CDH中的Solr中文分词
Posted wingooom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH中的Solr中文分词相关的知识,希望对你有一定的参考价值。
下载
https://code.google.com/archive/p/ik-analyzer/downloads
我的solr版本是4.x,根据标签下载文件
IK Analyzer 2012FF_hf1.zip
jar包
解压出jar包:
IKAnalyzer2012FF_u1.jar
在CDH中,正确的jar包目录应该是
/opt/cloudera/parcels/CDH-5.4.7-1.cdh5.4.7.p0.3/lib/solr/webapps/solr/WEB-INF/lib
在CM页面上重启solr服务。
更新schema.xml
在core的schema中加入ik分词类型,如下代码需要放在< types>…< /types>中,推荐放在最后
<!--ik analyzer Chinese -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>在core的schema中应用我们新定义的类型,如:
<field name=”id” type=”string” indexed=”true” stored=”true” required=”true” />
<field name=”title” type=”text_ik” indexed=”true” stored=”true” termVectors=”true”/>
<field name=”content” type=”text_ik” indexed=”false” stored=”true”/>
<field name=”create_time” type=”date” indexed=”true” stored=”true”/>
<field name=”update_time” type=”date” indexed=”true” stored=”true”/>当我们创建Collection完成后,如果需要修改schema.xml文件重新配置需要索引的字段可以按如下操作:
- 如果是修改原有schema.xml中字段值,而在solr中已经插入了索引数据,那么我们需要清空索引数据集,清空数据集可以通过solr API来完成。
- 如果是在原有schema.xml中加入新的索引字段,那么可以跳过1,直接执行:
$ solrctl instancedir --update collection_test_1 $HOME/solr_configs
$ solrctl collection --reload collection_test_1测试
在solr界面进行测试
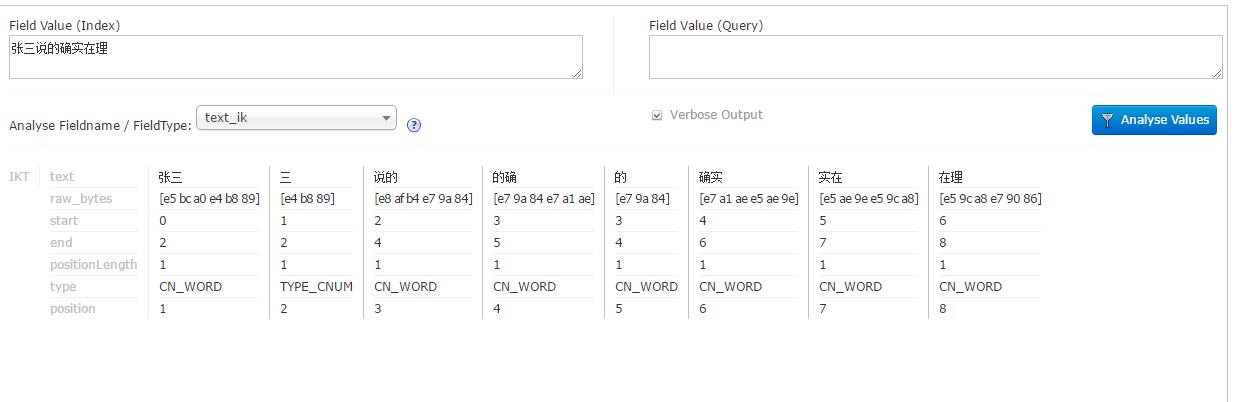
这里默认的是细粒度划分。
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如:
张三说的确实在理
智能分词的结果是:
张三 | 说的 | 确实 | 在理
最细粒度分词结果:
张三 | 三 | 说的 | 的确 | 的 | 确实 | 实在 | 在理
修改配置文件schema.xml
<field name="content" type="text_ik" indexed="true" stored="true"/>
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>查询采用IK自己的最大分词法,索引则采用它的细粒度分词法.
以下部分为摘抄,还没作实际测试。暂存为笔记。待以后留用。
默认分词器进行最细粒度切分。IKAnalyzer支持通过配置IKAnalyzer.cfg.xml 文件来扩充您的与有词典以及停止词典(过滤词典),只需把IKAnalyzer.cfg.xml文件放入class目录下面,指定自己的词典mydic.dic.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">/mydict.dic;
/com/mycompany/dic/mydict2.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">/ext_stopword.dic</entry>
</properties>事实上前面的FieldType配置其实存在问题,根据目前最新的IK版本IK Analyzer 2012FF_hf1.zip,索引时使用最细粒度分词,查询时最大分词(智能分词)实际上是不生效的。
据作者linliangyi说,在2012FF_hf1这个版本中已经修复,经测试还是没用,详情请看此贴。
解决办法:重新实现IKAnalyzerSolrFactory
package org.wltea.analyzer.lucene;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
//lucene:4.8之前的版本
//import org.apache.lucene.util.AttributeSource.AttributeFactory;
//lucene:4.9
import org.apache.lucene.util.AttributeFactory;
public class IKAnalyzerSolrFactory extends TokenizerFactory
private boolean useSmart;
public boolean useSmart()
return useSmart;
public void setUseSmart(boolean useSmart)
this.useSmart = useSmart;
public IKAnalyzerSolrFactory(Map<String,String> args)
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
@Override
public Tokenizer create(AttributeFactory factory, Reader input)
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
重新编译后更新jar文件,更新schema.xml文件:
<fieldType name="text_ik" class="solr.TextField" >
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analyzer>
</fieldType>solr创建索引
参考
http://www.importnew.com/12918.html
以上是关于CDH中的Solr中文分词的主要内容,如果未能解决你的问题,请参考以下文章