Java 常用集合类的底层扩容机制
Posted offerNotFound
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 常用集合类的底层扩容机制相关的知识,希望对你有一定的参考价值。
集合里的三大接口:List、Set、Map,其中 List 与 Set 继承于 Collection 接口(Collection 继承于 Iterable 接口)。
List
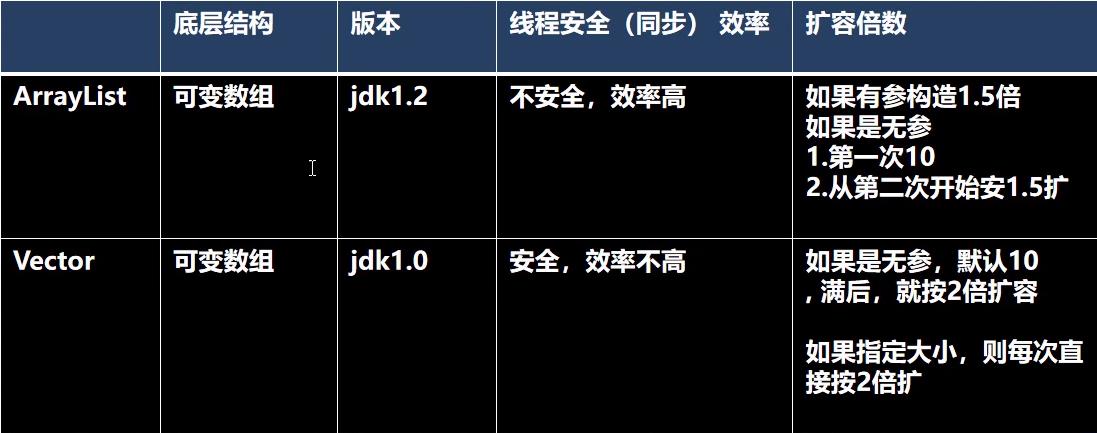
ArrayList
先说结论:
- 它的底层使用的是一个Object类型的数组
elmentData []; - 当创建一个ArrayList时,如果没定义初始容量大小,则
elmentData []为0。当添加了第一个元素进去后,elmentData []默认扩容为10,如需再次扩容,则扩容elmentData []为1.5倍(如 0 -> 10 -> 15 -> 22 -> 33 -> …)。 - 当创建一个ArrayList时,如果定义了初始容量大小,如需再次扩容,则扩容
elmentData []为当前的1.5倍(假设定义为5,则 5 -> 7 -> 10 -> …)。
源码过程:
当调用 ArrayList 的 add 方法时,会先去判断是否需要扩容,然后再去赋值。

通过 ensureCapacityInternal 方法判断是否需要扩容,过程如下:
- 通过调用
calculateCapacity方法去算扩容后最小的容量(即比较是默认的10大,还是你添加的数量大) - 确认了最小容量后,才调用
ensureExplicitCapacity方法来确认是否需要扩容(其中modCount参数是记录当前list被修改的次数,这是为了防止有多个线程去修改它)。当所需容量大于当前 list 容量时,就会调用grow方法去扩容。

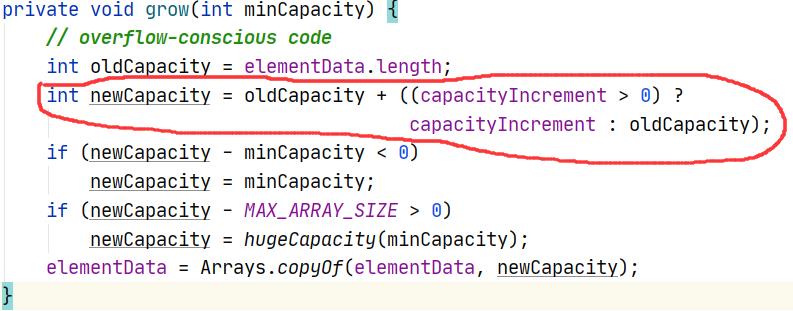
扩容方法,即先记录下 list 的大小,新容量 = list 的大小 + list 的大小/2(即1.5倍)。
但是第一次比较奇特,它的 list 大小为0,新容量算出来也为0。所以当新容量小于所需扩容量时,新容量就会变成所需扩容量。所以第一次扩容是没有使用1.5倍的扩容机制的(仅限是调用了 ArrayList 的无参构造情况下,即未定义初始容量)。
然后再判断新容量是否大于 MAX_ARRAY_SIZE (数组容量最大值),如果不大于就会调用 Arrays 的 copyOf 方法扩容(copyOf 方法会保留原先的数据)。


