一下:这个池,基本上维护了一个局部性的LRU池:
1. 随机挑选key,作为局部性LRU池
2. 入池要求是池内最久没使用的key
3. 池子满了把最新的key挤出去
4. 淘汰时,从池子里挑一个最久没使用的key,删除
测试淘汰效果
我们知道Redis执行命令时首先会调用processCommand函数,在processCommand中会进行key的淘汰,代码如下:
int processCommmand()
...
if (server.maxmemory && !server.lua_timedout)
int out_of_memory = freeMemoryIfNeeded() == C_ERR;//如果开启了maxmemory的限制,则会调用freeMemoryIfNeeded()函数,该函数中进行缓存的淘汰
...
可以看到,lru本身是基于概率的猜测,这个算法也是基于概率的猜测,也就是作者说的模拟lru.那么效果如何呢?作者做了个实验,如下图所示
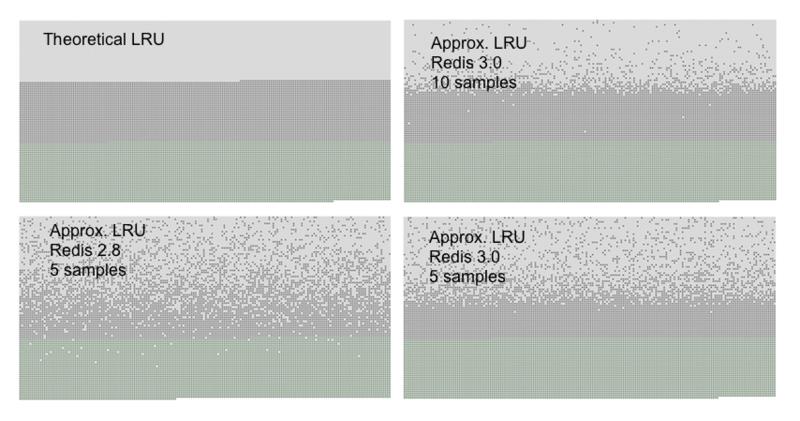
首先加入n个key并顺序访问这n个key,之后加入n/2个key(假设redis中只能保存n个key,于是会有n/2个key被逐出).上图中浅灰色为被逐出的key,淡蓝色是新增加的key,灰色的为最近被访问的key(即不会被lru逐出的key)
左上图为理想中的lru算法,新增加的key和最近被访问的key都不应该被逐出。
可以看到,Redis2.8当每次随机采样5个key时,新增加的key和最近访问的key都有一定概率被逐出【淘汰结果不理想】
Redis3.0增加了pool后效果好一些(右下角的图)。当Redis3.0增加了pool并且将采样key增加到10个后,基本等同于理想中的lru(虽然还是有一点差距) 【淘汰结果比较符合预期】
如果继续增加采样的key或者pool的大小,作者发现还能进一步优化lru算法,于是作者开始转换思路。
LFU算法
上文介绍了实现lru的一种思路,即如果一个key经常被访问,那么该key的idle time应该是最小的。
那么能不能换一种思路呢。如果能够记录一个key被访问的次数,那么经常被访问的key最有可能再次被访问到。
这也就是lfu(least frequently used),访问次数最少的最应该被逐出。
lfu的代码如下:
void updateLFU(robj *val)
unsigned long counter = LFUDecrAndReturn(val);//首先计算是否需要将counter衰减
counter = LFULogIncr(counter);//根据上述返回的counter计算新的counter
val->lru = (LFUGetTimeInMinutes()<<8) | counter; //robj中的lru字段只有24bits,lfu复用该字段。高16位存储一个分钟数级别的时间戳,低8位存储访问计数
unsigned long LFUDecrAndReturn(robj *o)
unsigned long ldt = o->lru >> 8;//原来保存的时间戳
unsigned long counter = o->lru & 255; //原来保存的counter
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
//server.lfu_decay_time默认为1,每经过一分钟counter衰减1
