查找算法及二叉平衡树
Posted WQP_Ya_Ping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找算法及二叉平衡树相关的知识,希望对你有一定的参考价值。
查找的分类:
1.静态查找
2.动态查找
3.哈希查找
1.1顺序查找法
//应用范围:顺序表或线性链表表示的表,表内元素之间无序。
// 在数组arr中查找等于k的元素,若找到,则函数返回该元素的位置,否则返回0
//平均查找长度:ASL = 1/n∑(n-i+1) = ½(n+1)
int SeqSearch(int arr*, int key)
int i ;
for(i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
if(arr[i] == key)
return i;
return 0;
1.2二分(折半)查找法
//前提:顺序存储结构且元素有序排列
//平均查找长度:ASL = log2(n+1) - 1
int BinSearch(int *a,int n,int key)
int low = 0;
int high = n-1;
while(low<high)
int mid = (low+high)/2;
if(a[mid] == key)
return mid;
else if(a[mid]>key)
high = mid-1;
else
low = mid+1;
return -1;
2.1
二叉排序树
定义:
二叉排序树(Binary Sort Tree)又称二叉查找树,是一种特殊的二叉树。
性质:
(1)若左子树不空,则左子树中所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树中所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)中序遍历(LDR)后为递增序列.
插入算法:
1.若二叉树为空。则首先单独生成根结点。
2.若二叉树非空,则将插入值与二叉排序树根结点的关键字进行比较:
a.如果key的值等于根结点的值,则停止插入;
b.如果key的值小于根结点的值,则将结点插入左子树;
c.如果key的值大于根结点的值,则将结点插入右孩子。
注意:新插入的结点总是叶子结点
//时间复杂度仍为O(log2n)
void InsertBST(BSTree **root,ElemType key)
BSTree* s;
if((*root)==NULL)
s = (BSTree*)malloc(sizeof(BSTree)); /*申请新结点*/
s->data = key;
s->lchild = NULL;
s->rchild = NULL;
*root = s;
else if(key>(*root)->data) /*插入右子树*/
InsertBST(&(*root)->rchild,key);
else if(key<(*root)->data) /*插入左子树*/
InsertBST(&(*root)->lchild,key);
查找算法:
首先将待查关键字key与根结点关键字t进行比较,如果:
a.key=t:则返回根结点地址;
b.key
BSTree* SearchBST(BSTree *root,ElemType key)
if(root == NULL)
return NULL;
else if(root->data==key)
return root;
else
if(root->data>key) /*在左子树中继续找*/
return SearchBST(root->lchild,key);
else
return SearchBST(root->rchild,key); /*在右子树中继续找*/
结点删除算法
设在二叉排序树被删除结点是p,其双亲结点为f。(假设结点p是结点f的左孩子)
情况讨论:
(1) 若p为叶结点,则可直接将其删除:f->lchild = NULL;free(p);
(2) 若p结点只有左子树或只有右子树,则可将p的左子树或右子树直接改为其双亲结点f的左子树:f->lchild = p->lchild;free(p);
(3) 若p既有左子树又有右子树,此时有两种处理方法:
方法1:首先找到p结点在中序序列中的直接前驱结点s,然后将p的左子树改为f的左子树,而将p的右子树改为s的右子树:f->lchild = p->lchild;s->rchild = p->rchild;free(p);
方法2(常用):首先找到p结点在中序序列中的**直接前驱结点**s,然后用s结点的值替代p结点的值,再将s结点删除,原s结点的左子树改为s的双亲结点q的右子树:p->data = s->data;q->rchild = s->lchild;free(s);
void Delete(BSTree **root,int key)
BSTree *p = *root;
BSTree *f = NULL;
//查找
while(p)
if(p->data == key)
break;
else if(p->data > key)
f = p;
p = p->lchild;
else
f = p;
p = p->rchild;
if(p!=NULL)
//无左孩子
if(p->lchild==NULL)
if(f==NULL)
*root = p->rchild;
else if(p==f->lchild)
f->lchild = p->rchild;
else if(p==f->rchild)
f->rchild = p->rchild;
free(p);
p = NULL;
//有左孩子
else
BSTree *q = p;
BSTree *s = p->lchild;
while(s->rchild!=NULL)
q = s;
s = s->rchild;
if(s == p->lchild)
q->lchild = s->lchild;
else
q->rchild = s->lchild;
p->data = s->data;
free(s);
s = NULL;
2.2平衡二叉树
定义:
平衡二叉排序树又称为AV树。一棵平衡二叉排序树或者是空树,或者是具有下列性质的二叉排序树
(1) 左子树与右子树的深度之差的绝对值小于等于1;
(2) 左子树和右子树也是平衡二叉排序树。
知识点:
平衡因子(平衡度):结点的平衡因子是结点的左子树的高度减去右子树的高度。
平衡二叉树:每个结点的平衡因子都为 1、-1、0 的二叉排序树。或者说每个结点的左右子树的高度最多差1的二叉排序树。
平衡种类分析:代码较复杂,图奉上
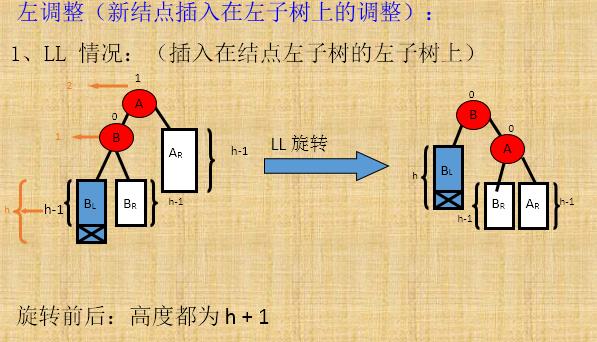

右调整(新结点插入在右子树上进行的调整)
1、RR 情况:(插入在的右子树的右子树上)
处理方法和 LL对称
2、RL 情况:(插入在右子树的左子树上)
处理方法与LR对称
3.1 哈希表
基本思想:首先在元素的关键字k和元素的存储的存储位置p之间建立一个对应关系H,使得p = H(k),H称为哈希函数。
在记录的存储地址和它的关键字之间建立一个确定的对应关系;这样,不经过比较,一次存取就能得到元素。
哈希函数的构造方法:
1.直接定址法:
适合于地址集合的大小 = = 关键字集合的大小
2.数字分析法:
适合于能预先估计出全体关键字的每一位上各种数字出现的频度。
3.平方取中法
4.分段叠加法
适合于关键字的数字位数特别多,且每一位上数字分布大致均匀情况。
5.除留余数法
6.随机数法
H(key)=random(key)
适于关键字长度不等的情况
冲突解决方法:
1.开放定址法
也称再散列法,其基本思想是:当关键字key的初始哈希地址H0=H(key)出现冲突时,以H0为基础,产生另一个地址H1,如果H1仍然冲突,再以H1为基础,产生另一个哈希地址H2……..直到找出一个不冲突的地址,将相应元素存入其中。
2.再哈希法
这种方法可以同时构造多个不同的哈希函数:
Hi=RHi(key) i = 1,2,3,…n
当哈希地址H1=RH1(key) 发生冲突时,再计算H2=RH2(key) ……直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
3.链地址法
方法:将所有关键字为同义词的记录存储在一个单链表中,并用一维数组存放头指针。
适用于经常进行插入和删除的情况。
以上是关于查找算法及二叉平衡树的主要内容,如果未能解决你的问题,请参考以下文章