机器学习-临近取样(K-Nearest Nerghbor)KNN算法
Posted YEN_csdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-临近取样(K-Nearest Nerghbor)KNN算法相关的知识,希望对你有一定的参考价值。
学习彭亮《深度学习基础介绍:机器学习》课程
最邻近规则分类(K-Nearest Nerghbor),KNN算法概念
是分类(classification)算法
步骤
- 为了判断未知实例的类别,以所有已知实例的类别作为参考
- 选取参数K,选取它最近的已知实例进行归类,已知实例选择K个,K值一般不会太大,一般:1,3,5,7这样的奇数(因为要少数服从多数的投票),看哪个精确度最高
- 计算未知实例与已知实例的距离
- 选择K个最近的距离,把所有距离都算出来取最小的三个,看他们属于哪一类
- 根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
细节
关于K值
关于距离的衡量方法
- Euclidean Distance,即平面上两个点的距离(可推广到多维)
- 余弦值(cos)
- 相关度(correlation)
- 曼哈顿距离(Manhattan distance)
实例计算
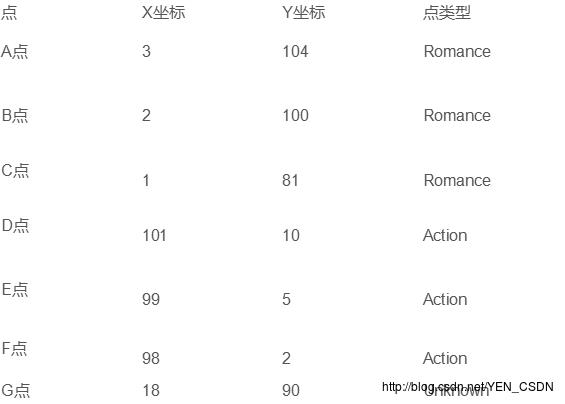
需要通过Euclidean Distance计算出G到A的距离,G到B的距离…G到F的距离,即G到每一个点的距离
# 定义计算距离的函数
def computeEuclideanDistance(x1,y1,x2,y2):
d=math.sqrt(math.pow(x1-x2,2)+math.pow(y1-y2,2))
return d
d_ag=computeEuclideanDistance(3,104,18,90) #AG的距离
print("d_ag:",d_ag)
d_bg=computeEuclideanDistance(2,100,18,90) #BG的距离
print("d_bg:",d_bg)
d_cg=computeEuclideanDistance(1,81,18,90) #CG的距离
print("d_cg:",d_cg)
d_dg=computeEuclideanDistance(101,10,18,90) #DG的距离
print("d_dg:",d_dg)
d_eg=computeEuclideanDistance(99,5,18,90) #EG的距离
print("d_eg:",d_eg)
d_fg=computeEuclideanDistance(98,2,18,90) #FG的距离
print("d_fg:",d_fg)
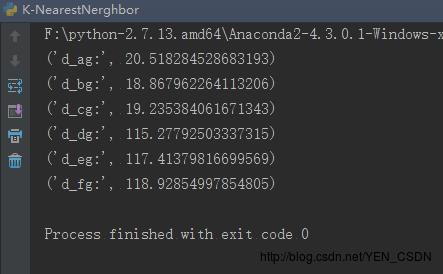
可见与ABC三点的距离最近,所以G应该和ABC归为一类
算法优缺点
优点:
