记一次JAVA使用ProcessBuilder执行Shell任务卡死问题分析
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次JAVA使用ProcessBuilder执行Shell任务卡死问题分析相关的知识,希望对你有一定的参考价值。
背景
最近由于某些原因需要把一些原本 location 在 oss (阿里云云对象存储)上的 hive 数据迁移到cosn(腾讯云对象存储)。目前一直在增量进行同步,在迁移之前需要进行数据的对比。至于对比的方法计划有两种,一种是对比 oss 和 cosn 对应文件下的文件所占磁盘空间大小,即使用 hadoop fs -du -s -h 路径 命令,然后对比相应表 location 的数据大小是否一直即可;另外一种是直接对相应的 hive 表进行 count 操作,表的 location 地址可以通过 hive server2 或者 spark thrift server 获取相应的元数据信息。
生成对比脚本
根据 hive server2 或者 spark thrift server 获取的分区、location、库名、表名等信息生成了数据量和所占磁盘空间的 shell 语句。这里的数据量语句最终生成到一个文件中:count.sh
count=`spark-sql --master yarn --executor-memory 8G --executor-cores 4 --num-executors 2 --driver-memory 4G -e "select count(1) from bi_ods.table1 "`
echo bi_ods.table1:$count >>/Users/scx/work/git/company/utils/count.log
count=`spark-sql --master yarn --executor-memory 8G --executor-cores 4 --num-executors 2 --driver-memory 4G -e "select count(1) from bi_ods.table2 "`
echo bi_ods.table2:$count >>/Users/scx/work/git/company/utils/count.log
count=`spark-sql --master yarn --executor-memory 8G --executor-cores 4 --num-executors 2 --driver-memory 4G -e "select count(1) from bi_ods.table3 where dt >= 20191020 and dt <= 20191027"`
echo bi_ods.table3:$count >>/Users/scx/work/git/company/utils/count.log
...
通过语句可以看出,对于没有分区的表直接进行 count 计算,对于分区的表,只会对比最近的数据(日期自定义)
我们可以通过执行这个 shell 脚本,可以把最终的结果重定向到 count.log中,以 : 隔开,前半本部分是表名,后半部分是数据量,再写个程序解析表和数据量,最后与腾讯云执行的 count 结果进行对比即可。
执行优化
上面生成了 count.sh 后执行呢?直接 bash count.sh吗?是一种方法,除非你的表个数很少,很快就能执行完。要知道,这种方式是串行执行,只有等一个表的 count 语句执行完成之后才能执行下一个语句。我这边共有近2000 张表,如果这样执行的话需要近 30 个小时,太浪费时间了。
所以有没有什么方法优化呢?当然有,记得 Java 里面有调用 shell 程序的类,比如ProcessBuilder 、Runtime。所以我们可以解析 count.sh 脚本,获取所有的表的count 命令和对应的重定向命令,然后使用线程池多线程执行每一个 spark-sql 的 count 语句并且把结果重定向到 count.log
废话不多说,上代码
public class BashExecute
static Random random = new Random();
/**
* 随机种子
*/
static int sed = Integer.MAX_VALUE;
/**
* 已经完成的任务数量
*/
static int finshTask = 0;
/**
* 环境变量
*/
static Map<String, String> customPro = new HashMap<>();
static
Properties properties = System.getProperties();
for (Map.Entry<Object, Object> entry : properties.entrySet())
customPro.put(String.valueOf(entry.getKey()), String.valueOf(entry.getValue()));
customPro.putAll(System.getenv());
public static void execute(String cmds, long num) throws IOException
File tmpFile = createTmpFile(cmds);
/*
//生成脚本日志的正常输出的文件
File logFile = new File(HiveApp.workDir + "/success/" + num + ".log");
if (!logFile.exists())