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;//如果需要衰减,则计算衰减后的值
return counter;
uint8_t LFULogIncr(uint8_t counter)
if (counter == 255) return 255;//counter最大只能存储到255,到达后不再增加
double r = (double)rand()/RAND_MAX;//算一个随机的小数值
double baseval = counter - LFU_INIT_VAL;//新加入的key初始counter设置为LFU_INIT_VAL,为5.不设置为0的原因是防止直接被逐出
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);//server.lfu_log_facotr默认为10
if (r < p) counter++;//可以看到,counter越大,则p越小,随机值r小于p的概率就越小。换言之,counter增加起来会越来越缓慢
return counter;
unsigned long LFUGetTimeInMinutes(void)
return (server.unixtime/60) & 65535;//获取分钟级别的时间戳
lfu本质上是一个概率计数器,称为morris counter.随着访问次数的增加,counter的增加会越来越缓慢。如下是访问次数与counter值之间的关系
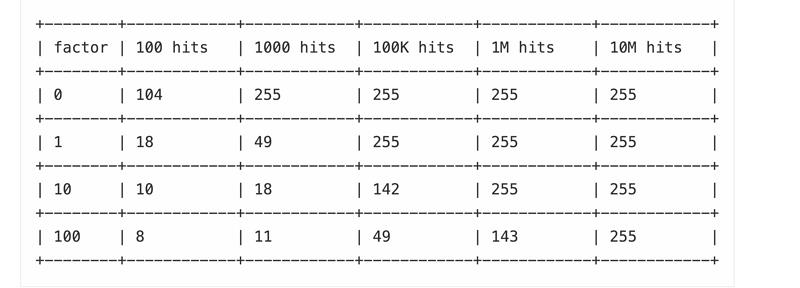
factor即server.lfu_log_facotr配置值,默认为10.可以看到,一个key访问一千万次以后counter值才会到达255.factor值越小, counter越灵敏【1、访问的次数越多,counter越大】不过随着访问次数的增加,counter的增加会越来越缓慢
除了计数,给时间也增加了一定的权重:
lfu随着分钟数对counter做衰减是基于一个原理:过去被大量访问的key不一定现在仍然会被访问。
【2、同样维护一个访问时间戳:每分钟对counter减一】淘汰时计算与当前时间戳的分钟差
淘汰时就很简单了,仍然是一个pool,随机选取10个key,counter最小的被淘汰
【3、淘汰:一样是pool随机挑10个可以,淘汰counter最小的key】
LFU 比 LRU 的预测准确率略微高一些!!!
LRU :5%-5.5%之间的miss概率
LFU:%5左右的miss率
算法验证 LRU vs LFU
redis-cli提供了一个参数,可以验证lru算法的效率。主要是通过验证hits/miss的比率,来判断淘汰算法是否有效。命中比率高说明确实淘汰了不会被经常访问的key.具体做法如下:
配置redis lru算法为 allkeys-lru
test ~/redis-5.0.0$./src/redis-cli -p 6380
127.0.0.1:6380> config set maxmemory 50m //设置redis最大使用50M内存
OK
127.0.0.1:6380> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
127.0.0.1:6380> config set maxmemory-policy allkeys-lru//设置lru算法为allkeys-lru
OK执行redis-cli --lru-test验证命中率
...
# Memory
used_memory:50001216
...