- 简单
- 易于理解
- 通过对K的选择可具备丢噪音数据的健壮性
缺点:
- 需要大量存储空间存储已知实例,因为需要比较距离
- 算法复杂度高
- 当样本分布不平衡时,比如其中一类样本实例数量过大,性地 实例容易直接被归为这个主导样本,因为这类样本实例数量过大,但这个新的未知实例实际并未接近目标样本
改进版本
考虑距离,根据距离加权重,eg:1/d
算法应用
#coding=utf-8
# @Author: yangenneng
# @Time: 2018-01-10 14:53
# @Abstract:
# 导入包: from 包 import 模块
from sklearn import neighbors
from sklearn import datasets
# 调用KNN分类器
knn=neighbors.KNeighborsClassifier()
# 复制变量 load_iris()会返回一个数据库,在datasets的iris里
iris=datasets.load_iris()
print iris
# 模型建立,装配数据,传入特征值150*4的矩阵,传如一维列向量
knn.fit(iris.data,iris.target)
#进行预测,根据 萼片长度、宽度 花片长度、宽度
predictedLable=knn.predict([[0.1,0.2,0.3,0.4]])
print predictedLable
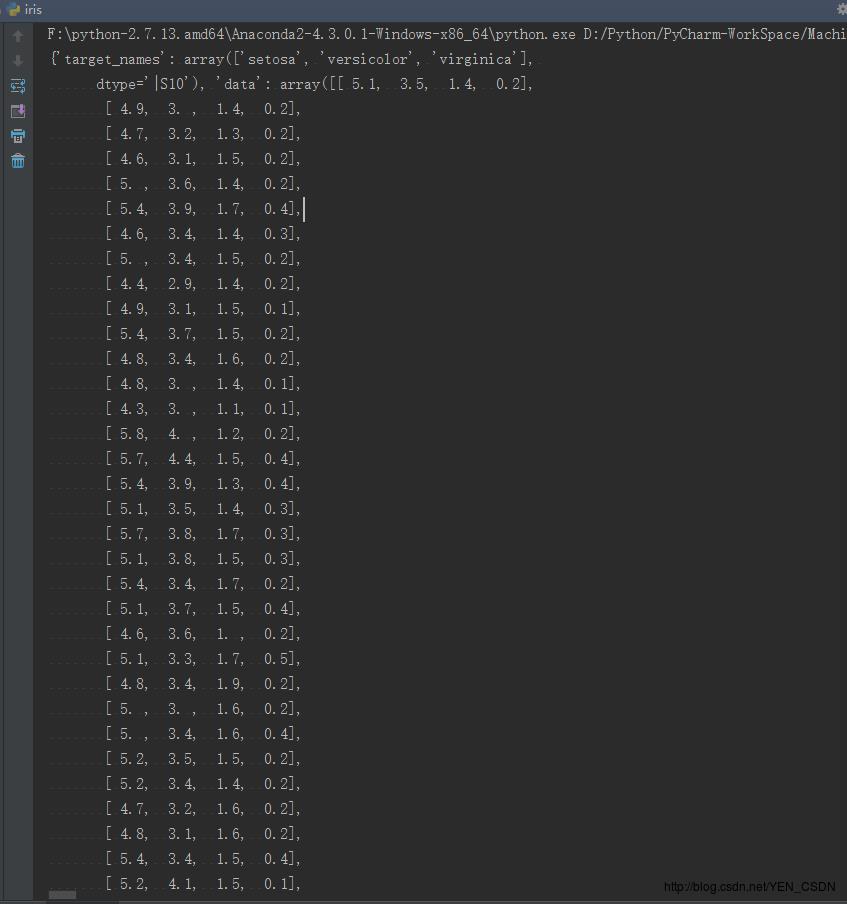
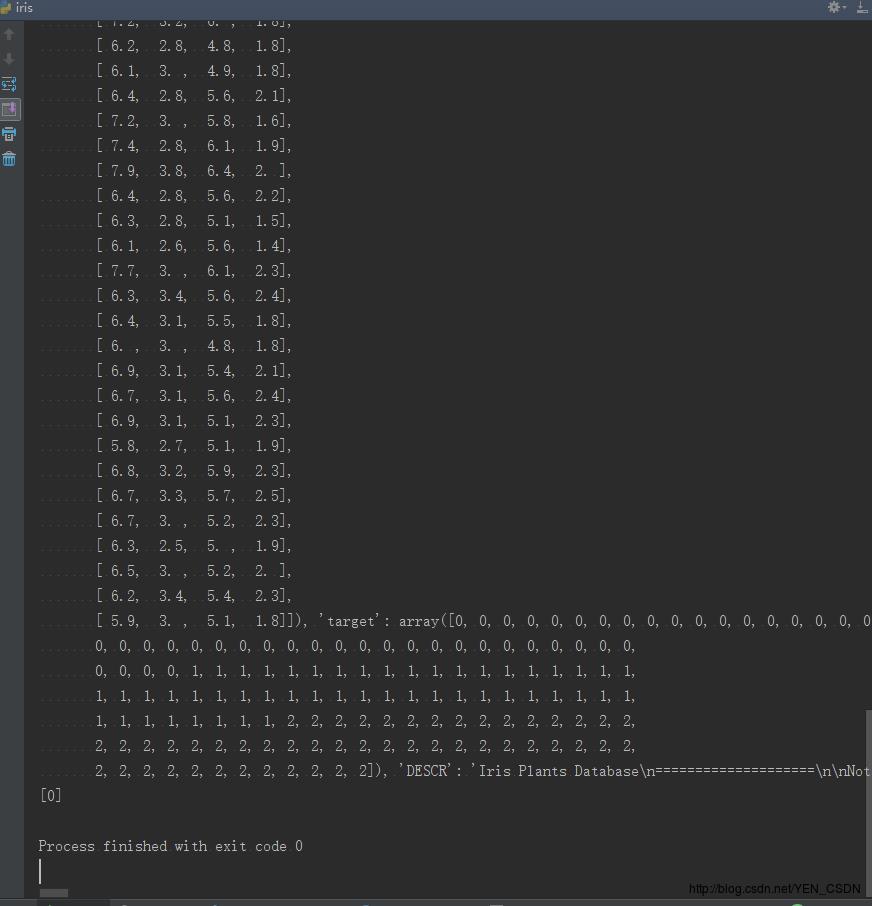
是一个大的字典:前半部分是key为taget_name, value为花的特征值;后半部分是key为target,value为目标,是一个一维列向量。
即:
前半部分是一个大的矩阵(150行*4列),包含了特征值,每一行四列(150行):
后半部分是分类,三种花的类型,转为整型:0 1 2
预测出属于第一类花:predictedLable=[0]
自己编程实现KNN算法,不调用KNN库
数据:
#coding=utf-8
# @Author: yangenneng
# @Time: 2018-01-10 15:17
# @Abstract:自己实现KNN算法
import csv
import random
import math
import operator
# 加载数据集
# 参数:
# filename 数据集.txt文件
# split 把一部分数据集作为训练数据集,用来训练产生模型;另一部分用来测试,看每一个实例预测与实际归类的比较,以split为分界线分为两部分
# trainingSet 数据集.txt分出来的训练数据集
# testSet 数据集.txt分出来的测试数据集
def loadDataSet(filename,split,trainingSet=[],testSet=[]):