logFile.createNewFile();
//生成脚本日志的异常输出的文件
File errFile = new File(HiveApp.workDir + "/error/" + num + "_err.log");
if (!errFile.exists())
errFile.createNewFile();
*/
ProcessBuilder builder = new ProcessBuilder("bash", tmpFile.getAbsolutePath())
.directory(new File(HiveApp.workDir));
builder.environment().putAll(customPro);
Process process = null;
try
process = builder.start();
/*
//一个线程读取正常日志信息
new StreamThread(logFile, process.getInputStream()).start();
//一个线程读取异常日志信息
new StreamThread(errFile, process.getErrorStream()).start();
*/
int exitCode = process.waitFor();
if (exitCode != 0)
System.out.println("执行任务异常:" + cmds);
catch (IOException | InterruptedException e)
e.printStackTrace();
finally
if (process != null)
process.destroy();
process = null;
tmpFile.delete();
/**
* 根据要执行的命令创建临时脚本文件
*
* @param cmds shell脚本内容
* @return 创建的文件
*/
private static File createTmpFile(String cmds) throws IOException
File file = new File("/tmp/" + System.currentTimeMillis() + random.nextInt(sed) + ".sh");
if (!file.exists())
if (!file.createNewFile())
throw new RuntimeException("新建临时文件失败" + file.getAbsolutePath());
BufferedWriter writer = new BufferedWriter(new FileWriter(file));
writer.write(cmds);
writer.flush();
writer.close();
return file;
/**
* nohup java -classpath utils-1.0-SNAPSHOT-jar-with-dependencies.jar com.sucx.app.BashExecute /home/hadoop/sucx/count.sh 70 > exe.log &
*
* @param args args[0] count.log lying args[1] 并发个数
* @throws IOException
*/
public static void main(String[] args) throws IOException, InterruptedException
List<String> cmdList;
//默认并行度
int poolSize = 15;
if (args.length == 0)
cmdList = getCmd(HiveApp.countCmd);
else
//count.sh 路径
cmdList = getCmd(args[0]);
if (args.length > 1)
poolSize = Integer.parseInt(args[1]);
int allTask = cmdList.size();
System.out.println("总任务量:" + allTask);
ExecutorService service = Executors.newFixedThreadPool(poolSize);
CountDownLatch latch = new CountDownLatch(allTask);
for (String cmd : cmdList)
service.execute(() ->
try
execute(cmd, allTask - latch.getCount());
catch (IOException e)
e.printStackTrace();
finally
synchronized (BashExecute.class)
finshTask++;
//输出当前进行
System.out.println(LocalDateTime.now() + "已完成:" + finshTask + "/" + allTask + ",百分比为:" + (finshTask * 100 / allTask) + "%");
latch.countDown();
);
latch.await();
System.out.println("任务全部完成");
service.shutdown();
/**
* 根据count.sh的路径来获取所有任务的count语句和重定向语句
*
* @param path count.sh路径
* @return 所有表命令的集合
*/
