Apache Flink:流处理中Window的概念
Posted u4110122855
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink:流处理中Window的概念相关的知识,希望对你有一定的参考价值。
Apache Flink–DataStream–Window
什么是Window?有哪些用途?
下面我们结合一个现实的例子来说明。
我们先提出一个问题:统计经过某红绿灯的汽车数量之和?
假设在一个红绿灯处,我们每隔15秒统计一次通过此红绿灯的汽车数量,如下图: 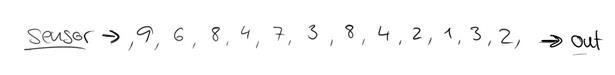
可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔15秒,我们都将与上一次的结果进行sum操作(滑动聚合),如下: 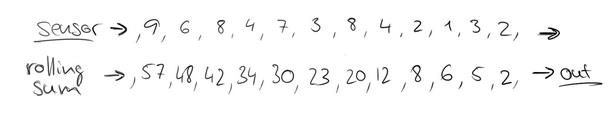
这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。
因此,我们需要换一个问题的提法:每分钟经过某红绿灯的汽车数量之和?
这个问题,就相当于一个定义了一个Window(窗口),window的界限是1分钟,且每分钟内的数据互不干扰,因此也可以称为翻滚(不重合)窗口,如下图: 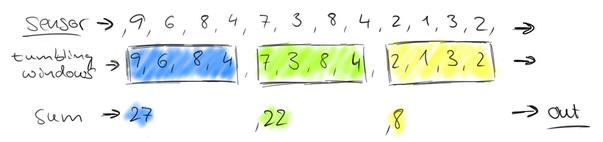
第一分钟的数量为8,第二分钟是22,第三分钟是27。。。这样,1个小时内会有60个window。
再考虑一种情况,每30秒统计一次过去1分钟的汽车数量之和: 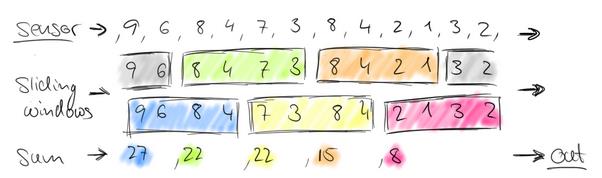
此时,window出现了重合。这样,1个小时内会有120个window。
扩展一下,我们可以在某个地区,收集每一个红绿灯处汽车经过的数量,然后每个红绿灯处都做一次基于1分钟的window统计,即并行处理: 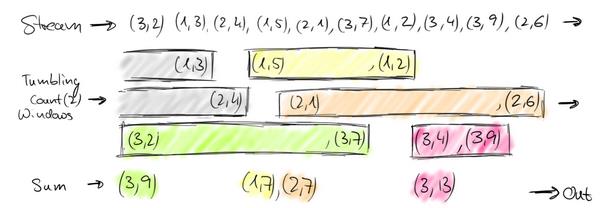
通常来讲,Window就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window又可以分为基于时间(Time-based)的window以及基于数量(Count-based)的window。
Flink DataStream API提供了Time和Count的window,同时增加了基于Session的window。同时,由于某些特殊的需要,DataStream API也提供了定制化的window操作,供用户自定义window。
下面,主要介绍Time-Based window以及Count-Based window,以及自定义的window操作,Session-Based Window操作将会在后续的文章中讲到。
1、Time-Based Window
1.1、Tumbling window(翻滚)
此处的window要在keyed Stream上应用window操作,当输入1个参数时,代表Tumbling window操作,每分钟统计一次,此处用scala语言实现:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum(1) 1.2、Sliding window(滑动)
当输入2个参数时,代表滑动窗口,每隔30秒统计过去1分钟的数量:
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding time window of 1 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1)Note:Flink中的Time概念共有3个,即Processing Time(wall clock),Event Time以及Ingestion Time,我会在后续的文章中讲到。(国内目前wuchong以及Vinoyang都有讲过).
2、Count-Based Window
2.1、Tumbling Window
和Time-Based一样,Count-based window同样支持翻滚与滑动窗口,即在Keyed Stream上,统计每100个元素的数量之和:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the carCnt sum
.sum(1)2.2、Sliding Window
每10个元素统计过去100个元素的数量之和:
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)3、Advanced Window(自定义window)
自定义的Window需要指定3个function。
3.1、Window Assigner:负责将元素分配到不同的window。
// create windowed stream using a WindowAssigner
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed
.window(myAssigner: WindowAssigner[IN, WINDOW])WindowAPI提供了自定义的WindowAssigner接口,我们可以实现WindowAssigner的public abstract Collection<W> assignWindows(T element, long timestamp)方法。同时,对于基于Count的window而言,默认采用了GlobalWindow的window assigner,例如:
keyValue.window(GlobalWindows.create())3.2、Trigger
Trigger即触发器,定义何时或什么情况下Fire一个window。
我们可以复写一个trigger方法来替换WindowAssigner中的trigger,例如:
// override the default trigger of the WindowAssigner
windowed = windowed
.trigger(myTrigger: Trigger[IN, WINDOW])对于CountWindow,我们可以直接使用已经定义好的Trigger:CountTrigger
trigger(CountTrigger.of(2))3.3、Evictor(可选)
驱逐者,即保留上一window留下的某些元素。
// specify an optional evictor
windowed = windowed
.evictor(myEvictor: Evictor[IN, WINDOW])Note:最简单的情况,如果业务不是特别复杂,仅仅是基于Time和Count,我们其实可以用系统定义好的WindowAssigner以及Trigger和Evictor来实现不同的组合:
例如:基于Event Time,每5秒内的数据为界,以每秒的滑动窗口速度进行operator操作,但是,当且仅当5秒内的元素数达到100时,才触发窗口,触发时保留上个窗口的10个元素。
keyedStream
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(1))
.trigger(CountTrigger.of(100))
.evictor(CountEvictor.of(10));val countWindowWithoutPurge = keyValue.window(GlobalWindows.create()).
trigger(CountTrigger.of(2))最后,给出一个完整的例子,说明Window的用法:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger, PurgingTrigger
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
object Window
def main(args: Array[String])
// set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.socketTextStream("localhost",9000)
val values = source.flatMap(value => value.split("\\\\s+")).map(value => (value,1))
val keyValue = values.keyBy(0)
// define the count window without purge
val countWindowWithoutPurge = keyValue.window(GlobalWindows.create()).
trigger(CountTrigger.of(2))
val countWindowWithPurge = keyValue.window(GlobalWindows.create()).
trigger(PurgingTrigger.of(CountTrigger.of[GlobalWindow](2)))
countWindowWithoutPurge.sum(1).print()
countWindowWithPurge.sum(1).print()
env.execute()
// execute program
env.execute("Flink Scala API Skeleton")
1]: http://flink.apache.org/news/2015/12/04/Introducing-windows.html
3]: http://blog.madhukaraphatak.com/introduction-to-flink-streaming-part-6/
4]: https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
5]: http://data-artisans.com/how-apache-flink-enables-new-streaming-applications-part-1/
6]: http://dataartisans.github.io/flink-training/exercises/popularPlaces.html
以上是关于Apache Flink:流处理中Window的概念的主要内容,如果未能解决你的问题,请参考以下文章
Apache 流框架 Flink,Spark Streaming,Storm对比分析 - Part1
官宣|Apache Flink 1.13.0 正式发布,流处理应用更加简单高效!