为什么Map桶中个数超过8才转为红黑树
Posted 帅性而为1号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么Map桶中个数超过8才转为红黑树相关的知识,希望对你有一定的参考价值。
被问及的一个问题,应该不少人看到这个问题都会一面懵逼。因为,大部分的文章都是分析链表是怎么转换成红黑树的,但是并没有说明为什么当链表长度为8的时候才做转换动作。笔者第一反应也是一样,只能初略的猜测是因为时间和空间的权衡。
要弄明白这个问题,我们首先要明白为什么要转换,这个问题比较简单,因为Map中桶的元素初始化是链表保存的,其查找性能是O(n),而树结构能将查找性能提升到O(log(n))。当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。至于为什么阈值是8,我想,去源码中找寻答案应该是最可靠的途径。
8这个阈值定义在HashMap中,如下所示,这段注释只说明了8是bin(bin就是bucket,即HashMap中hashCode值一样的元素保存的地方)从链表转成树的阈值,但是并没有说明为什么是8:

在HashMap中有一段Implementation notes,笔者摘录了几段重要的描述,第一段如下所示,大概含义是当bin变得很大的时候,就会被转换成TreeNodes中的bin,其结构和TreeMap相似,也就是红黑树:

继续往下看,TreeNodes占用空间是普通Nodes的两倍,所以只有当bin包含足够多的节点时才会转成TreeNodes,而是否足够多就是由TREEIFY_THRESHOLD的值决定的。当bin中节点数变少时,又会转成普通的bin。并且我们查看源码的时候发现,链表长度达到8就转成红黑树,当长度降到6就转成普通bin。
这样就解析了为什么不是一开始就将其转换为TreeNodes,而是需要一定节点数才转为TreeNodes,说白了就是trade-off,空间和时间的权衡:
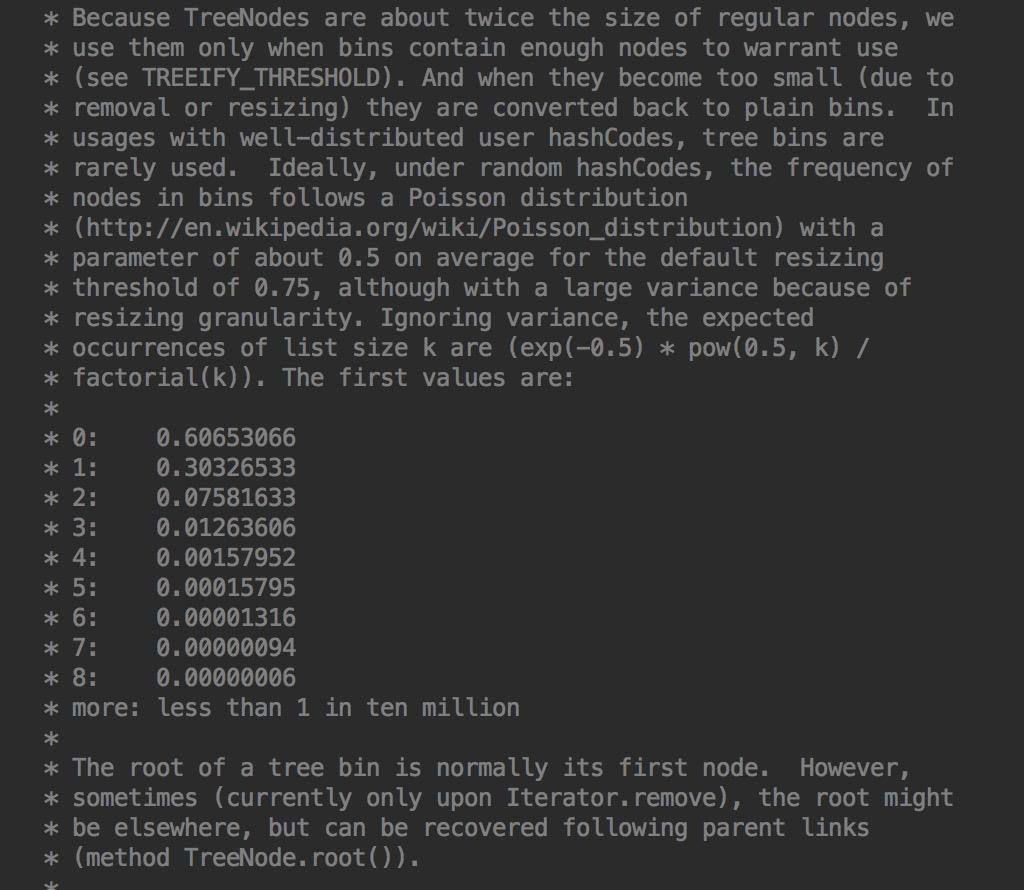
这段内容还说到:当hashCode离散性很好的时候,树型bin用到的概率非常小,因为数据均匀分布在每个bin中,几乎不会有bin中链表长度会达到阈值。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,不是拍拍屁股决定的,而是根据概率统计决定的。由此可见,发展30年的Java每一项改动和优化都是非常严谨和科学的。
以上是关于为什么Map桶中个数超过8才转为红黑树的主要内容,如果未能解决你的问题,请参考以下文章