private static List<String> getCmd(String path) throws IOException
File file = new File(path);
if (!file.exists() || !file.isFile())
throw new RuntimeException("文件不存在");
BufferedReader reader = new BufferedReader(new FileReader(file));
String line;
List<String> cmds = new ArrayList<>();
while ((line = reader.readLine()) != null)
cmds.add("#!/bin/bash" + "\\n" + line + "\\n" + reader.readLine());
reader.close();
return cmds;
/**
* 读取日志的线程
*/
/*static class StreamThread extends Thread
private BufferedWriter writer;
private InputStream inputStream;
public StreamThread(File file, InputStream inputStream) throws IOException
this.writer = new BufferedWriter(new FileWriter(file));
this.inputStream = inputStream;
@Override
public void run()
try (BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, "utf-8")))
String line;
int lineNum = 0;
while ((line = reader.readLine()) != null)
writer.write(line);
writer.newLine();
if (lineNum++ == 10)
writer.flush();
lineNum = 0;
catch (Exception ignored)
*/
代码很简单,main方法接受两个参数,第一个参数为 count.sh 的绝对路径,第二个参数为并发的线程数n
- 解析
count.sh的脚本内容,每两行shell代码为一对(第一行为count的语句,第二行为结果重定向),返回一个List集合cmdList - 新建一个
fixed的线程池,其中核心线程数和最大线程数都为n - 设置
CountDownLatch为任务集合cmdList的大小,遍历cmdList集合,向线程池提交执行的shell代码,然后输出当前的执行进度(为什么同步呢?因为有一个finshTask++;的操作),并释放CountDownLatch锁 CountDownLatch await等待所有任务执行完毕后输出完成的代码,并关闭线程池
其中在执行脚本的 execute 代码中为脚本建了一个临时文件,然后使用 ProcessBuilder 执行该文件,等待脚本结束即可。
卡死问题
代码写好了 就好快快乐乐的分别把 jar 上传到阿里云和腾讯云集群执行了
nohup java -classpath utils-1.0-SNAPSHOT-jar-with-dependencies.jar com.sucx.app.BashExecute /home/hadoop/sucx/count.sh 70 > exe.log &
然后tail -f exe.log 查看实时日志,看着腾讯云的代码欢快的执行,心里有点小兴奋

但是到了阿里云这里好像有点异常啊,等了好久都不动了

最后 yarn 上显示任务失败了
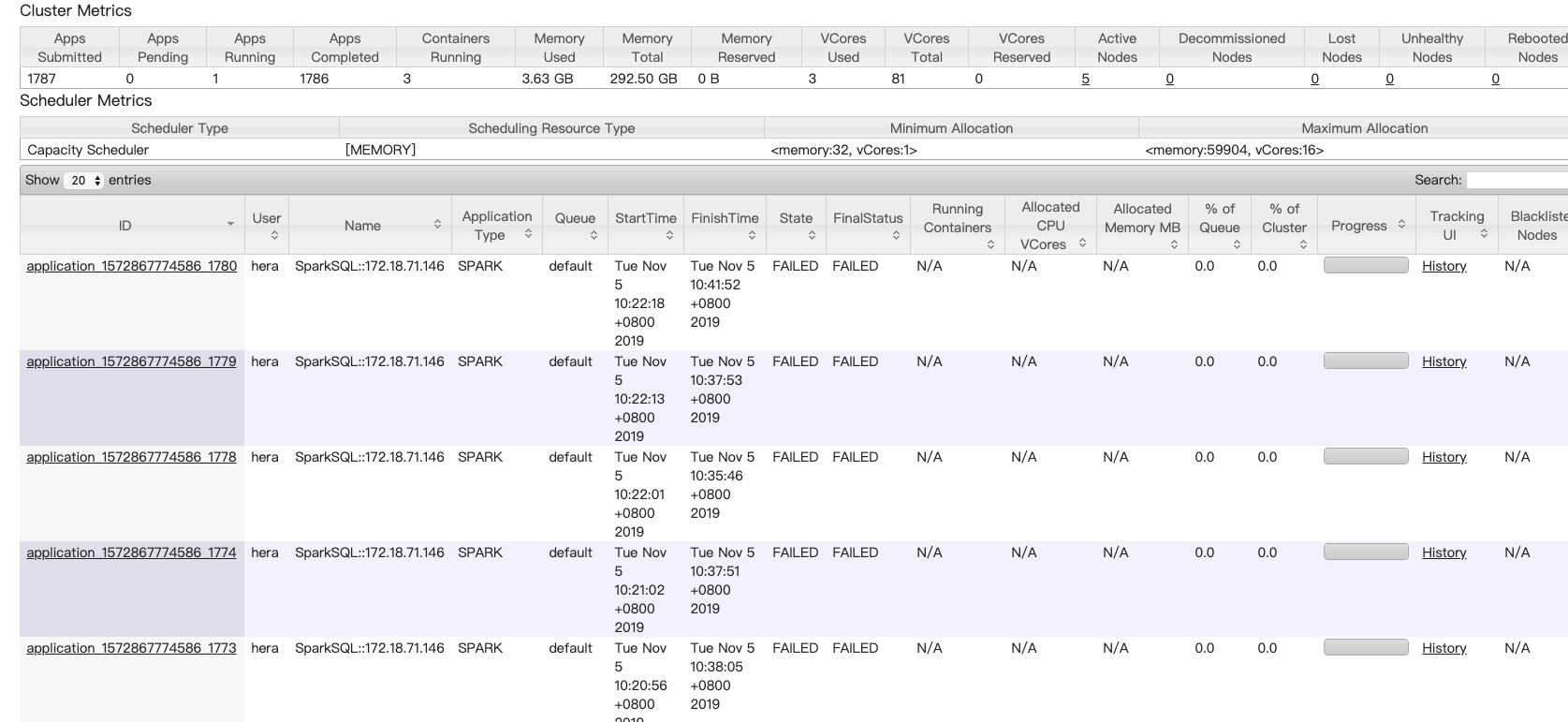
查看 yarn日志发现报错都是一样的,并且单独拉出来在命令行执行都是 ok的
19/11/05 10:32:13 WARN executor.Executor: Issue communicating with driver in heartbeater
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [10 seconds]. This timeout is controlled by spark.executor.heartbeatInterval
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76)
at org.apache.spark.rpc.RpcEndpointRef.askSync(RpcEndpointRef.scala:92)
at org.apache.spark.executor.Executor.org$apache$spark$executor$Executor$$reportHeartBeat(Executor.scala:785)
at org.apache.spark.executor.Executor$$anon$2$$anonfun$run$1.apply$mcV$sp(Executor.scala:814)
at org.apache.spark.executor.Executor$$anon$2$$anonfun$run$1.apply(Executor.scala:814)