# 打开文件 装载为csvfile,即以逗号分隔
with open(filename,'rb') as csvfile:
# 读取所有行
lines=csv.reader(csvfile)
# 所有行转化为list形式
dataset=list(lines)
# 把数据集.txt文件分隔为两部分:如果此次产生的随机数小于split就加入训练集,否则加入测试集
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y]=float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
# 计算距离:Eulidean Distance(每个点可以多维度)
# 参数:
# instance1 实例1
# instance2 实例2
# length 实例维度
def eulideanDistance(instance1,instance2,length):
distance=0
# 每一维进行差运算
for x in range(length):
distance += pow((instance1[x]-instance2[x]),2)
return math.sqrt(distance)
# 返回最近的K个临近点
# 参数:
# trainningSet 训练数据集
# testInstance 测试数据集的一个实例
# k 返回K个最近的点
def getNeighbors(trainningSet,testInstance,k):
# 装所有的距离
distances=[]
# 测试实例的维度
length=len(testInstance)-1
# 训练集中的每一个数到测试集的距离
for x in range(len(trainningSet)):
dist=eulideanDistance(testInstance,trainningSet[x],length)
distances.append((trainningSet[x],dist))
# 距离排序
distances.sort(key=operator.itemgetter(1))
# 取前k个距离
neighbors=[]
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
# 根据返回的临距根据少数服从多数的投票判定要预测的实例归为哪一类
# 参数:
# neighbors 测试集中最近的前k个距离
def getResponse(neighbors):
classvotes=
# 看每一个邻距属于哪个分类
for x in range(len(neighbors)):
response=neighbors[x][-1];
if response in classvotes:
classvotes[response]+=1
else:
classvotes[response]=1
