Oracle 查询技巧与优化 单表查询与排序
Posted 小灯光环
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle 查询技巧与优化 单表查询与排序相关的知识,希望对你有一定的参考价值。
前言
作为一个程序员在写SQL时往往注重结果而忽略了本该应用的技巧和更优性能的选择(之前本人一直也是这样),当公司没有一个DBA(据我了解大多数中小公司都是没有的)为我们做SQL优化时那我们理应将SQL尽可能的写的高效简洁,而不是拿“我是一个java程序员或.NET程序员不擅长这些”为借口,博主本人也是以能写出更高效和更优秀的SQL为目标而构想出本系列blog,通过实际的生产环境数据进行演练并总结学习一些程序员也应当具备的某些DBA的素质,废话不多说,首先开始第一篇学习与总结,第一篇相对比较简单,回顾一下oracle中基本的查询操作和一些函数。
单表查询与排序
首先准备数据,这里的数据是从生产环境DB中备份出来的,即某市考试招生系统的一个基础学生信息表,数据量也不大大概1W+,约50个字段,主要是学生的个人基本信息:

接下来看一下几个较为简单的查询技巧和注意点。
分页排序
如题,从分页语句开始,都知道oracle中是通过rownum来进行分页的,例如我们查询20条到30条之间的数据:
select *
from (select rownum rn, t.*
from (select sid_, stuname_, csrq_ from t_studentinfo) t
where rownum <= 30) s
where s.rn > 20
如上所示,这种分页方式在绝大多数情况下是最高效的,而并非是通过s.rn>20 and s<=30,因为这种不如上面的效率高。接下来如果在分页的基础上添加排序,例如:查询20条到30条之间的数据并按出生日期(csrq_)排序,很简单,我们只需在最里层的查询中加上排序语句即可:
select *
from (select rownum rn, t.*
from (select sid_, stuname_, csrq_
from t_studentinfo
order by csrq_) t
where rownum <= 30) s
where s.rn > 20
查询结果如下图所示:

取随机n条记录排序
如题,很简单,利用oracle提供的随机函数包dbms_random来完成,首选简单了解一下随机数,即dbms_ramdom.value:
select dbms_random.value from dual运行上述SQL即可以返回一个大于0小于1的38位精度的随机数,如下图:

搞清楚了这一点,我们接下来就写一个按随机数排序,例如取学生表的前10条数据并按随机数排序,比如这样写:
select bmh_, stuname_, csrq_
from T_STUDENTINFO
where rownum < 10
order by dbms_random.value;连续运行三次,看一下查询结果:
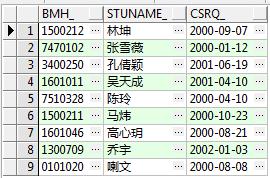


乍一看仿佛没问题,没错,是按随机数排序了,每次运行结果的顺序都不一样,但是请仔细观察,这三次运行结果的学生仿佛是同一批人,只是顺序发生了改变,没错,这才是问题的关键,我们上面的写法是先取学生,后排序,也就是说结果已经提前确定,只是顺序在发生变化,这样的效果并不是我们预期的,我们期望的是在全体学生中随机抽取10人,所以我们需要改写一下我们的SQL,使其先让全体学生排序,再取前10名学生:
select t.*
from (select bmh_, stuname_, csrq_
from T_STUDENTINFO
order by dbms_random.value) t
where rownum < 10这回再连续运行三次看一下查询结果:



这次再仔细观察一下三次的运行结果很明显已经没有一个重复的人了,这也就达到了我们的预期,所以往往SQL的书写顺序也对结果有着决定性的影响,这一点尤为重要。
查询中的条件逻辑
如题,oracle提供了case…when语句使得我们可以在SQL中灵活运用多条件分支来根据值转换为不同的查询结果,例如:
select sid_,
stuname_,
case mzdm_
when 1 then
'汉族'
when 3 then
'满族'
when 4 then
'回族'
when 9 then
'蒙古族'
end as mz
from t_studentinfo
where sid_ in ('36697', '34115', '39590', '30692')
order by mzdm_查询结果如下:

在实际应用中像这种民族code肯定应该关联对应的字典表的键来获取值,这里我们仅仅想演示一下case…when语句的用法,显而易见,以case开头并以end结尾,中间是when条件,并在end关键字之后可以通过as起别名,很方便。
空值转换
如题,又是一个很常用的东西,比如如果某一列查询为空时,我们想将空值替换为我们指定的一个值,这里就可以选择nvl函数或者coalesce函数,均可以达到期望的效果:
select tcsdm_ from t_studentinfo where sid_ in ('33405','29982','28974');
select nvl(tcsdm_,'999') tcsdm from t_studentinfo where sid_ in ('33405','29982','28974');
select coalesce(tcsdm_,'999') tcsdm from t_studentinfo where sid_ in ('33405','29982','28974');运行结果如下图:
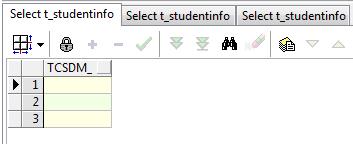


