hadoop MapReduce运行机制
Posted node2017
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop MapReduce运行机制相关的知识,希望对你有一定的参考价值。
MapReduce是hadoop的计算框架,用于大规模数据集的并行运算。
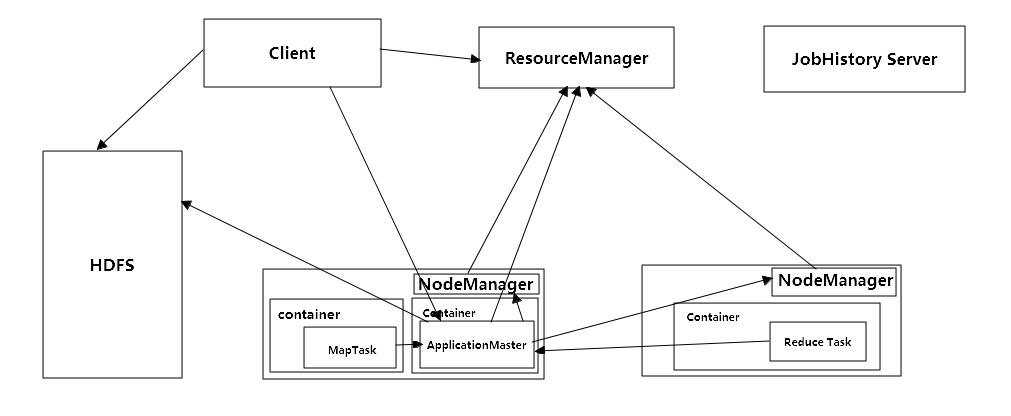
俩个主要的节点,ResourceManager和NodeManager。
ResourceManager:资源的管理者和协调者,使用Container来管理集群资源,container包括一些io,内存等资源。ResourceManager在管理和协调上主要由俩个组件构成,Scheduler和ApplicationsManager(AsM)。Scheduler根据资源基础状况,调度资源处理任务,不监视和跟踪应用的状态。ApplicationsManager负责客户端提交的任务,向Scheduler申请container,并通知NodeManger运行container来启动ApplicationMaster。
ResourceManager主要的功能如下:
1.负责资源调度,使用Scheduler统一,全局规划资源调度
2.监控资源,NodeManager定时会向Scheduler汇报本地资源使用情况
3.任务提交,客户端向ApplicationsManager提交一个任务,过程如下:
a.client向AsM提交一个任务申请,内容包括资源位置,任务的描述信息等,并获得AsM提供的applicationIDclient
b.client将application任务申请信息还有任务jar包,上传到hdfs
c.AsM向Scheduler申请资源,协商一个container,并通知NodeManager运行container用来启动ApplicationMaster
NodeManager:NodeManager会定时,周期性的向RM Scheduler发送本地资源状态信息,设置一些必要的环境还有将任务的jar包还有任务的必要的信息下载到本地供ApplicationMaster使用,等所有准备工作完成之后,运行container,启动ApplicationMaster。
MapReduce执行任务过程
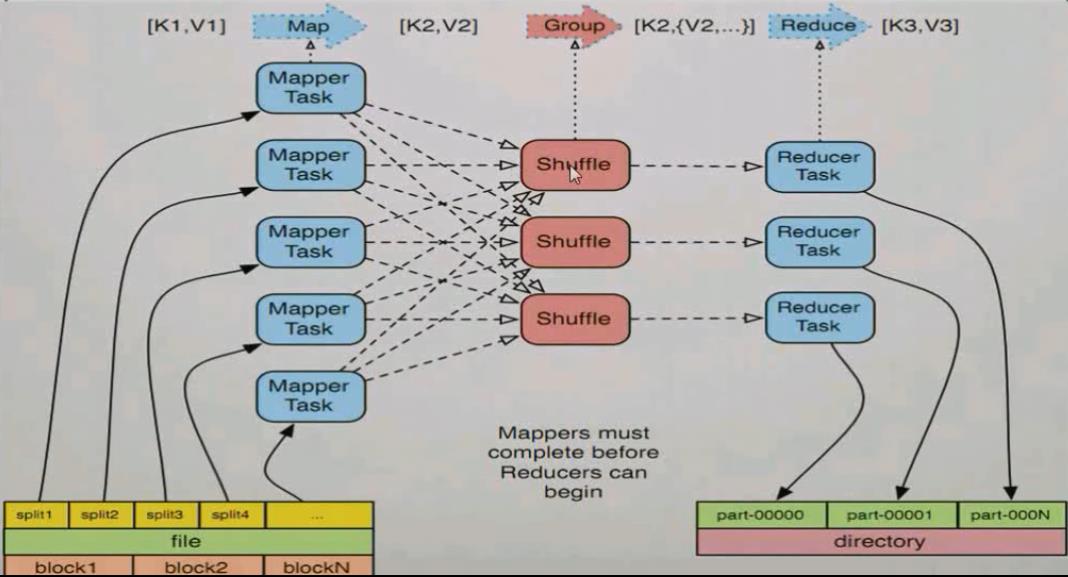
1.获取hdfs的输入资源,RM将资源进行逻辑切片作为输入切片(InputSplit),InputSplit包括文件的path和hosts以及长度
2.RM根据InputSplit数量启动相同数量的MapperTask,在默认设置下,资源的InputSplit的数量和资源的block数量一致
3.Map任务处理
a.读取输入文件的内容,解析成key和value,key的值为文件内容的偏移量,value为具体的内容。
b.写自己的逻辑,对输入的key和value进行处理,转化成新的key和value输出
4.Group任务处理,对map任务输出的key和value进行分区,排序,分组,合并处理
5.Reduce处理
a.对Group任务输出的key和value,按照不同的分区通过网络copy到不同节点进行处理
b.对多个Map任务输入的key和value进行分区和并,并写自己的逻辑,对输入的key和value进行处理,形成新的key和value
c.把reduce结果进行输入,并放到hdfs中。
以上是关于hadoop MapReduce运行机制的主要内容,如果未能解决你的问题,请参考以下文章