at org.apache.spark.executor.Executor$$anon$2$$anonfun$run$1.apply(Executor.scala:814)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1991)
at org.apache.spark.executor.Executor$$anon$2.run(Executor.scala:814)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [10 seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:201)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
... 14 more
但是 java 的进程好像还是卡着不动
"process reaper" #22 daemon prio=10 os_prio=0 tid=0x00007fcefc001680 nid=0x540a runnable [0x00007fcf4d38a000]
java.lang.Thread.State: RUNNABLE
at java.lang.UNIXProcess.waitForProcessExit(Native Method)
at java.lang.UNIXProcess.lambda$initStreams$3(UNIXProcess.java:289)
at java.lang.UNIXProcess$$Lambda$10/889583863.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"process reaper" #21 daemon prio=10 os_prio=0 tid=0x00007fcf08007ab0 nid=0x5407 runnable [0x00007fcf4d3c3000]
java.lang.Thread.State: RUNNABLE
at java.lang.UNIXProcess.waitForProcessExit(Native Method)
at java.lang.UNIXProcess.lambda$initStreams$3(UNIXProcess.java:289)
at java.lang.UNIXProcess$$Lambda$10/889583863.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"pool-1-thread-10" #19 prio=5 os_prio=0 tid=0x00007fcfa418bb20 nid=0x53f8 in Object.wait() [0x00007fcf4d4c4000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000006750be3a8> (a java.lang.UNIXProcess)
at java.lang.Object.wait(Object.java:502)
at java.lang.UNIXProcess.waitFor(UNIXProcess.java:395)
- locked <0x00000006750be3a8> (a java.lang.UNIXProcess)
at com.sucx.app.BashExecute.execute(BashExecute.java:75)
at com.sucx.app.BashExecute.lambda$main$0(BashExecute.java:136)
at com.sucx.app.BashExecute$$Lambda$1/1406718218.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
spark-sql 任务明明失败了,但是我们在执行的进程还没退出?怎么回事,好费解
那么就选择一个线程分析,通过上面堆栈信息选了 process repaer 线程的堆栈信息
"process reaper" #21 daemon prio=10 os_prio=0 tid=0x00007fcf08007ab0 nid=0x5407 runnable [0x00007fcf4d3c3000]
java.lang.Thread.State: RUNNABLE
at java.lang.UNIXProcess.waitForProcessExit(Native Method)
at java.lang.UNIXProcess.lambda$initStreams$3(UNIXProcess.java:289)
at java.lang.UNIXProcess$$Lambda$10/889583863.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
查看 java 源码 java.lang.UNIXProcess.waitForProcessExit是个 native 方法,跳过
private native int waitForProcessExit(int pid);
继续向上分析
以上是关于记一次JAVA使用ProcessBuilder执行Shell任务卡死问题分析的主要内容,如果未能解决你的问题,请参考以下文章
记一次解决cmd中执行java提示"找不到或无法加载主类"的问题
解决方案--java执行cmd命令ProcessBuilder--出错Exception in thread "main" java.io.IOException: Cannot run progra