# 把每一类投票个数从大到小排列
sortVotes=sorted(classvotes.iteritems(),key=operator.itemgetter(1),reverse=True)
# 返回第一个,即投票最多的类别
return sortVotes[0][0]
# 判断预测出的所有值与它实际的值比较准确率是多少
# 参数:
# testSet 测试数据集
# predictions 测试数据集预测出的分类
def getAccuracy(testSet,predictions):
correct=0
# 和实际的分类比较,看预测正确的有几个,即看精确率如何
for x in range(len(testSet)):
# [-1]指最后一列的值,Python的特殊语法
# 判断预测与实际是否正确
if testSet[x][-1]==predictions[x]:
correct+=1
# 计算精确率 预测对的/总的 *100.0%
return (correct/float(len(testSet)))*100.0
# 主函数
def main():
# 两个空的训练集 测试集
trainingSet=[]
testSet=[]
split=0.67 #取2/3的做训练集 取1/3做测试集
# 加载数据 r表示后面的字符串不做特殊转化
loadDataSet(r'D:\\Python\\PyCharm-WorkSpace\\MachineLearningDemo\\K-NearestNerghbor\\data\\irisdata.txt',split,trainingSet,testSet)
print "trainingSet:"+repr(len(trainingSet))
print "testSet:"+repr(len(testSet))
# 存储预测来的类别得值
predictions=[]
k=3
for x in range(len(testSet)):
# 取最近3个邻距
neighbors=getNeighbors(trainingSet , testSet[x] , k)
# 归类得志
result=getResponse(neighbors)
# 加入归类
predictions.append(result)
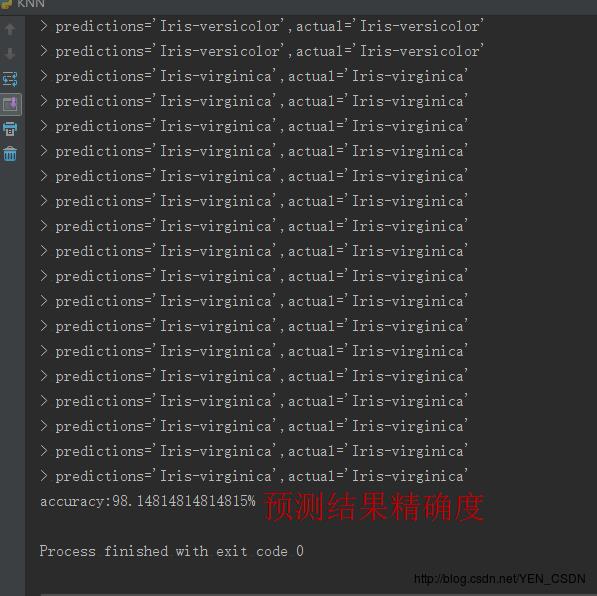
print ('> predictions='+repr(result)+',actual='+repr(testSet[x][-1]))
# 计算精确度
accuracy = getAccuracy(testSet , predictions)
print ('accuracy:'+repr(accuracy)+'%')
main()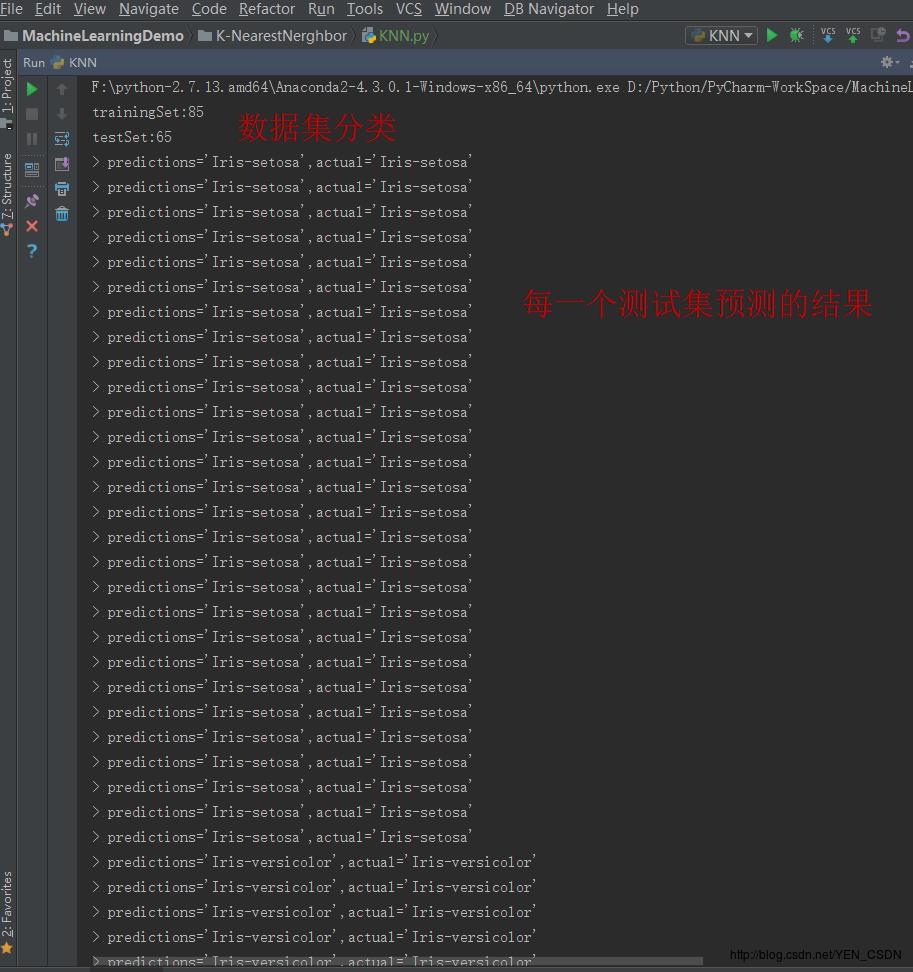
以上是关于机器学习-临近取样(K-Nearest Nerghbor)KNN算法的主要内容,如果未能解决你的问题,请参考以下文章