evicted_keys:115092
...查看lru-test的输出
131250 Gets/sec | Hits: 124113 (94.56%) | Misses: 7137 (5.44%)
132250 Gets/sec | Hits: 125091 (94.59%) | Misses: 7159 (5.41%)
131250 Gets/sec | Hits: 124027 (94.50%) | Misses: 7223 (5.50%)
133000 Gets/sec | Hits: 125855 (94.63%) | Misses: 7145 (5.37%)
136250 Gets/sec | Hits: 128882 (94.59%) | Misses: 7368 (5.41%)
139750 Gets/sec | Hits: 132231 (94.62%) | Misses: 7519 (5.38%)
136000 Gets/sec | Hits: 128702 (94.63%) | Misses: 7298 (5.37%)
134500 Gets/sec | Hits: 127374 (94.70%) | Misses: 7126 (5.30%)
134750 Gets/sec | Hits: 127427 (94.57%) | Misses: 7323 (5.43%)
134250 Gets/sec | Hits: 127004 (94.60%) | Misses: 7246 (5.40%)
138500 Gets/sec | Hits: 131019 (94.60%) | Misses: 7481 (5.40%)
130000 Gets/sec | Hits: 122918 (94.55%) | Misses: 7082 (5.45%)
126500 Gets/sec | Hits: 119646 (94.58%) | Misses: 6854 (5.42%)
132750 Gets/sec | Hits: 125672 (94.67%) | Misses: 7078 (5.33%)
136000 Gets/sec | Hits: 128563 (94.53%) | Misses: 7437 (5.47%)
132500 Gets/sec | Hits: 125450 (94.68%) | Misses: 7050 (5.32%)
132250 Gets/sec | Hits: 125234 (94.69%) | Misses: 7016 (5.31%)
133000 Gets/sec | Hits: 125761 (94.56%) | Misses: 7239 (5.44%)
134750 Gets/sec | Hits: 127431 (94.57%) | Misses: 7319 (5.43%)
130750 Gets/sec | Hits: 123707 (94.61%) | Misses: 7043 (5.39%)
133500 Gets/sec | Hits: 126195 (94.53%) | Misses: 7305 (5.47%)大概有5%-5.5%之间的miss概率。我们将lru策略切换为allkeys-lfu,再次实验
结果如下:
131250 Gets/sec | Hits: 124480 (94.84%) | Misses: 6770 (5.16%)
134750 Gets/sec | Hits: 127926 (94.94%) | Misses: 6824 (5.06%)
130000 Gets/sec | Hits: 123458 (94.97%) | Misses: 6542 (5.03%)
127750 Gets/sec | Hits: 121231 (94.90%) | Misses: 6519 (5.10%)
130500 Gets/sec | Hits: 123958 (94.99%) | Misses: 6542 (5.01%)
130500 Gets/sec | Hits: 123935 (94.97%) | Misses: 6565 (5.03%)
131250 Gets/sec | Hits: 124622 (94.95%) | Misses: 6628 (5.05%)
131250 Gets/sec | Hits: 124618 (94.95%) | Misses: 6632 (5.05%)
128000 Gets/sec | Hits: 121315 (94.78%) | Misses: 6685 (5.22%)
129000 Gets/sec | Hits: 122585 (95.03%) | Misses: 6415 (4.97%)
132000 Gets/sec | Hits: 125277 (94.91%) | Misses: 6723 (5.09%)
134000 Gets/sec | Hits: 127329 (95.02%) | Misses: 6671 (4.98%)
131750 Gets/sec | Hits: 125258 (95.07%) | Misses: 6492 (4.93%)
136000 Gets/sec | Hits: 129207 (95.01%) | Misses: 6793 (4.99%)
135500 Gets/sec | Hits: 128659 (94.95%) | Misses: 6841 (5.05%)
133750 Gets/sec | Hits: 126995 (94.95%) | Misses: 6755 (5.05%)
131250 Gets/sec | Hits: 124680 (94.99%) | Misses: 6570 (5.01%)
129750 Gets/sec | Hits: 123408 (95.11%) | Misses: 6342 (4.89%)
130500 Gets/sec | Hits: 124043 (95.05%) | Misses: 6457 (4.95%)%5左右的miss率,在这个测试下,lfu比lru的预测准确率略微高一些。
在实际生产环境中,不同的redis访问模式需要配置不同的lru策略, 然后可以通过lru test工具验证效果。
参考链接
2.https://redis.io/topics/lru-c...
以上是关于整理:Redis中的lru算法实现的主要内容,如果未能解决你的问题,请参考以下文章