Vector
Vector 的底层也是一个数组 elmentData [],但相对于 ArrayList 来说,它是线程安全的,它的每个操作方法都是加了锁的。如果在开发中需要保证线程安全,则可以使用 Vector。
扩容机制也与 ArrayList 大致相同。唯一需要注意的一点是,Vector 的扩容量是2倍。
Set
HashSet
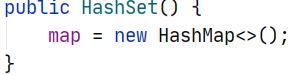
HashSet 的底层其实是 HashMap(数组+链表+红黑树),它可以存放空值(但只能有一个)。
HashSet 添加元素的机制,先说结论:
- 当添加一个元素时,会先去得到这个元素的hash值,然后通过这个hash值转换成一个索引值(即元素存放的位置)。
- 当确定了索引值后,如果该位置没有元素,则直接放入;如果有元素,就调用
equals方法比较索引处的链表里的元素与要添加的元素(是根据元素类型来确定比较的什么),如果相同就放弃添加,如果不同放到该位置处链表的最后一个元素的后面(即 old.next = new)。 - 数组的扩容倍数是2倍(16 -> 32 -> 64),加载因子默认为0.75,临界值为 (数组大小 * 加载因子)。
- 当某索引处的元素链表长度到达8时(默认为8),并且当前数组大小达到64时(默认为64),该索引处就会由链表转化为红黑树。
源码过程
-
当执行
add方法时,它会去执行 map 的put方法。
 而
而 -
map 的
put方法需要 key-value 对,key就是要添加的元素,但 value 呢?其实 value
就是上图中的PRESENT,是一个人空对象,起到一个占位的作用。

-
进入到
put方法后,首先看一下hash(key)这个方法是如何计算出索引值的,算法如下(这里算出来的值不是 hashCode):

-
下面进入最难的
putVal方法(源码过长,对照着源码来看)。 -
第一次放入元素时,由于是此时数组还是空的,所以会进入
resize方法,这个方法就会默认让其扩容至16(DEFAULT_INITIAL_CAPACITY),同时还会计算一个临界值。
其中DEFAULT_LOAD_FACTOR是一个加载因子(默认为0.75),其作用是:假如这个数组大小为16,按理说应该16个空间都用完了才去扩容是最合理的,但实际上设计者设计了一个临界值(此时为16 * 0.75=12),也就是说当你使用量达到了临界值时,就会开始扩容了,这个加载因子就起了个缓冲的作用。(注意:到达临界值是指添加的元素个数到达临界值就去扩容,而不是指数组索引达到的12才去扩容)
那为什么会这样设计呢?因为设计者担心如果你此时使用了12个空间,还剩4个空间了,这时突然有很多线程往这4个空间里添加元素,而你又没有扩容,这时就会卡住或阻塞。 -
接下来会根据Key来得到hash去计算应该放到table表的哪个索引位置,并且把这个索引位置赋值给变量p。
-
然后判断这个p位置处是否为空。
-
如果p为空,表示当前位置还未存放过元素,那么就创建一个Node(key-value,value就是上述的
PRESENT),然后直接把元素放在这 -
如果p不为空,这时就会有三种情况:
①如果p位置对应的链表的第一个元素和准备添加的元素的 hash 值一样,并且满足准备加入的元素和 p位置处已有的元素是同一个对象或者两者不是同一个对象但调用equals方法为 true,那这个元素就会被视为是重复的,无法添加。情况①不满足就看情况②
②判断p位置处是不是转化成红黑树了,如果是的话,就调用putTreeVal方法去判断p位置处已有元素和要添加的元素是否相同(这是红黑树的算法,究极复杂)。如果不是一颗红黑树,就看情况③
③既然要添加的元素与p位置处链表的第一个元素不相同,那么就用for循环来判断p位置处链表接下来的元素是否与之相同。但凡有一个相同就无法添加,不相同就添加到该链表的最后一个元素的后面(注意:当元素添加至链表后,会立即判断该链表长度是否达到了8,并且数组大小达到了64。如果两个都达到了,就会把该链表转化成红黑树;如果数组大小没达到64,那么就会先扩容数组大小至64再树化,在没至64前,继续挂在该链表的屁股后面)。
LinkedHashSet
它的底层是LinkedHashMap,维护的是一个数组 + 双向链表(有头结点head 和尾节点tail,每个节点有 before 和 after 属性)。相比于HashSet。
国际惯例,LinkedHashSet 添加元素的机制,先说结论:
- 添加第一个元素时,先求hash值来确定索引位置,然后将添加的元素放入双向链表中(如果该元素已经存在,则放弃添加,与HashSet一样)。
- 它的存储顺序与取出顺序是一致的。
- 默认第一次扩容也是16。
- 它节点的 before 会指向上一个元素,after 会指向下一个元素。
源码机制与HashSet一样,同样是调用map的put方法。
Map
HashMap
它的 key 也可以为空,但只能有一个,并且常用String类型来作为Map的key。一些概念:
K-V键值对 是存放在一个HashMap$Node中的K-V键值对 为了方便遍历,它还会把HashMap$Node封装成一个Entry(这个Node实现了Entry),再把这个Entry放进EntrySet集合,因为Map.Entry类型里提供了getKey()和getValue()方法,可以让你单独取出Key或者Value。

- 使用
EntrySet遍历Map时,需要先将EntrySet转成Entry,再将Entry强转为Map.Entry。
扩容机制在 HashSet 处记录过。
HashTable
它的底层是数组(HashTable$Entry[ ]),初始化大小为11,加载因子同样是0.75。当达到临界值时调用rehash()方法扩容,扩容大小为(原大小 * 2 + 1);

以上是关于Java 常用集合类的底层扩容机制的主要内容,如果未能解决你的问题,请参考以下文章