但这里还是要区分一下这两个函数的用法,首先nvl函数只能传2个参数:NVL( string1, replace_with),功能很简单,即:如果string1为NULL,则NVL函数返回replace_with的值,否则返回原来的值。再需要注意一点就是string1与replace_with需要保持同一数据类型,接下来再看一看coalesce函数,它是支持多个参数的,形如:COALESCE(exp1,exp2,...,expn),n>=2,同样它的含义也和nvl区别很大(尽管它们达到的效果相同),即:返回第一个不为空的表达式,如果都为空则返回空值。关于使用哪一个好应该也是显而易见的,即在多参数的情况下coalesce函数明显更具优势,因为它避免了需要嵌套nvl函数,若是只有两个参数的话就无所谓了,正如我们上面的例子,看个人喜好。
模糊查询中的通配符
如题,偶尔在查询中也会遇到这种问题,首先创建一个测试用的视图:
create or replace view v_test_02 as
select '_AAA' as column1 from dual
union all
select '_\\AAA' as column1 from dual
union all
select '_AAAB_' as column1 from dual
union all
select 'QAAA' as column1 from dual;直入主题,需求是我想查询包含字符串“_AAA”的结果,那么条件中的like语句该怎么写呢?我们先试一下这样写看看:
select * from v_test_02 where column1 like '_AAA%';看一下运行结果:

如上图所示,第三行的QAAA这个结果并不是我们预期希望得到的,但是通配符“_”就代表1个字符,所以这个Q自然会被该通配符匹配到,无可厚非,所以为了解决这个问题我们必须引入转义字符的概念,下面是修改后的SQL:
select * from v_test_02 where column1 like '\\_AAA%' escape '\\';此时再看一下查询结果:

这次就对了,所以此处注意一下转义字符以及escape关键字的用法,尽管这种情况很少遇见,但也值得一提。
多字段排序
很有意思的一个问题,这里我们拿学生成绩表的数据来举例更贴切一些,学生成绩表也很简单,包含了学生的考号、各科的文化课成绩以及总分,这里我们只查3列,假设我们的排序条件是这样的:按总分倒序排列并按语文的单科成绩升序排列,那得到的结果会是怎么的呢?首先看一下SQL语句:
select sid_, totalscore_, ywscore_
from T_STUDENTSCORE t
order by 2 desc, 3 asc再看一下运行结果:

如上图所示,首先有一个小地方就是order by后面写的数字,2就代表第2列,3就代表第3列,当然也可以直接跟列名,观察一下查询结果,不难发现依旧是按totalscore_(总分)倒序排列的,但ywscore_(语文单科成绩)似乎排列的有有些混乱,没关系,注意一下图中我用红色格子隔开的列,一个格子一个格子看,不难发现在每个格子内,它确实是升序排列的,这就是多字段排序的结论,即:以写在靠前位置的排序列为基准,将靠后位置的排序列分成若干组,然后每组的数据再单独进行排序。
空值排序
如题,如果按某一列排序,但那一列存在许多空值,它们是如何显示的?在Oracle中空值默认排序在后面,比如学生表中有许多学生没有填出生日期,我们又按出生日期这一列倒序排列,那么可以看到如下结果:


如上图所示,前112名学生的出生日期均为空,从113位学生开始,即年龄最小的学生依次排下去。那么也许你觉得这样并不好,明明为空为什么按大的算呢?我想把空的都放到前面去,很简单,只需要在SQL末尾加上两个关键字(nulls last)即可:


这回可以看到前面并没有空值了,出生日期大的排在最前面,而空的已经排在了11000+的末尾位置了。
总结
简单记录了一下在单表查询与排序中我个人认为值得关注和常用一些点(如果还有好的优化方式或者应当关注的点后面还会陆续添加,也欢迎各位提出毕竟我个人能力有限),部分知识点和灵感来自《Oracle查询优化改写》书中,但我是以程序员的视角而非DBA(也达不到)去描述在项目中遇到的或可能遇到的种种查询语句,并结合实际生产环境的数据进行举例说明,旨在提高我作为程序员应当具备和提高的SQL能力,当然如果有同学能从本系列blog中得到提升那就更好了,希望如此,The End。
以上是关于Oracle 查询技巧与优化 单表查询与排序的主要内容,如果未能解决你的问题,请参考以下文章