Transformer赋能产业级实时分割!NeurIPS 2022顶会成果RTFormer带你一探究竟!
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer赋能产业级实时分割!NeurIPS 2022顶会成果RTFormer带你一探究竟!相关的知识,希望对你有一定的参考价值。

图像分割作为计算机视觉的三大任务之一,是智慧城市、工业制造、自动驾驶等领域的一项关键技术。相比图像分类和目标检测任务,图像分割预测输出目标在像素级别的精细信息,在计算机视觉任务中具有不可替代的作用。

图1 图像分割应用
近些年基于深度学习的图像分割技术飞速发展,使用Transformer结构的语义分割模型取得了令人惊艳的分割精度。但是由于计算量大、推理速度慢等问题,基于Transformer结构的语义分割模型无法很好地应用于实际业务中,所以基于CNN结构的语义分割模型依旧是产业界的主流。实际应用中,对于自动驾驶车端、手机/PC端、机器人等设备,在实时运行情况下获得高精度分割结果是十分必要的。

图2 实时图像分割应用
针对上述问题,百度提出融合CNN和Transformer结构的实时语义分割模型RTFormer。
论文链接如下
https://arxiv.org/abs/2210.07124
RTFormer模型采用双分支架构,创新设计了核心模块RTFormer Block。该模块可以在GPU上高效运行,并且支持跨分支的信息交互。对比实验表明,RTFormer在Cityscapes和CamVid数据集上取得SOTA指标,实现了最佳的精度和速度平衡。此外,PaddleSeg开源RTFormer的官方代码和预训练模型,为大家提供了低门槛、全流程的试用体验。

图3 RTFormer模型综合表现
行动力超强的小伙伴一定早已迫不及待了吧
【传送门链接】
https://github.com/PaddlePaddle/PaddleSeg
记得Star收藏支持

RTFormer目前在develop分支
https://github.com/PaddlePaddle/PaddleSeg/tree/develop/configs/rtformer
为避免在使用过程中遇到问题不能高效解决,快加入官方技术交流群吧!研发同学亲自答疑解惑,快来和小伙伴们一起探索一起进步吧!

RTFormer
模型全面解析
此前大多实时语义分割模型都是完全基于CNN结构,没有引入在很多视觉任务上都表现出强大能力的Transformer结构。其主要原因是Transformer结构在GPU上运行速度不理想,难以满足实时应用的需求。为了使用Transformer结构的全局上下文建模能力进一步提升实时语义分割模型的性能,我们提出了新的实时语义分割模型RTFormer,其主要贡献包括以下几点。
核心模块
RTFormer Block
我们提出了一种GPU上运行友好的Attention Module,并且结合跨分辨率的Cross-Attention构建了双分辨率网络模块RTFormer Block。

图4 GFA模块示意
GPU-Friendly Attention(GFA)继承了External Attention线性计算复杂度的特性,但相比External Attention和其他线性Attention方案,GFA在GPU上具有更好的性价比。
首先,GFA通过使用普通矩阵乘操作替换Multi-head机制中的分组矩阵乘操作,实现了更适合在GPU上运行的Attention计算方式。同时GFA引入了Group Normalization,这使得网络可以保持Multi-head机制中学习多样特征的能力。此外,由于普通矩阵乘更适合GPU推理,GFA可以一定程度扩大参数数量,提升网络容量。
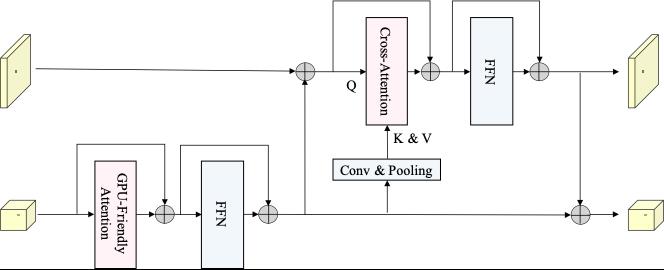
图5 RTFormer Block架构
在GPU-Friendly Attention基础上,我们引入跨分辨率的Cross-Attention构建了双分辨率网络单元RTFormer Block;在低分辨率分支上,使用GFA建模全局上下文;在高分辨率分支上,我们通过跨分辨率的Cross-Attention将低分辨率分支上学习到的全局特征广播到高分辨率分支上,从而使得高分辨率分支获得更强的语义信息。
RTFormer
实时语义分割模型
我们设计了一种将传统CNN Block和RTFormer Block组合的Hybrid模型结构,即RTFormer实时语义分割模型。

图6 RTFormer模型整体架构
RTFormer模型的前3个Stage使用CNN Block,这样可以快速地提取图像的局部信息。在后2个Stage中,RTFormer使用上面提到的RTFormer Block作为基本单元,从而高效地获取语义分割任务关注的全局上下文信息。
最终,RTFormer达到了比纯CNN结构更好的精度速度平衡。我们提供了两种大小的模型RTFormer-slim和RTFormer-base,其具体配置如下表:

对比实验与分析
RTFormer在主流公开数据集Cityscapes和CamVid上达到了SOTA,同时在ADE20K和COCOStuff上验证了通用性。尤其在CamVid上,RTFormer-base在没有Cityscapes预训练情况下达到了mIoU 82.5,取得了显著的提升。

图7 RTFormer在Cityscapes与CamVid数据集上的表现
RTFormer在Cityscapes and CamVid都达到了实时分割SOTA水平。尤其在CamVid上,在没有Cityscapes预训练的前提下,达到了速度190 FPS,精度mIoU 81+的显著效果,明显超越了之前的实时分割方法。
下面是CamVid上的可视化对比图,可以看到RTFormer的全局上下文建模能力相比纯CNN网络结构更强。

图8 RTFormer推理结果细节对比
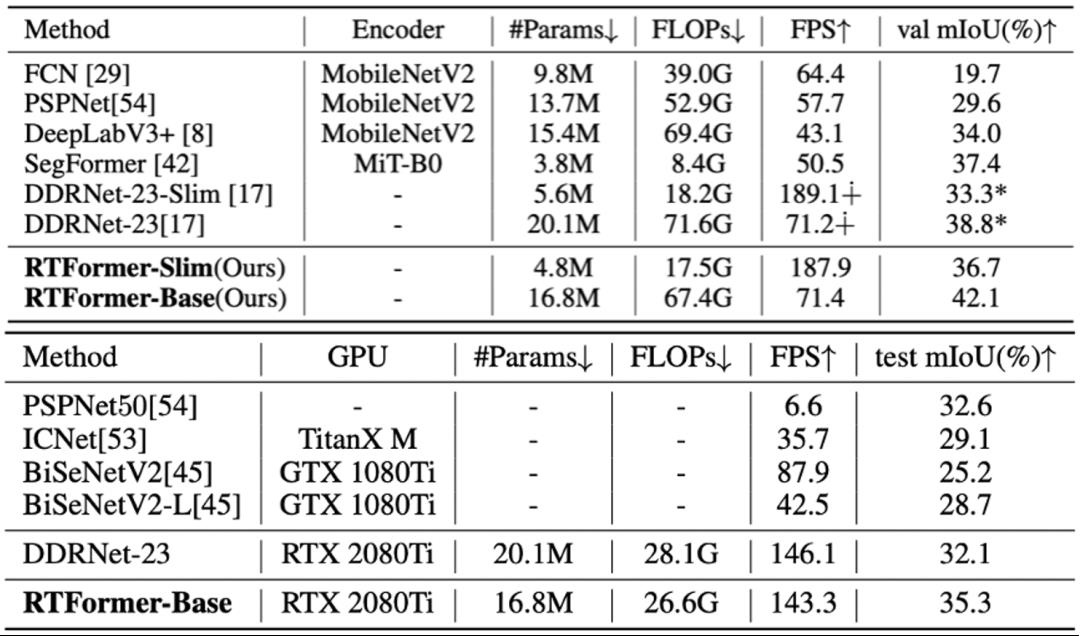
图9 RTFormer在ADE20K与COCOStuff数据集上的表现
从上面两个表中可以看出,RTFormer不仅在城市道路场景表现较好,在更通用的场景上也显示了较好的泛化性能。在ADE20K上,相比纯CNN网络DDRNet和纯Transformer网络SegFormer都有较大的优势。
总结
NeurIPS 2022顶会模型RTFormer有效结合了CNN与Transformer结构的优点,针对GPU运行环境进行了精心的优化,实现了实时分割任务目前的SOTA结果。
有了RTFormer,使用Transformer做实时分割不再是梦,小伙伴们还不行动起来?!快点加入技术交流群吧~
加入
技术交流群
入群福利
获取PaddleSeg团队整理的重磅学习大礼包

引用说明
图1:辅助驾驶图片来源百度地图APP AR导航截图、3D分割数据集来源于MRISpineSeg spine dataset、人像抠图源于百度飞桨内部工作人员、合作伙伴提供质检数据样例、遥感图像源于deepglobe数据集
图2:合作伙伴提供巡检机器人图片及表盘数据
图3-9:源自RTFormer论文
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码报名!关注飞桨公众号,后台回复关键词「WAVE」进入官网社群了解更多峰会详情!

【WAVE SUMMIT+2022报名入口】

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
以上是关于Transformer赋能产业级实时分割!NeurIPS 2022顶会成果RTFormer带你一探究竟!的主要内容,如果未能解决你的问题,请参考以下文章